WDL 是 Workflow Description Language的缩写,有时也写作 Workflow Definition Language,是美国 Broad Institute 推出的工作流描述语言。从开发者及开发者赋予的名字中,我们就能看出WDL是一个面向生物信息/基因组学领域的专业的工具。
经过几年的发展,WDL 已经是生信行业广泛接受的一种工作流标准,具有下面的优势:
Human-readable
WDL 作为一种为工作流领域定制的语言,和 Shell、Python 等通用的脚本语言相比,没有过多复杂的概念,对使用者的计算机技能要求不高,对于生信用户容易上手。Portable Workflow
WDL 可以在多个平台执行,比如本地服务器、SGE 集群,云计算平台等,可以做到一次编写多处执行。Standard
作为GA4GH支持的工作流描述语言之一,已经得到了众多大厂和行业协会的支持,形成了比较完善的生态。
在GATK4的best practice中,不再像以前那样给出每个步骤对应的代码,而是直接给出了官方使用的pipeline。这些pipeline采用WDL进行编写。
参考文档
在学习编写 WDL 的过程中,可以参考 Broad 官方的一些 GATK工作流 借鉴和学习 WDL 的用法。
WDL架构结构组件
WDL是一种流程编写语言,没有太多复杂的逻辑和语法,入门简单。首先看一个hello world的例子
1 | workflow myWorkflow { |
对于一个WDL脚本而言,有以下5个重要的核心结构
- workflow:工作流定义
- task:工作流包含的任务定义
- call:调用或触发工作流里面的 task 执行
- command:task在计算节点上要执行的命令行
- runtime:task在计算节点上的运行时参数,包括 CPU、内存、docker 镜像等
- output:task 或 workflow 的输出定义
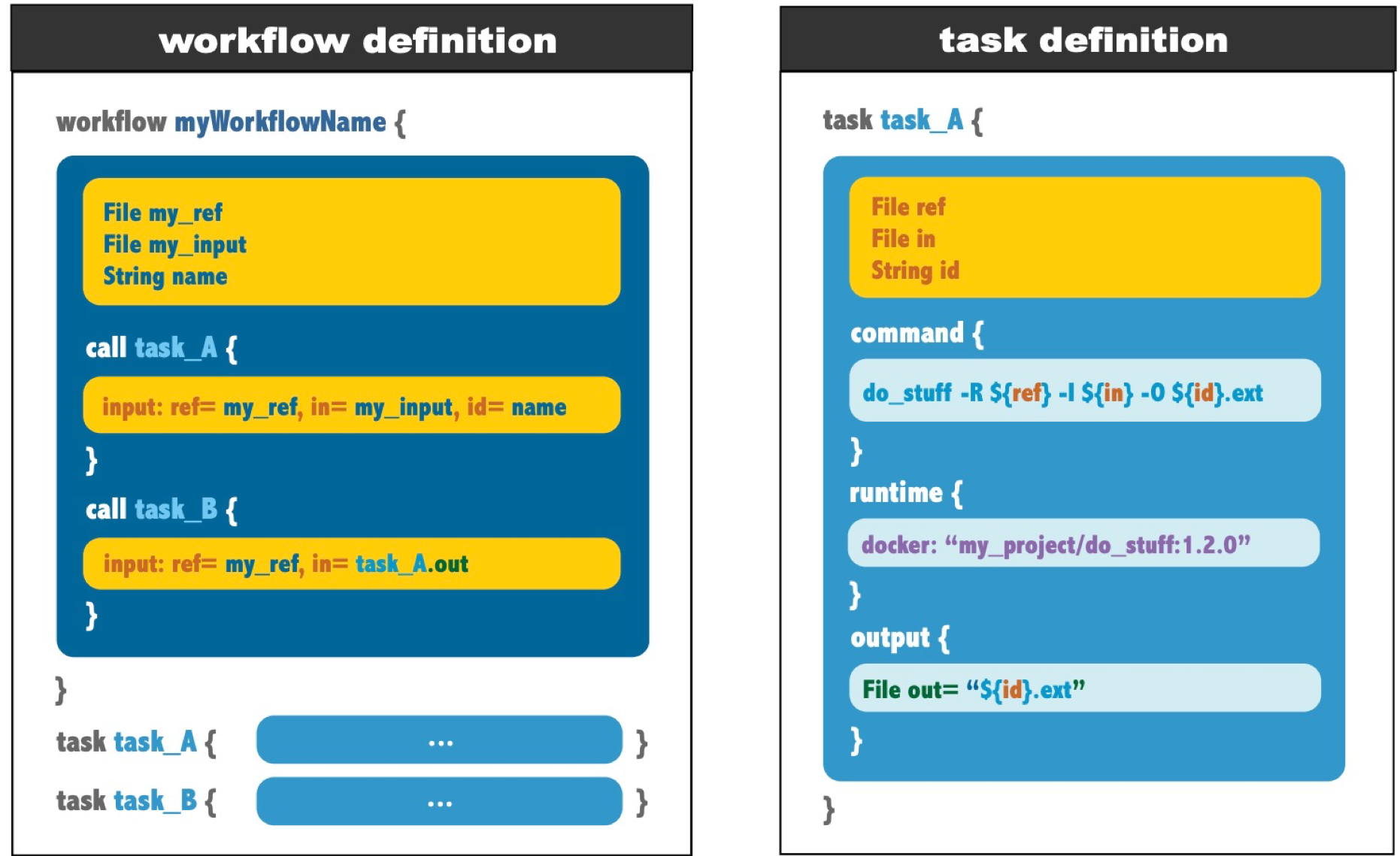
1. workflow (call )
每个脚本包含1个 workflow ,定义了一个可执行的流程,它由 call 调用的一系列 task 组成的。每个 task 在 workflow 代码块之外单独定义。
task可以是一个模块化的一系列命令(这个特性非常重要,特别是在容器化环境下,有机会详细说),它可以复用。由call 语句调用在workflow block里面,task本身定义在外围,它可以import,强烈建议这样书写增加可维护性,这里先不展开说了。task调用的顺序及书写顺序不决定流程执行task的顺序,但撰写过程应该尽可能保持整个流程的可读性。
2. task (command & output )
task是一个WDL中一个基本的任务模块,可以在不同的 workflow 中通过 call 进行调用。一个task模块至少包含两部分 (command & output )。除了两个必须模块外,还有 runtime可以用于指定任务运行所需的资源、环境,还可以进行变量的定义。
- task 代表任务,读取输入文件,执行相应命令,然后输出;
- command 中对应的就是执行的命令,比如一条具体的gatk的命令;
- output 指定task的输出值。
- runtime task在计算节点上的运行时参数,包括 CPU、内存、docker 镜像等
可以将task理解为编程语言中的函数,每个函数读取输入的参数,执行代码,然后返回,command对应执行的具体代码,output对应返回值。在wdl中,DAG关系就是由output来确认的。
3. glob
glob 是指对 workflow 或 task 的输出,支持通配符匹配。1
2
3output {
Array[File] output_bams = glob("*.bam")
}
- 使用场景:
输出文件有多个,且文件名不确定 - 使用方法:
采用 glob 表达式,用 array 方式存储多个输出文件 - 价值:
输出结果支持通配符匹配,简化 WDL 编写,采用数组方式,方便并发处理
4. Call caching
Call caching 是 Cromwell 的一个很有用的高级特性,通过 task 的复用,帮助客户节省时间,节省成本。
- 适用场景:
输入和运行环境不变的情况下,复用之前 task 的运行结果 - 命中条件:
输入 + 运行时参数相同 - 价值:
复用之前的执行结果,节省时间,节省成本
5.批量计算 runtime
用于配置任务运行时的相关参数。
使用批量计算作为后端时,主要的 runtime 参数有:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26cluster:
计算集群环境
支持serverless 模式和固定集群模式
mounts:
挂载设置
支持 OSS 和 NAS
docker:
容器镜像地址
支持容器镜像服务
simg:
容器镜像文件
支持singularity 镜像
systemDisk:
系统盘设置
包括磁盘类型和磁盘大小
dataDisk:
数据盘设置
包括磁盘类型、磁盘大小和挂载点
memory:
所需的任务内存
cpu:
所需的计算核心数目
timeout:
作业超时时间
maxRetries:
指令允许定义在发生故障时可以重新提交流程实例的最大次数。
具体的参数解释及填写方法,请参考 Cromwell 官方文档
除此之外,还有一些其他的概念
- runtime
- parameter_meta
- meta
从官方版本45开始,Cromwell 使用批量计算作为后端,支持 glob 和 Call caching 两个高级特性。
6. 变量的定义
对应WDL的结构,变量也分为两层,task层和workflow层。
最基本的变量有两个,一种是 File,对应文件,一种是String对应的是字符。task层的变量可以引用workflow层的变量,也可以直接传参。下面我举个例子来说明一下:
示例
1 | workflow helloHaplotypeCaller { |
在workflow层,我们定义了两个变量,Ref和Sample,在call haplotypeCaller的过程中,我们用input语句将它们传给了task层的RefFasta和sampleName,这样的话,提升了传参的复用——只用给Ref和Sample两个变量传参,多个task都可以引用它们。而其它的变量则可以由输入文件一起传入。
变量的类型,主要有以下几种:
- String
- Int
- Float
- File
- Boolean
- Array[T]
- Map[K, V]
- Pair[X, Y]
- Object
关于每一种变量的使用,以及 WDL 的更多使用技巧,请参考官方规范文档。
以上就是关于WDL的基本架构与变量的内容,一个最基本的WDL文件就可以完成了,接来就要准备对应的输入与执行了,我们会继续介绍。
WDL架构执行逻辑
task 如何组装成 workflow
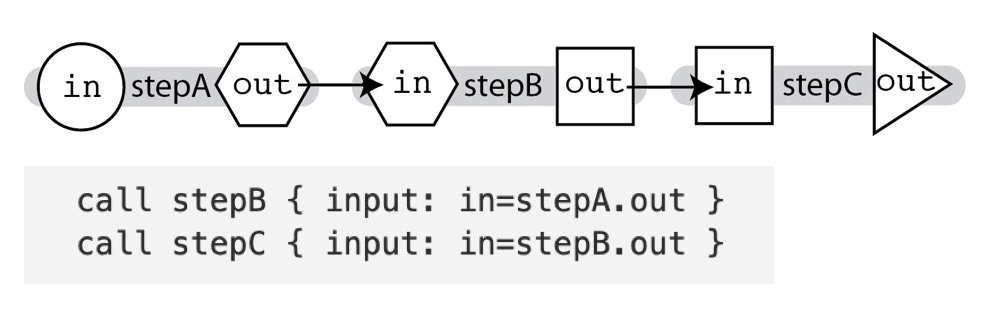
一个 workflow 里面包含多个 task,task 之前的串行或并行关系如何表达呢?主要有下面三种情况:
Linear Chaining
Multi-input / Multi-output
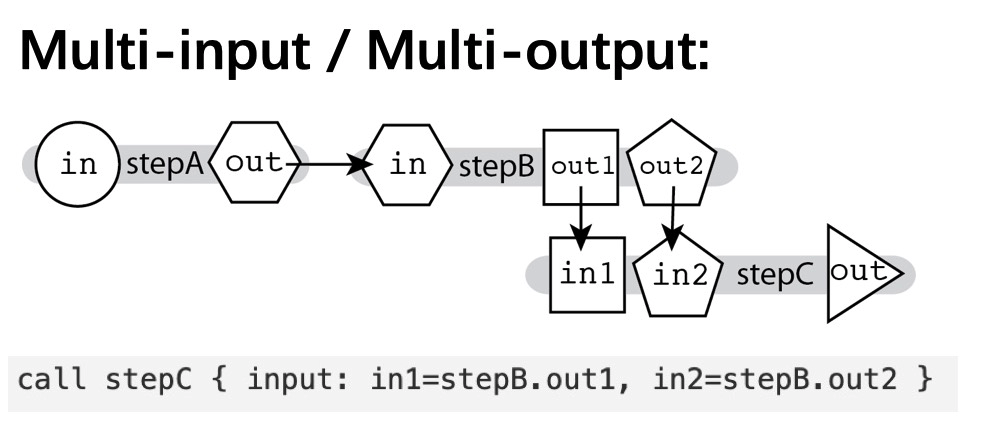
第二种是多输入多输出的场景,一个 task 可以定义多个输入和输出,比如上面的例子,task B 有两个输出,作为 taskC 的输入。Scatter-Gather Parallelism
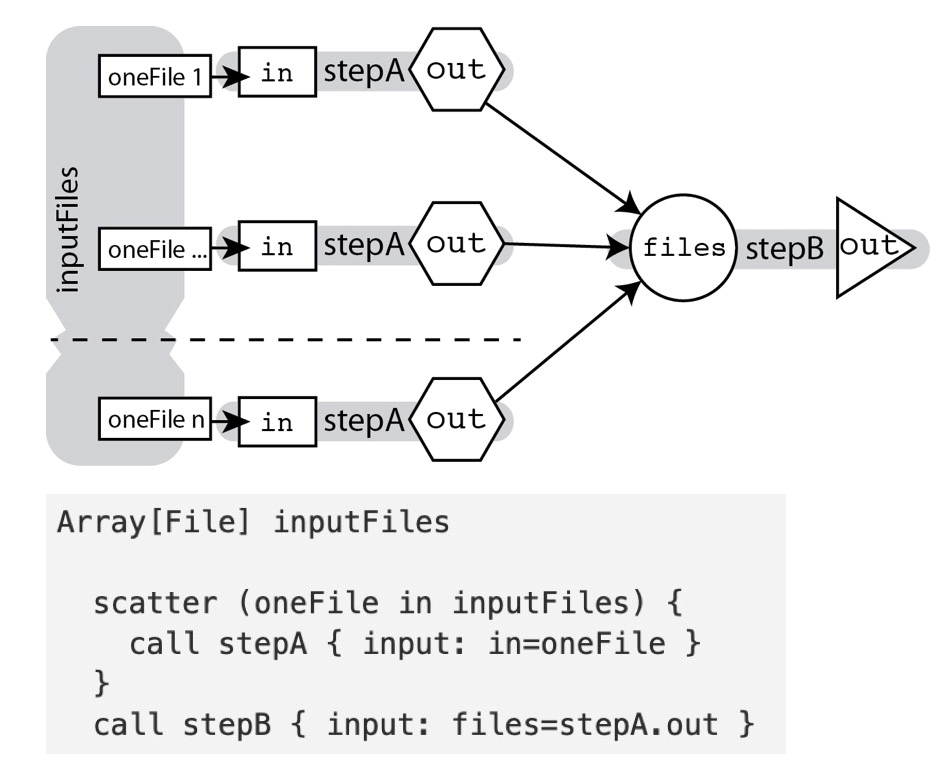
第三种场景是用于 task 的并发执行。如果一个 task 有多个样本需要并发处理,可以使用数组的方式将样本传入,然后使用 scatter 并发的处理每个样本,每个执行的单元称为一个 shard。所有的 shard 执行完成,则当前 task 执行完成,所有 shard 的输出,又作为一个数组,可以传递到下一个 task 处理。
输入参数如何传入
配置文件生成与填写
workflow 的输入,比如基因样本的存储位置、计算软件的命令行参数、计算节点的资源配置等,可以通过 json 文件的形式来指定。使用 wdltools 工具可以根据 WDL 文件来生成输入模板:1
java -jar wdltools.jar inputs myWorkflow.wdl > myWorkflow_inputs.json
模板格式如下:1
2
3{
"<workflow name>.<task name>.<variable name>":"<variable type>"
}
当然,如果工作流不是很复杂,也可以按照上面的格式手写 input 文件。下面是一个 GATK 工作流的 input 文件的片段: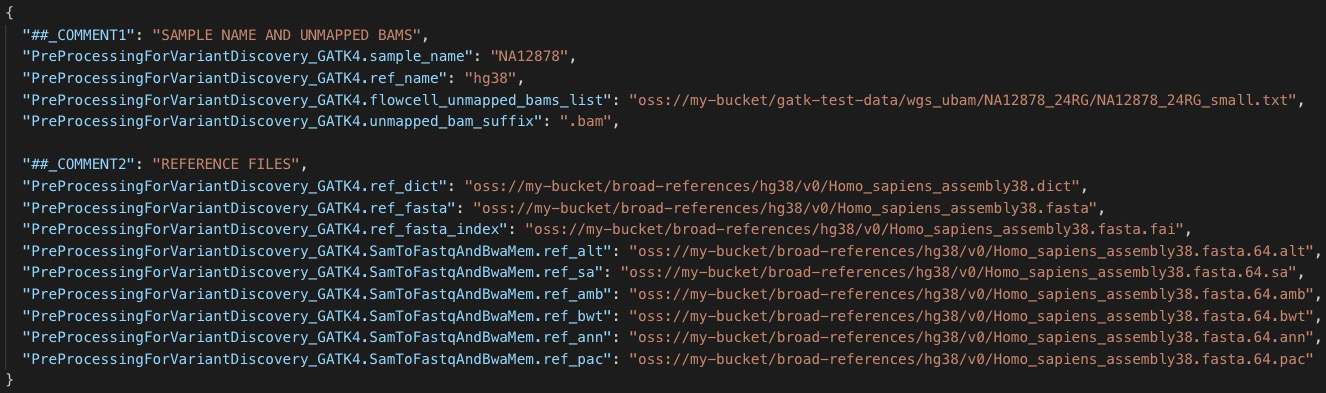
示例
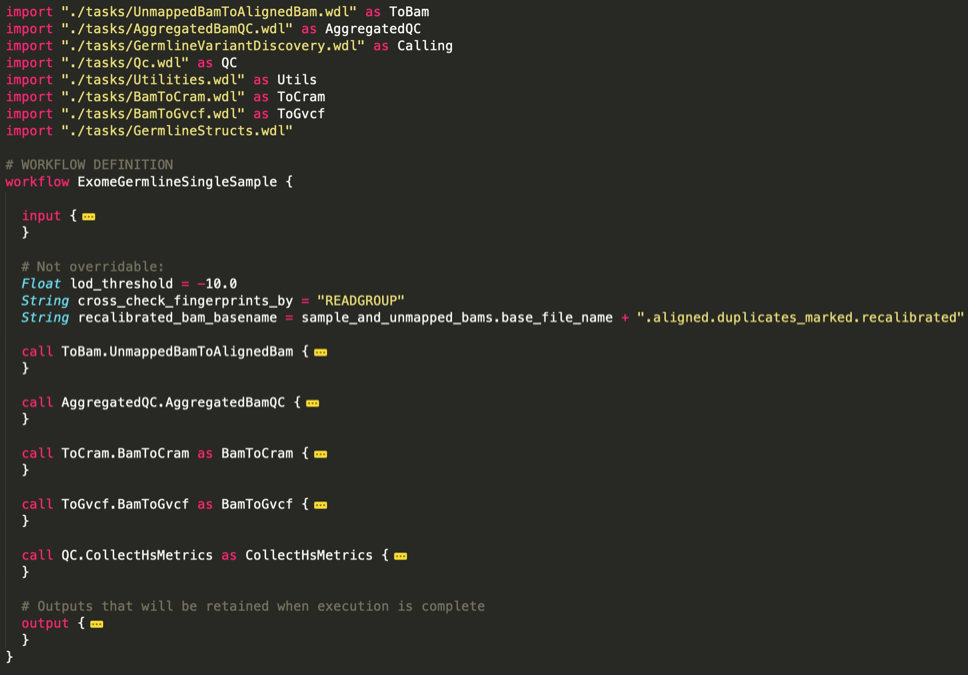
task定义:UnmappedBamToAlignedBam
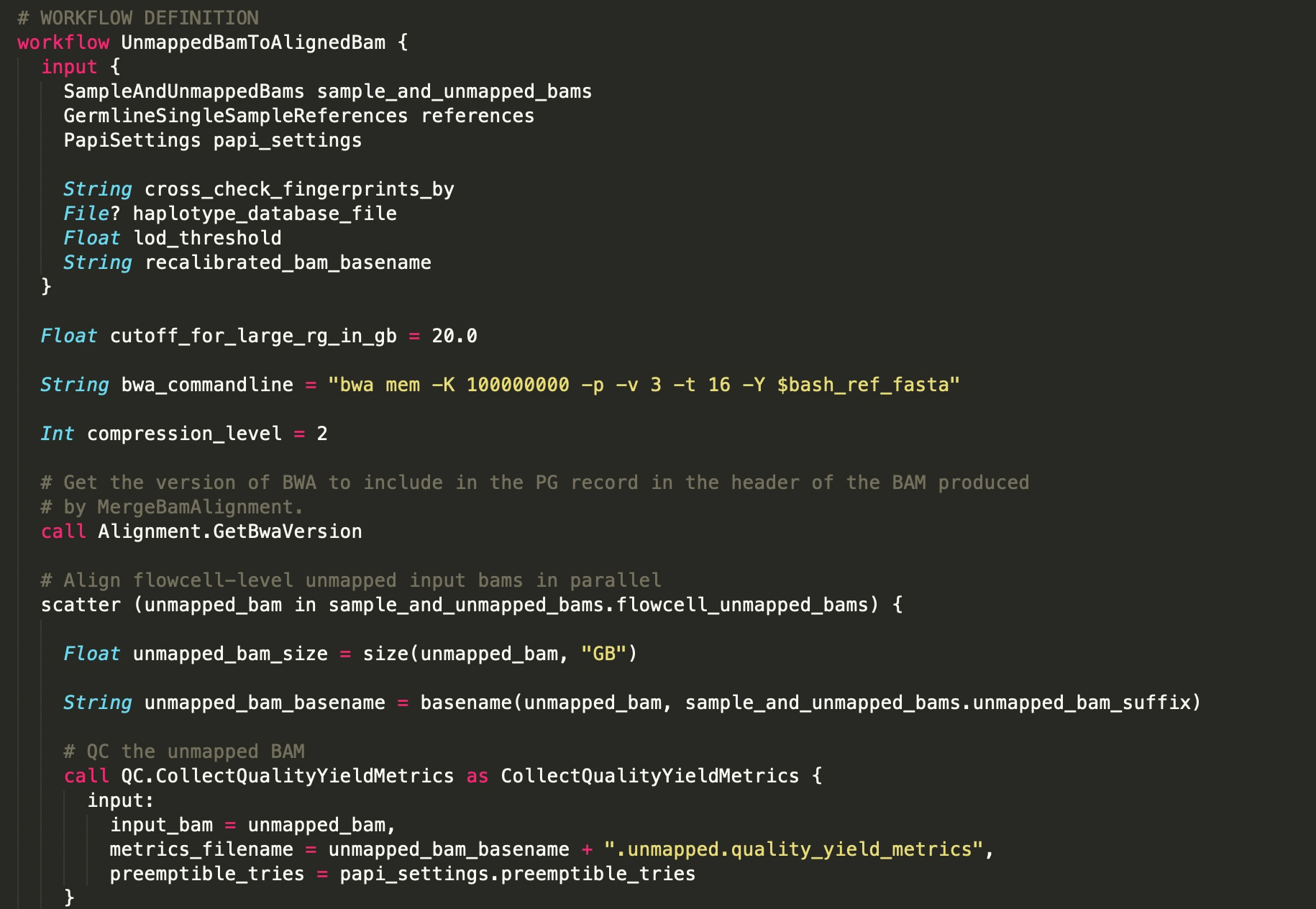
工作流解析
- 整个 Workflow 由5个 task 组成
- Task 之间通过 Linear Chaining 的方式组合
- 每个 Task 是子 Workflow,由多个 Task 组合而成。也就是说 WDL - 支持嵌套,workflow 里面的任务,既可以是一个 task,也可以是一个完整的 workflow,这个 workflow 被称为sub workflow。更多关于嵌套的用法请参考官方规范文档。