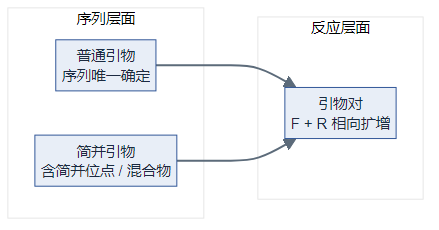
我们常笼统说「引物设计」,但从序列形态和在 PCR 中的角色来看,下面三类概念经常一起出现,但含义不同:
- 普通引物(Normal Primer):一条序列完全确定的寡核苷酸。
- 简并引物(Degenerate Primer):在若干位点使用 IUPAC 简并碱基的引物,化学上往往是多条序列的混合物。
- 引物对(Primer Pair):完成一次常规 PCR 扩增所需的 Forward + Reverse 功能组合;每条可以是普通引物,也可以是简并引物。
理清三者关系,有助于理解 PMPrimer 等工具「先找保守区 → 再设计简并引物 → 再组成引物对」的流程。
三类概念的关系(总览)
1 | flowchart LR |
1. 普通引物(Normal Primer)
定义与特点
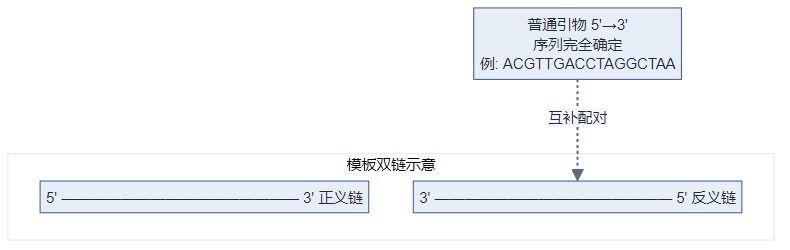
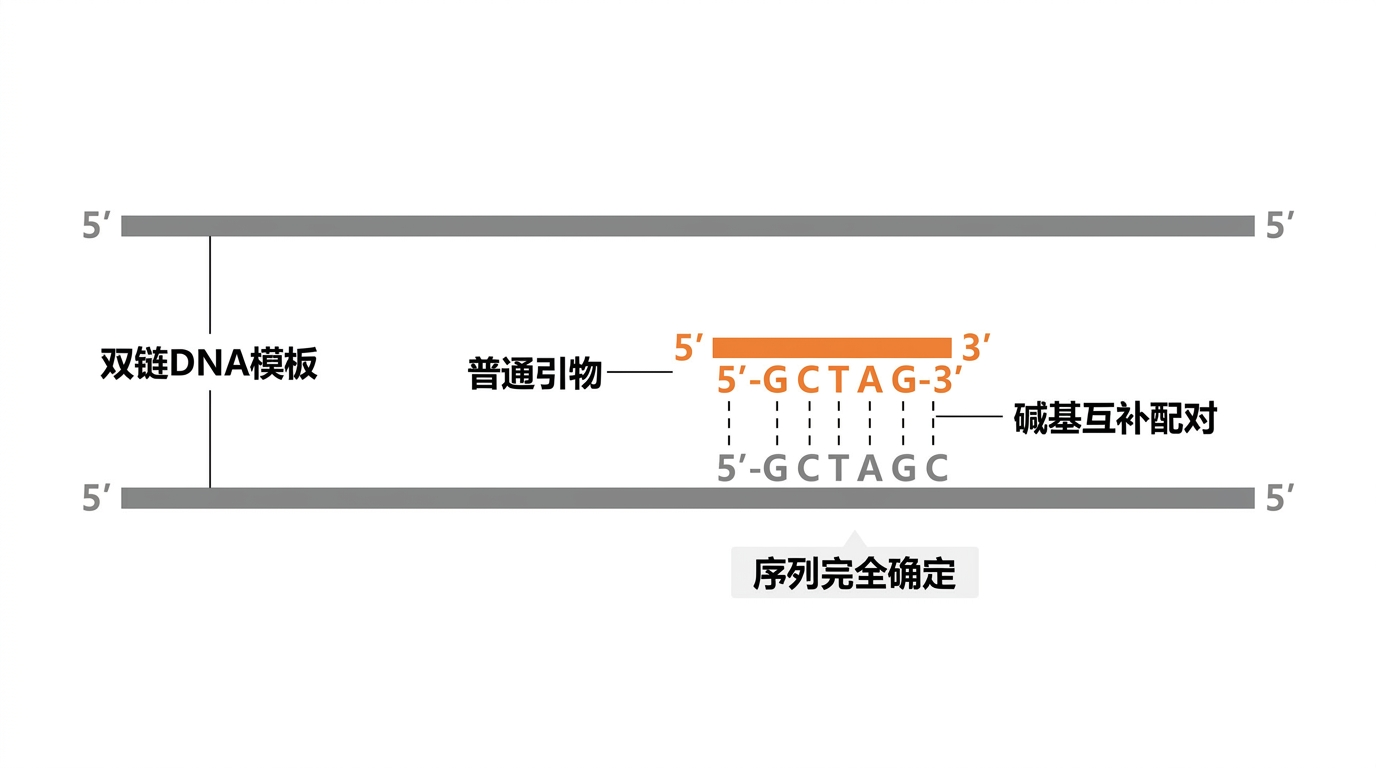
- 定义:每个位置均为 A/T/C/G 之一,序列唯一、合成后分子间一致。
- 特点:设计简单、特异性易评估;依赖模板序列已知且位点保守。
示意图:与模板互补结合
1 | flowchart TB |
典型应用场景
| 场景 | 说明 |
|---|---|
| 已知位点基因分型 | SNP、Indel 检测;引物落在侧翼固定序列上。 |
| 物种 / 株系特异检测 | 引物落在物种特异区,用于鉴定或检疫。 |
| 常规克隆与亚克隆 | 载体 / 插入片段边界明确,用确定序列扩增。 |
| qPCR / dPCR 定量 | 探针法或染料法均要求引物序列确定、Tm 可调。 |
| Sanger 测序前 PCR | 扩增片段固定,便于后续单向或双向测序。 |
| 甲基化特异性 PCR(引物本身仍为确定序列) | 针对亚硫酸盐转化后已知序列设计(实验设计复杂,但引物序列仍是确定的)。 |
| 小结:模板单一、序列可靠时,优先用普通引物,便于特异性分析与生产合成。 |
2. 简并引物(Degenerate Primer)
定义与特点
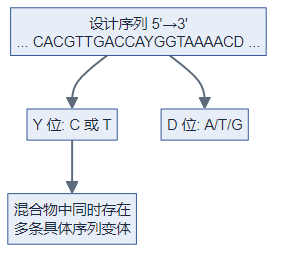
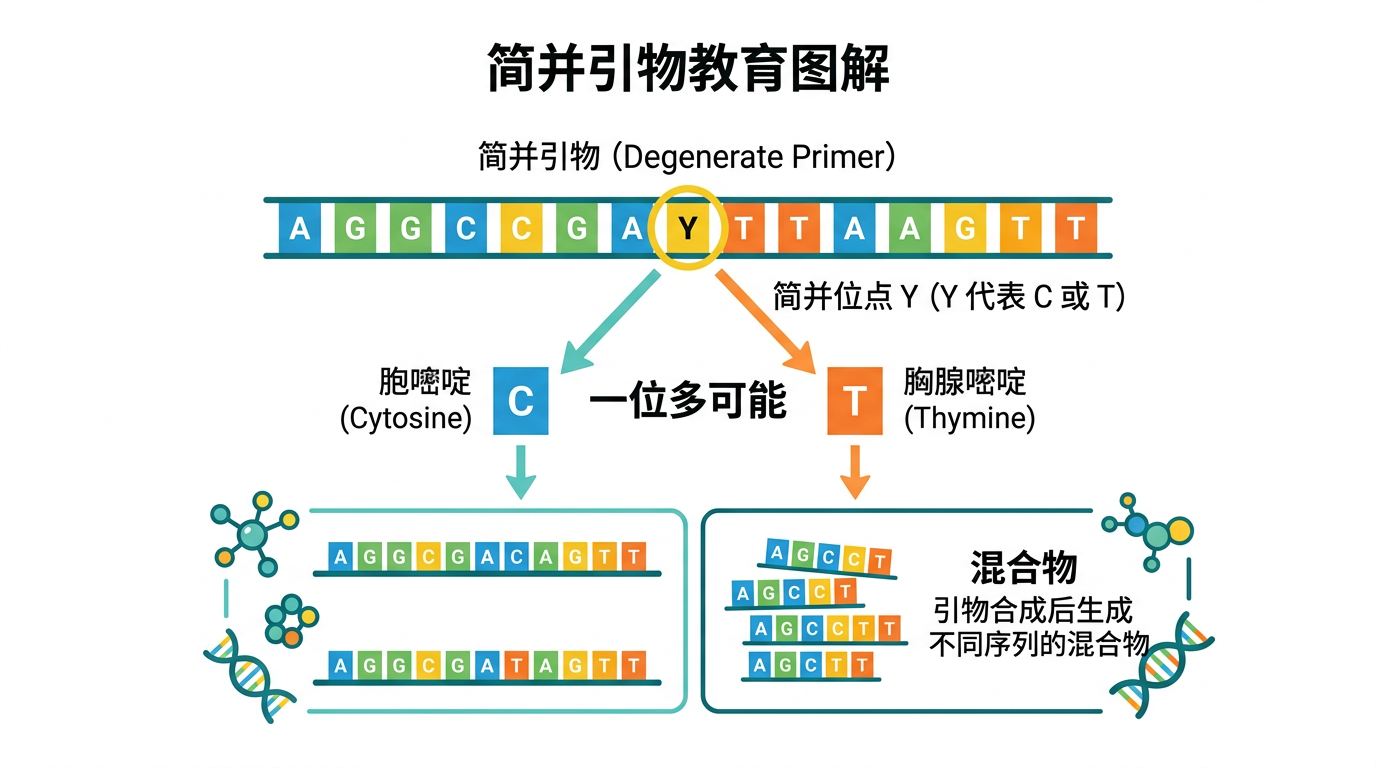
- 定义:一条「引物序列」中部分位置为 IUPAC 简并碱基,合成时往往是多种寡核苷酸分子的混合物。
- 简并碱基示例(与原文一致,便于查阅):
- R:A 或 G(嘌呤)
- Y:C 或 T(嘧啶)
- N:A、T、C、G 任一种
- D:A、T、G(非 C)等
示意图:一位简并 → 多种实际分子
1 | flowchart TB |
典型应用场景
| 场景 | 说明 |
|---|---|
| 病毒 / 准种扩增 | 基因组变异大,用简并位点覆盖亚型。 |
| 多物种同源基因共扩增 | 同一引物对尝试覆盖亲缘物种间保守但非完全一致的区域。 |
| 宏基因组 / 环境样本 | 模板多样,需提高「一锅反应」中的匹配概率。 |
| 多重 PCR panel 的保守区抓取 | 如 PMPrimer:在多序列比对保守区内设计简并引物,再评估引物对组合。 |
| 已知存在 SNP 但仍需共扩增 | 在变异位点用简并碱基减少错配(需评估 Tm 与非特异风险)。 |
| 小结:简并引物用「混合物」换「覆盖度」;设计时必须关注 有效浓度稀释、非特异扩增、Tm 分布,常配合软件评估与实验优化。 | |
示例(与原文呼应):5'-CACGTTGACCAYGGTAAAACD-3' 中 Y、D 使实际合成产物为多种具体序列的组合。 |
3. 引物对(Primer Pair)
定义与空间关系
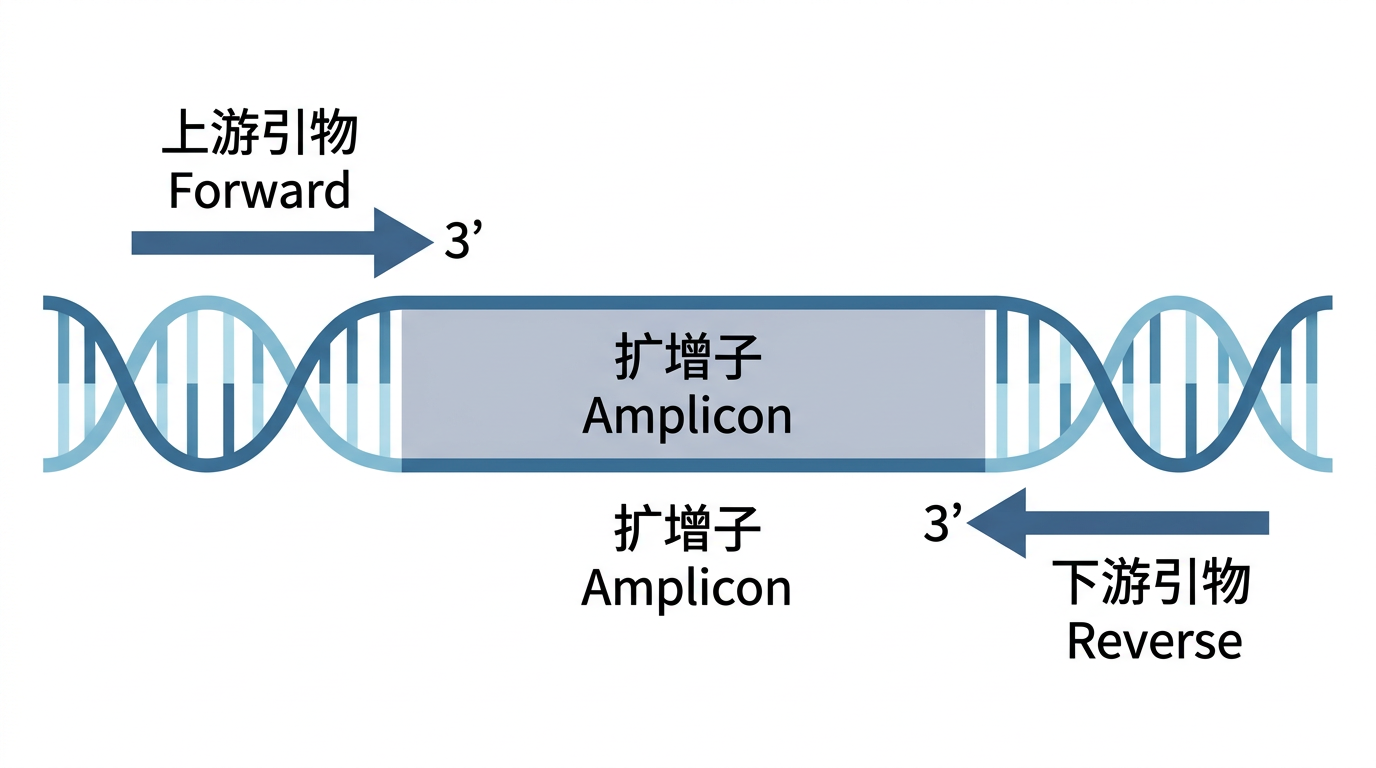
- 定义:一次常规 PCR 扩增所需的 上游(Forward)+ 下游(Reverse) 两条引物。
- 空间关系:
- Forward 与 Reverse 分别与双链的两条链互补;
- 3’ 端相向,中间区段即为 扩增子(Amplicon)。
示意图:相向扩增

1 | flowchart LR |
典型应用场景
| 场景 | 说明 |
|---|---|
| 常规 PCR 鉴定 | 任意需要「扩出一段已知侧翼之间序列」的实验。 |
| RT-PCR / 一步法 RT-qPCR | 引物对针对 cDNA;可能一条或两条跨外显子以避基因组污染。 |
| 巢式 PCR | 内外两对引物;外层与内层各为一组引物对。 |
| 多重 PCR | 多对引物同一管;每对仍是 F+R,需优化二聚体与浓度。 |
| 测序文库侧翼扩增 | 为建库提供固定长度或带接头的片段(常在 5’ 加酶切位点等,属引物设计扩展)。 |
| 示例(与原文呼应): |
- Forward:
5'-CACGTTGACCAYGGTAAAACD-3'(可为简并) - Reverse:
5'-TCACGMGTTTGWGGCATTGG-3' - 二者共同决定扩增片段;单独一条无法完成双链指数扩增。
总结对照
| 概念 | 本质 | 与 PCR 的关系 |
|---|---|---|
| 普通引物 | 序列确定的单条寡核苷酸 | 可作为 F 或 R 中的任意一条 |
| 简并引物 | 简并位点 → 常为多序列混合物 | 同样可作为 F 或 R,强调覆盖多样模板 |
| 引物对 | F + R 的功能组合 | 执行一次标准扩增的基本单位 |
| 在 PMPrimer 等工作流中,典型顺序是:多序列比对找保守区 → 设计简并引物 → 组合成最优引物对 → 输出简并序列及展开后的普通引物(单倍型)列表,供实验选用。 |
附录:IUPAC 简并碱基完整对照表
下表为 DNA 语境下常用 IUPAC 模糊碱基(degenerate nucleotide codes)。合成引物下单、序列比对与文献中均按此约定。RNA 中 T 常读作 U,简并含义不变。
确定碱基(无歧义)
| 符号 | 含义 |
|---|---|
| A | 腺嘌呤 Adenine |
| C | 胞嘧啶 Cytosine |
| G | 鸟嘌呤 Guanine |
| T | 胸腺嘧啶 Thymine(RNA 中对应 U) |
双碱基简并(最常见)
| 符号 | 含义 | 记忆提示 |
|---|---|---|
| R | A 或 G(嘌呤 PuRine) | R |
| Y | C 或 T(嘧啶 pYrimidine) | Y |
| S | G 或 C(强配对 Strong) | S |
| W | A 或 T(弱配对 Weak) | W |
| K | G 或 T(酮基 Keto:G/T) | K |
| M | A 或 C(氨基 aMino:A/C) | M |
三碱基简并(「非某碱基」类)
| 符号 | 含义 | 等价表述 |
|---|---|---|
| B | C 或 G 或 T(非 A) | not A |
| D | A 或 G 或 T(非 C) | not C |
| H | A 或 C 或 T(非 G) | not G |
| V | A 或 C 或 G(非 T) | not T |
四碱基(任意)
| 符号 | 含义 |
|---|---|
| N | A、C、G、T 任一种(任意位点) |
使用提示
- 简并度:一位
N等价 4 种序列;一位R等价 2 种;整条简并引物的理论组合数为各位可能数的乘积,合成前宜评估复杂度与有效摩尔浓度。 - 与工具一致:PMPrimer、Primer、合成公司订单中的 IUPAC 字母与上表一致;若有自定义字母表需单独说明。
- RNA 引物:若设计 RNA 引物,文献中仍常写 T 或 U,以合成单要求为准。