许多科学对象天然是关系数据:分子中原子通过化学键相连、蛋白质残基通过接触或共价键构成网络、引物–模板–酶之间是相互作用图。若把每个实体当作节点(node)、把关系当作边(edge),就得到图(graph)$G=(V,E)$。图神经网络(Graph Neural Network,GNN)在图上做可微分的邻居信息聚合,学习既尊重局部连接、又对节点排列顺序不敏感(置换不变,permutation invariant)的表示。本文是 SE(3)-等变图神经网络:原理、算法与应用场景 的前置导读:先掌握普通 GNN 的「消息–聚合–更新」骨架,再进入带三维坐标与对称性约束的几何等变模型会顺畅得多。
段末注释:GNN 泛指在图结构上通过多层邻居聚合学习表示的神经网络族;置换不变指打乱节点编号后,合理的图级输出应保持不变。
1. 为什么用图而不是表格或网格
| 数据形态 | 典型例子 | 归纳偏置 |
|---|---|---|
| 表格(独立样本) | 溶解度数据库的一行一个分子描述符 | 样本之间无结构关联 |
| 网格(规则邻域) | 二维图像像素 | 平移局部性、固定邻域 |
| 图(不规则邻域) | 分子、知识图谱、蛋白质接触图 | 谁与谁相连因样本而异 |
分子用SMILES 或指纹(fingerprint)也能喂给多层感知机(Multi-Layer Perceptron,MLP),但键连拓扑、环结构、官能团上下文被压扁后不易显式传递。GNN 把「第 $k$ 个原子的邻居是谁」写进计算图,使每一层表示自动融合多跳邻域(multi-hop neighborhood)信息。
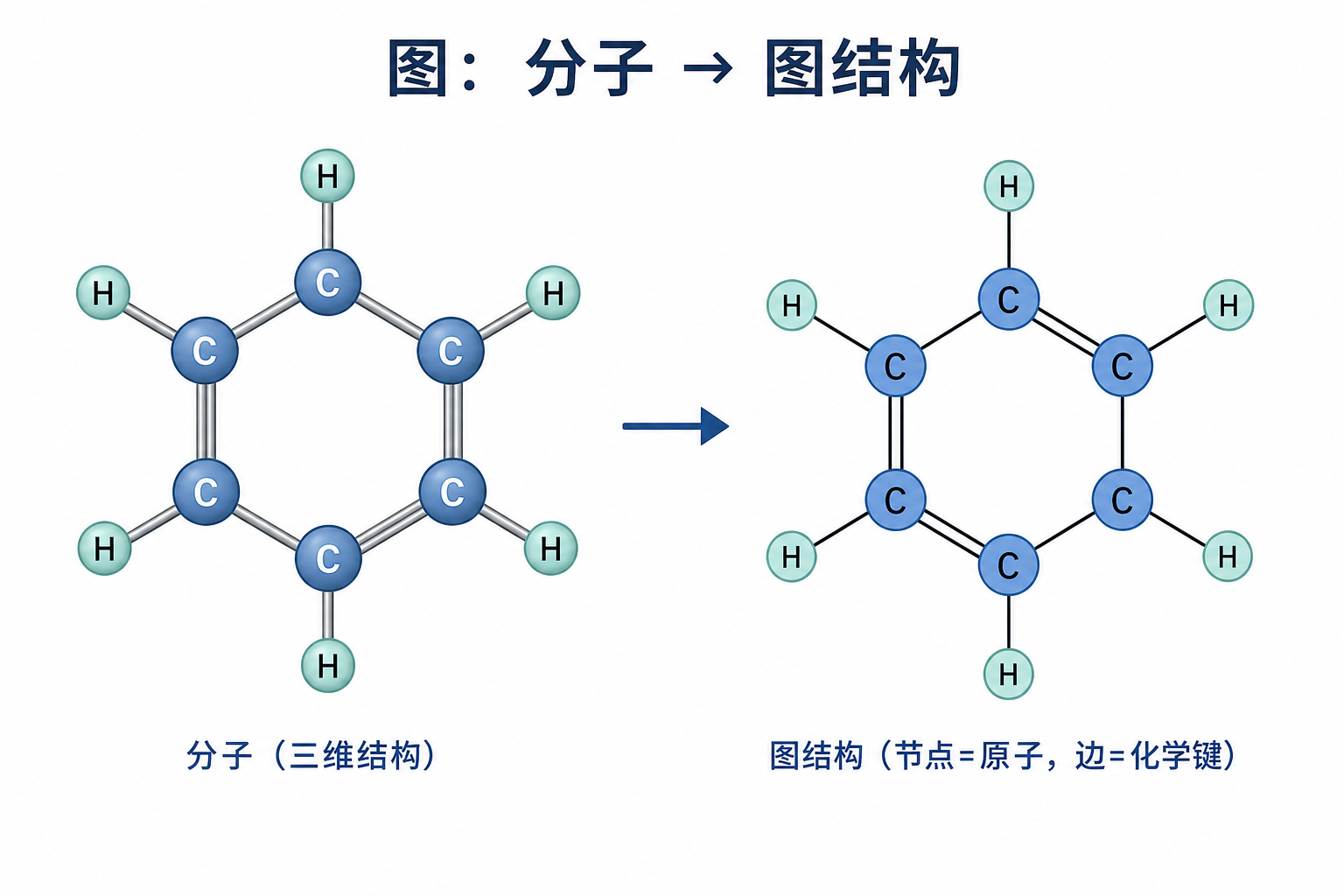
图 1(科普示意):左为三维分子直观图;右为抽象图 $G=(V,E)$,节点携带原子类型等特征,边可编码键级或距离。
段末注释:SMILES 为分子的一维字符串表示;指纹为固定长度的二进制或实值向量,常由子结构枚举得到。
2. 图的数学表示与特征
2.1 邻接与度
- 邻接矩阵 $\mathbf{A}\in{0,1}^{n\times n}$:$A_{ij}=1$ 表示 $i$ 与 $j$ 相连(无向图常令 $\mathbf{A}$ 对称)。
- 邻接表 $\mathcal{N}(i)={j:(i,j)\in E}$:稀疏存储,大规模图与小批量(mini-batch)训练更常用。
- 节点特征矩阵 $\mathbf{X}\in\mathbb{R}^{n\times d}$:第 $i$ 行为 $\mathbf{x}_i$(原子序数 one-hot、杂化、形式电荷等)。
- 边特征(可选)$\mathbf{e}{ij}$:键型、空间距离 $r{ij}$、是否共价等。
2.2 同构图 vs 异构图
- 同构图(homogeneous graph):节点、边类型单一(如「全是碳链原子 + 单/双键」)。
- 异构图(heterogeneous graph):多种节点/边类型(蛋白质中残基、配体、离子;边分「共价」「氢键」「接触」)。可用关系图卷积(R-GCN)等扩展,核心仍是分类型消息传递。
2.3 有向、无向与加权
无向化学键常把消息沿边双向传递;信息流、引物延伸方向等场景可用有向边。边权 $w_{ij}$ 可表示接触强度、共现频率或 $1/r_{ij}$ 等。
3. 普通 MLP / CNN 的局限
MLP 把每个节点当作独立向量:节点 $i$ 的预测无法直接利用邻居 $j$ 的标签或特征,除非手工拼接固定长度邻居列表(长度随图变化,不便)。
卷积神经网络(Convolutional Neural Network,CNN)的卷积核在规则网格上滑动;图的邻域大小 $|\mathcal{N}(i)|$ 随节点变化,没有统一的「$3\times3$ 窗口」。
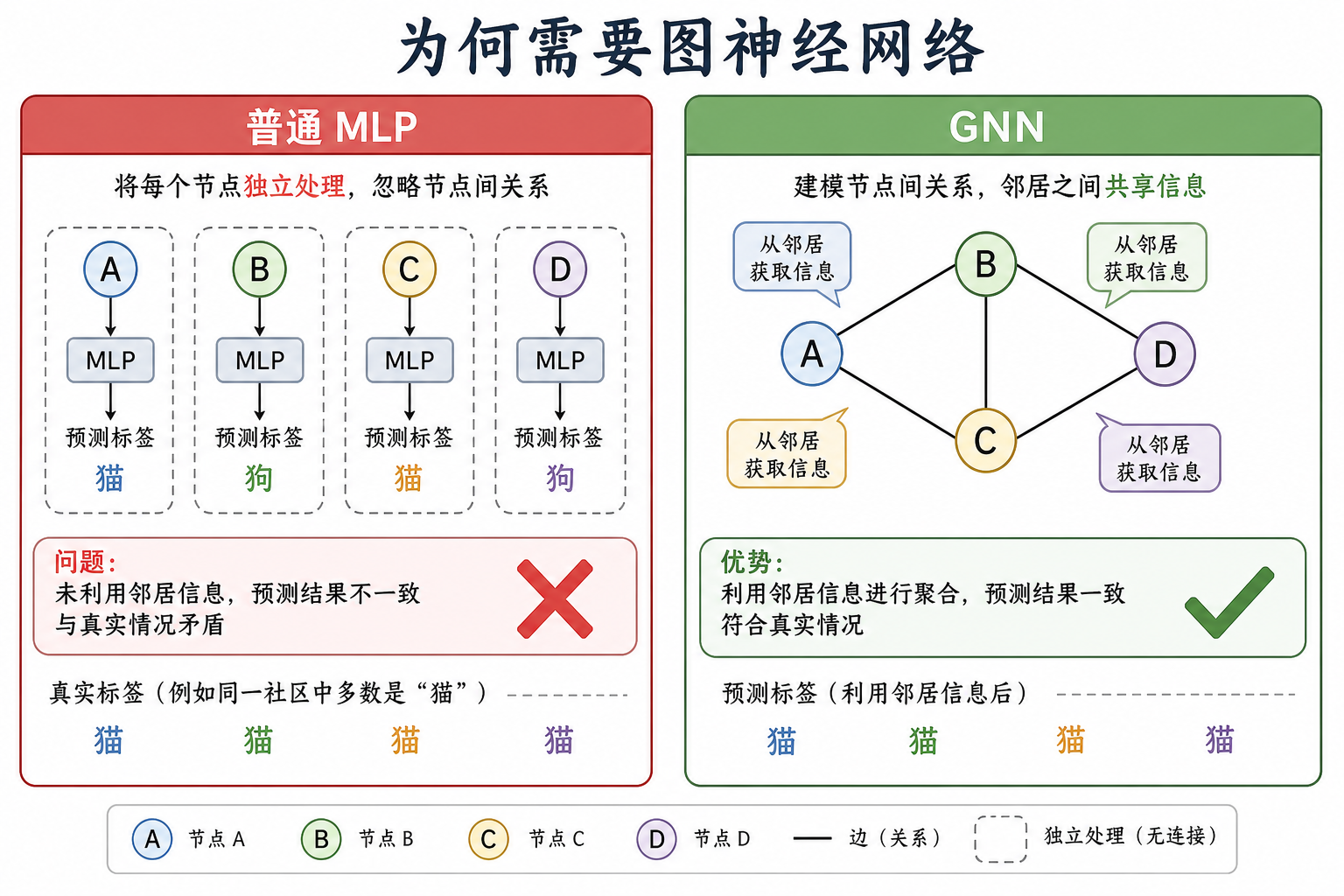
图 2(科普示意):GNN 通过边共享信息;堆叠 $L$ 层后,节点 $i$ 的表示近似融合 $L$ 跳 内邻居(类似 CNN 的感受野)。
段末注释:感受野指输出依赖的输入范围;GNN 中常由层数与跳数刻画。
4. 消息传递神经网络(核心范式)
消息传递神经网络(Message Passing Neural Network,MPNN)将一层 GNN 抽象为三步(Gilmer et al., 2017):
- 消息(message):$\mathbf{m}_{ij}^{(t)}=\phi_m!\left(\mathbf{h}_i^{(t)},\mathbf{h}j^{(t)},\mathbf{e}{ij}\right)$
- 聚合(aggregate):$\bar{\mathbf{m}}i^{(t)}=\bigoplus{j\in\mathcal{N}(i)}\mathbf{m}_{ij}^{(t)}$,其中 $\bigoplus$ 常为 sum / mean / max
- 更新(update):$\mathbf{h}_i^{(t+1)}=\phi_u!\left(\mathbf{h}_i^{(t)},\bar{\mathbf{m}}_i^{(t)}\right)$
初始 $\mathbf{h}_i^{(0)}=\mathbf{x}_i$。图级预测再经读出(readout)函数 $\mathbf{h}_G = \rho({\mathbf{h}i^{(T)}}{i\in V})$。
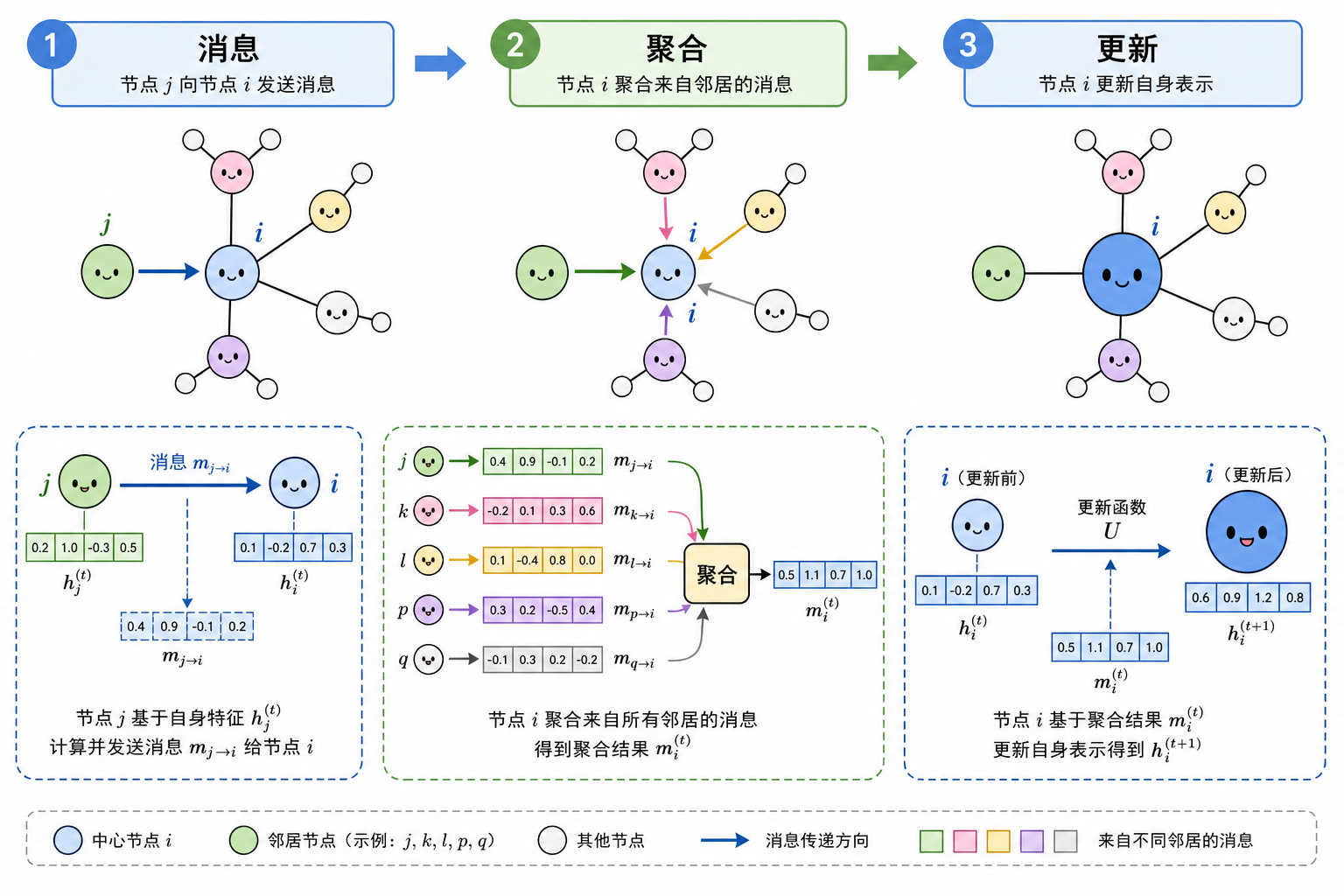
图 3(科普示意):与后续 SE(3)-等变 GNN 相同的外壳;区别主要在于消息函数 $\phi_m$ 是否使用三维坐标、是否保证旋转等变。
段末注释:MPNN 是多数 GNN 变体的统一写法;读出 $\rho$ 将节点集合映射为图向量。
5. 代表算法(由经典到常用)
5.1 图卷积网络(GCN)
Kipf & Welling (2017) 的图卷积网络(Graph Convolutional Network,GCN)在谱域近似下得到简洁形式。令 $\tilde{\mathbf{A}}=\mathbf{A}+\mathbf{I}$,$\tilde{\mathbf{D}}$ 为 $\tilde{\mathbf{A}}$ 的度矩阵,则一层可写为:
$$
\mathbf{H}^{(t+1)} = \sigma!\left(\tilde{\mathbf{D}}^{-\frac{1}{2}}\tilde{\mathbf{A}}\tilde{\mathbf{D}}^{-\frac{1}{2}}\mathbf{H}^{(t)}\mathbf{W}^{(t)}\right).
$$
直觉:先对邻居特征做对称归一化加权平均,再经可学习线性 $\mathbf{W}^{(t)}$ 与非线性 $\sigma$。多层 GCN 加深时可能出现过平滑(over-smoothing):各节点表示趋于相同,需残差、跳连或层数控制。
5.2 图注意力网络(GAT)
图注意力网络(Graph Attention Network,GAT,Veličković et al., 2018)为不同邻居赋予可学习权重 $\alpha_{ij}$(常经 masked softmax 归一化),适合「并非所有邻居同等重要」的接触图或知识图谱。
$$
\mathbf{h}i^{(t+1)}=\sigma!\left(\sum{j\in\mathcal{N}(i)\cup{i}}\alpha_{ij},\mathbf{W}\mathbf{h}_j^{(t)}\right).
$$
5.3 GraphSAGE
GraphSAGE(Hamilton et al., 2017)强调归纳式(inductive)学习:训练时见过部分图结构,推理时可对新节点/新图做前向。聚合器除 mean 外,常用 LSTM 聚合器(需对邻居随机排列)或 pooling 聚合器($\max$ / mean 后再 MLP)。
5.4 其它常遇变体(点到为止)
| 模型 | 要点 |
|---|---|
| GIN | 用 sum 聚合 + MLP,在 WL 测试意义下表达力较强 |
| GINE | 边特征进入消息,适合分子键型 |
| SchNet / DimeNet | 分子三维坐标进入,但主要用距离等不变量(为 $\mathrm{SE}(3)$ 续篇铺垫) |
| R-GCN | 异构关系类型分通道 |
6. 图级读出与置换不变性
节点级任务(原子电荷、残基溶剂可及性)直接用 $\mathbf{h}_i^{(T)}$。图级任务(分子能量、毒性分类、蛋白–配体结合有无)需置换不变的 $\rho$,常见:
- 全局平均池化(global mean pooling):$\mathbf{h}_G=\frac{1}{|V|}\sum_i \mathbf{h}_i^{(T)}$
- 全局求和池化(global sum pooling)
- Set2Set / 注意力池化:可学习权重但仍对排列不变
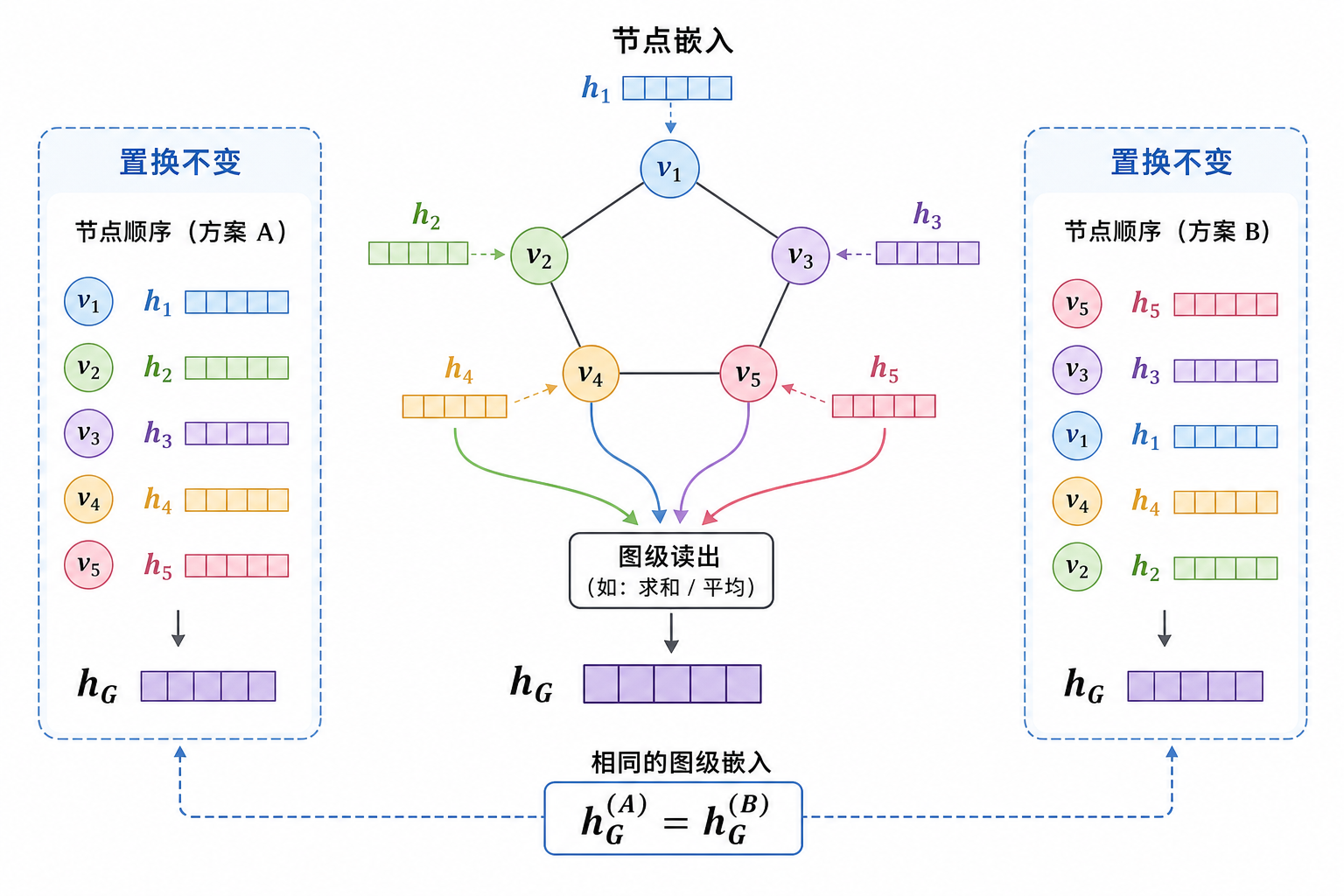
图 4(科普示意):读出层保证「同一图、不同节点编号」得到相同图级向量(对合理的 $\rho$)。
段末注释:WL 测试(Weisfeiler–Lehman test)是衡量 GNN 区分图结构能力的经典工具;过弱的聚合可能无法区分某些非同构图。
7. 分子与蛋白场景中的构图实践
7.1 节点与边怎么定
| 设定 | 节点 | 边 |
|---|---|---|
| 小分子 | 原子 | 共价键;或 半径图($r_{ij} < r_{\mathrm{cut}}$ 时连边) |
| 蛋白质 | 残基 $C_\alpha$ 或全原子 | 序列相邻 + 空间接触(实践见 蛋白结构 Python 编码) |
| 蛋白–配体 | 异构节点 | 跨分子接触边 |
半径图能编码非共价相互作用,但边数随截断半径增大;$k$ 近邻图($k$NN)可控制度数上界。
7.2 特征与标签
- 节点:元素、杂化、芳香性、B-factor(结构)、进化保守性(MSA)等。
- 边:键级、$r_{ij}$、相对方向(进入等变模型时关键)。
- 图级标签:溶解度、活性、结合亲和力;节点级:原子电荷、残基二级结构。
7.3 与普通 GNN 相关的坑
- 数据泄漏:随机划分分子时,高度相似骨架应归入同一折(骨架聚类划分,scaffold split)。
- 图大小差异:批处理需 padding + batch 向量 或 PyG 的
Batch合并。 - 对称性:普通 GNN 不保证旋转坐标后向量输出同步旋转;标量性质可用距离等不变特征缓解。若需力、取向等向量输出,见下文衔接。
8. 训练与工程速览
| 组件 | 说明 |
|---|---|
| PyTorch Geometric(PyG) | Data(x, edge_index, edge_attr, y),DataLoader 批图 |
| DGL | 另一主流图深度学习框架,API 不同但 MPNN 思想一致 |
| 损失 | 图级交叉熵 / MSE;节点级 mask 未标注节点 |
| 深度 | 3–5 层常见起点;观察验证集是否过平滑 |
最小数据流(伪代码):
1 | # x: [N, d_in], edge_index: [2, E] |
9. 典型应用场景
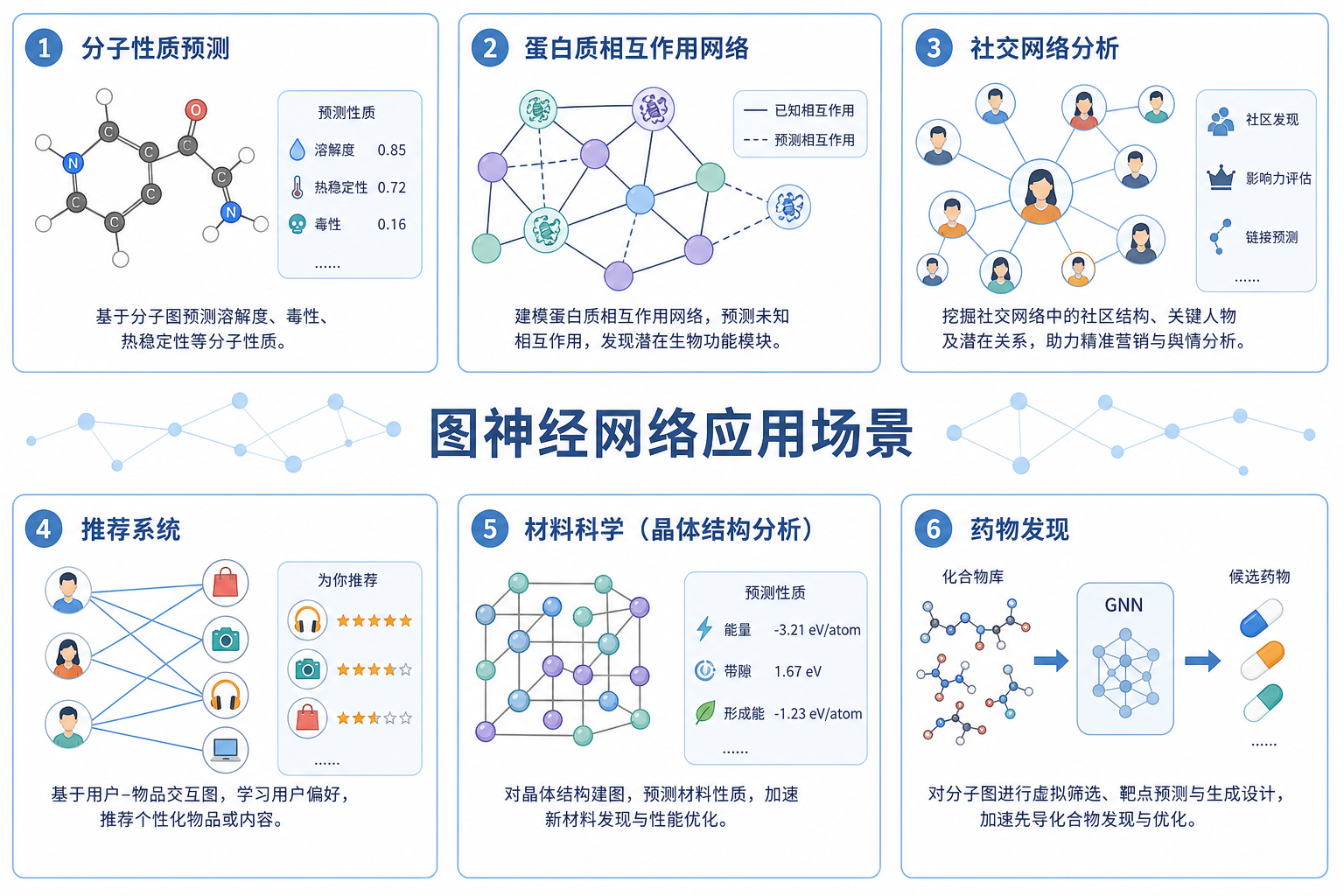
图 5(科普示意):GNN 已广泛用于化学信息学、生物网络与关系型数据;科学计算中常与三维几何模型衔接。
| 场景 | 任务类型 | GNN 作用 |
|---|---|---|
| 分子性质预测 | 图级回归/分类 | 聚合原子环境预测溶解度、毒性等 |
| 反应产率 / 选择性 | 图级 | 反应物–试剂构图或产物图 |
| 蛋白质功能注释 | 节点/图级 | 残基图上传导序列与接触信息 |
| 虚拟筛选 | 图级打分 | 蛋白–配体异构图 |
| 引物/序列–结构 | 序列图或 $k$-mer 图 | 局部上下文编码(与本文聚合酶系列主题相邻) |
10. 从普通 GNN 到 SE(3)-等变 GNN
掌握本文后,你已具备阅读 SE(3)-等变图神经网络 的前置概念:
| 概念 | 普通 GNN(本文) | SE(3)-等变 GNN(续篇) |
|---|---|---|
| 输入几何 | 可选 $r_{ij}$、拓扑 | 显式 $\mathbf{x}_i \in \mathbb{R}^3$,相对方向进消息 |
| 对称性 | 常仅对置换不变 | 另需对旋转/平移等变或不变 |
| 输出 | 多为标量图级 | 标量(能量)+ 向量(力、位移) |
| 代表模型 | GCN、GAT、GraphSAGE | EGNN、SE(3)-Transformer、NequIP |
续篇将回答:「坐标旋转后,网络输出的力为何应随坐标系一起转?」——那是在 MPNN 骨架上,把 $\phi_m$ 换成等变张量积与球谐方向编码后的结果。
11. 小结
图神经网络把「关系」写进前向计算:通过消息–聚合–更新在局部邻域反复交换信息,再用置换不变读出得到图级表示。GCN 提供归一化邻域平均的简洁基线,GAT 与 GraphSAGE 分别强化注意力与归纳场景。分子与蛋白建模中,构图方式(共价 vs 半径图)、划分策略与池化读出往往决定基线强弱;当任务涉及三维向量与刚体对称性时,应在同一 MPNN 范式上升级为 SE(3)-等变 架构。
参考文献与延伸阅读
- Gilmer, J. et al. Neural Message Passing for Quantum Chemistry. ICML 2017.
- Kipf, T. N. & Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. ICLR 2017.
- Veličković, P. et al. Graph Attention Networks. ICLR 2018.
- Hamilton, W. L. et al. Inductive Representation Learning on Large Graphs. NeurIPS 2017 (GraphSAGE).
- Xu, K. et al. How Powerful are Graph Neural Networks? ICLR 2019 (GIN).
- PyTorch Geometric 文档: https://pytorch-geometric.readthedocs.io
- 实践:图神经网络处理蛋白结构:Python 数据流与编码实践
- 续篇:SE(3)-等变图神经网络:原理、算法与应用场景