PrimeGen 是以 GPT-4o 为中央控制器的多智能体系统,覆盖意图理解、序列检索、引物面板优化、机器人协议生成与视觉异常检测,面向靶向扩增子测序等场景。下文为基于论文的整理笔记。
文献与官方资源
| 类型 | 说明 |
|---|---|
| 论文 | Wang Y, et al. Accelerating primer design for amplicon sequencing using large language model-powered agents. Nat Biomed Eng (2025). DOI 10.1038/s41551-025-01455-z |
| PubMed | PMID 40738975 |
| 代码 | https://github.com/melobio/PrimeGen |
| 补充 | 仓库 README 中可能提供演示或 Web 入口(以官方更新为准) |
应用场景
- 靶向扩增子测序:全基因组病毒(如 SARS-CoV-2 131 重 panel)、人类 ECS 多基因外显子、MTB 耐药 SNP、酶突变质粒等需高重数面板且要闭环优化。
- 自然语言驱动的实验:从「意图 → 库检索 → 引物 → 机器人协议 → 视觉质控」一条龙,适合已有 GPT-4o API、自动化硬件 的实验室。
- 不适合:仅需离线、无 LLM 的常规单对/少量引物(用 Primer3 / PMPrimer 等即可);或对可复现性、成本、数据出境有严格限制且无法使用云端模型的场景。
使用帮助
部署形态
| 方式 | 说明 |
|---|---|
| 源码 | melobio/PrimeGen:需按 README 配置 Python、BLAST+、MAFFT/MUSCLE、Primer3、推理后端(如 vLLM)及 GPT-4o 等 API。 |
| 线上 | 以仓库与论文补充材料为准;无保证长期公共 SaaS。 |
输入与输出
- 输入
- 用户侧:自然语言目标(物种/基因/疾病/panel 类型);
- 数据侧:NCBI、OMIM、COSMIC、ClinVar、CARD 等检索得到的序列或位点;湿实验反馈:fastp/BWA 后的 MTR、均匀性、二聚体率、SMTR 等。
- 输出
- 引物面板(序列、plex 分配)、损失函数优化轨迹;Python 机器人脚本;实验智能体 告警/自修复 日志。
资源与环境
- 算力:高重面板 + BLAST + LLM 多轮 + 可选 VLM 视频推理,GPU/内存/API 费用显著。
- 合规:序列与患者相关场景需注意 隐私与跨境 政策。
文献概述:PrimeGen 的定位
PrimeGen 的核心是一个由 GPT-4o 作为“中央控制器”的多智能体系统。它通过模拟人类专家团队的分工协作,将复杂的引物设计及验证任务拆解为多个子任务,由专门的智能体协同完成。其最终目标是实现从用户意图理解、目标序列检索、引物设计优化、实验自动化脚本生成到湿实验异常检测的全流程闭环自动化。
核心原理与方法:基于大语言模型的多智能体协作架构
PrimeGen 的整体架构和工作流程如下图所示,其核心在于通过大语言模型的理解、推理和生成能力,协调四个核心智能体。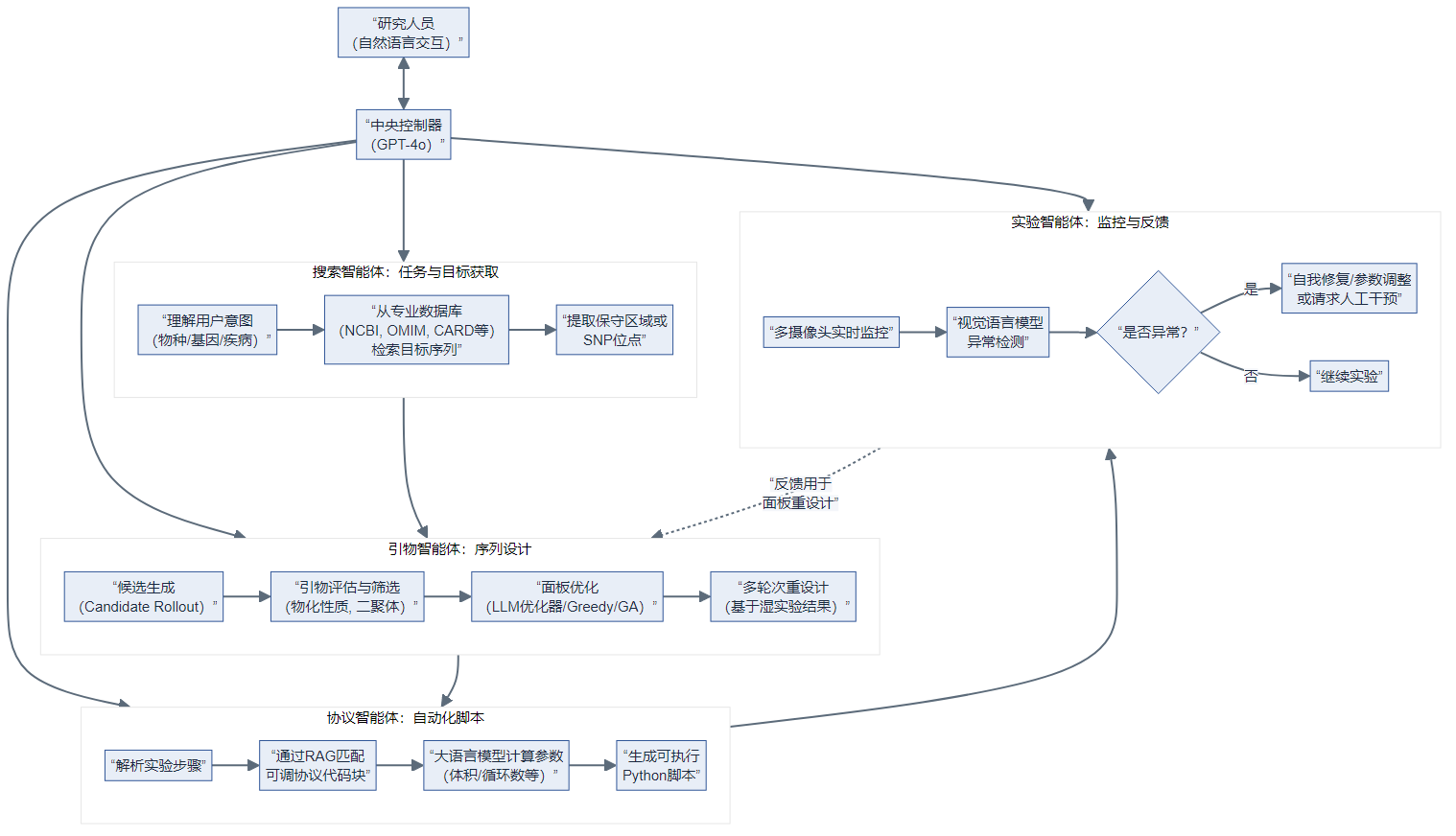
1 | flowchart TD |
配图(文献 / 仓库)
| 来源 | 说明 |
|---|---|
| 期刊原图 | 论文图表见 Nature BME — 文章页 内嵌 Figure 1–n;示例 Figure 1(具体图题以论文为准)。 |
| 仓库示意图 | 本地逻辑图:pg-agents.png、pg-loss.png(均由 Mermaid 导出);若 README 提供官方架构图,以 GitHub 为准。 |
1. 搜索智能体 (Search Agent)
- 功能:作为系统的“情报员”,负责理解用户用自然语言描述的实验目标(例如“检测肺癌药物靶点”、“对大肠杆菌进行耐药分析”),并据此从OMIM、COSMIC、ClinVar、UniProt、NCBI、CARD等专业数据库中自动检索并下载目标模板序列或SNP位点信息。
- 特色:它支持五种典型设计场景(病原体检测、遗传病、癌症、全基因组、蛋白突变),并能处理“目标明确”、“目标不确定”等多种情况,通过多轮对话与用户确认,最终将准确的序列信息传递给引物智能体。
2. 引物智能体 (Primer Agent) —— 本文的核心创新点
候选生成策略:
这是引物设计的“原材料(最初目标片段)”生产阶段。与PMPrimer等传统工具依赖全局保守区域不同,PrimeGen采用了一种更为灵活的“候选展开”方法,尤其适用于全基因组平铺(tiled PCR)设计。
- 滑动窗口扫描:系统在目标区域上,从一个确定的起点开始,以一个默认 40 bp的窗口 进行滑动。这个窗口长度是经过权衡的经验值:太短(<36 bp)会导致候选引物覆盖范围不足;太长则可能产生过多超出预期范围的扩增子。
- 候选生成策略:在每个滑动窗口位置,系统会基于以下严格标准筛选引物候选:
- 物理化学性质:GC含量控制在0.4-0.62之间,核苷酸多样性在0.1-0.4之间。
- 二级结构:通过吉布斯自由能 (ΔG) 筛选,排除那些容易自身形成稳定发夹结构或自我反向互补序列过长的引物。
- 序列复杂度:丢弃存在重复模式的序列,以避免非特异性结合。
- 逐步松弛机制:如果在连续滑动20步后仍无法找到合格候选,系统会逐步放宽上述约束条件(如GC范围、自由能阈值),以确保设计的连续性,避免因局部高变异区域而导致整个扩增子设计失败。
- 引物3的集成:在SARS-CoV-2的对比实验中,研究者也使用了 Primer3 作为候选生成的替代引擎(称为PrimeGen-Primer3),以验证不同生成策略的优劣。
通过这一过程,对于每一个目标扩增子(plex),系统都会生成一个包含 k_i × k_i 个候选引物对的“候选池”。
滑动窗口(公式化):设目标区长度为 (L),窗口长 (w)、步长 (s),则窗口起点可取
$$
t \in {0, s, 2s, \ldots} \cap [0,, L-w]
$$
每个 (t) 对应一段模板 ([t,,t+w)),在其内再筛出合格 forward/reverse 组合;若连续若干步无合格解则放宽 GC、ΔG 等阈值(论文中的「松弛」)。
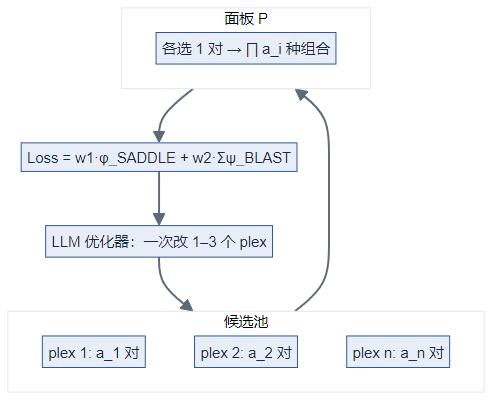
高重数面板优化-LLM优化器:
这是设计的难点。PrimeGen将引物对的选择定义为一个高维优化问题,目标是最小化引物二聚体损失(基于改进的SADDLE算法)和最大化特异性(基于BLAST比对的得分)。
文章创新性地使用大语言模型作为优化器。与一次只改变一个扩增子的传统贪婪算法不同,大语言模型优化器可以一次修改1-3个扩增子,并利用“历史面板向量”记忆来指导搜索。在78重(plex)的优化任务中,大语言模型优化器表现出了优于AdaLead和遗传算法(GA)的效率。
当存在多个扩增子(如78重、131重)时,从各自的候选池中挑选一对引物,组合成一个最终的面板,会面临一个极其庞大的搜索空间($\prod_{i=1}^{n} a_i$)。引物二聚体的可能性会随着引物数量的增加而指数级增长。因此,面板优化是引物智能体最具挑战性的部分,也是其核心创新所在。
组合规模:设第 (i) 个扩增子有 (a_i) 个候选引物对,则离散搜索空间大小为
$$
|\Omega| = \prod_{i=1}^{n} a_i
$$
完整枚举在 (n\sim 10^2)、(a_i\sim 10^2) 量级不可行,需启发式(贪婪、GA、LLM 优化器等)。
优化目标:在离散空间 (\Omega) 上最小化 (\text{Loss}(P)),其中 (P \in \Omega) 为各 plex 各选一对引物构成的面板。
$$
\text{Loss}(P) = w_1 \cdot \underbrace{\phi_{\mathrm{SADDLE}}(P)}{\text{二聚体相关}} + w_2 \cdot \underbrace{\sum{i=1}^{n} \psi_{\mathrm{BLAST}}(A_i)}_{\text{特异性/脱靶}}
$$
- (\phi_{\mathrm{SADDLE}}):基于改进的 SADDLE 思想,对面板内全部有序引物对(或程序规定的子集)计算二聚体倾向并聚合为标量「二聚体率 / 风险」;本质是组合优化中的结构惩罚项(论文以 SADDLE 为基线改进,细节以正文与补充材料为准)。
- (\psi_{\mathrm{BLAST}}):将扩增子 (A_i) 相关引物与非目标背景库比对,得分越高通常脱靶风险越大;(w_1,w_2) 可随重设计阶段调整(如提高 (w_2) 压 SMTR)。
1 | flowchart TD |
大语言模型优化器的工作机制:
传统的贪婪算法在一次迭代中只随机改变一个扩增子的引物对。而PrimeGen的创新在于利用大语言模型作为优化器,其工作流程如下:
- 初始化:大语言模型随机生成数千个初始面板,计算损失值,并从中选取一个多样化的面板集合作为“历史面板向量” $[P_1, P_2, …]$。
- 智能迭代:在每一轮优化中,大语言模型被要求基于“历史面板向量”生成10个新的面板。大语言模型被允许在一次修改中同时更改1到3个扩增子的引物选择,这赋予了它更强的全局探索能力。
- 记忆与筛选:计算新面板的损失值。如果某个新面板的损失低于历史记录中的某个面板,则将其加入历史向量,并移除表现最差的面板。
- 性能对比:在 78重面板的优化任务 中,经过750次迭代,大语言模型优化器展现出了优于AdaLead和遗传算法的优化效率,最终达到与贪婪算法相近的损失值水平。这表明大语言模型在处理此类高维组合优化问题上具有独特优势。
多轮次重设计:
它能根据湿实验的反馈(如测序数据的覆盖度、均匀性、二聚体率)对引物面板进行单扩增子或全面板的重设计,形成“设计-实验-优化”的闭环。
这是引物智能体区别于传统“一次性”设计工具的关键功能。它能够消化吸收湿实验(测序)的结果,智能地指导下一轮设计。
- 输入指标:系统读取测序报告中的关键指标,包括:
- 靶向率 (MTR, Mapping Target Rate):比对到目标区域的reads比例。
- 均匀性 (0.1× Uniformity):有多少区域的测序深度高于平均深度的0.1倍。
- 二聚体率 (Dimer Rate):长度短于70 bp的reads比例。
- 单扩增子靶向率 (SMTR):每个扩增子单独的表现。
- 单扩增子重设计:针对表现不佳的单个扩增子,系统采取精准策略:
- 二聚体高:遍历该扩增子候选池中的所有引物对,选择能最小化整体面板二聚体损失的那一对。
- 特异性低 (SMTR低):增加损失函数中 BLAST得分 的权重,重新选择特异性更强的引物。
- 均匀性差 (非以上原因):调整引物的GC含量或长度范围,改善其模板结合效率。
- 全面板重设计:当面板整体表现低于预设阈值(如MTR < 90%,二聚体率 > 5%),系统会触发全面板重设计。它会自动排除那些在上一轮实验中reads数极低(<平均深度0.05倍)的区域,并禁止滑动窗口跨越这些区域,从而重构一个更优的面板。
特异性保障:BLAST的深度集成
在整个设计和重设计过程中,引物特异性是通过与BLAST的紧密集成来保障的。
- 背景数据库:用户可以提供一个自定义的BLAST数据库(如人类基因组、特定菌群基因组),作为脱靶评估的“背景噪音”。
- 动态权重调整:如前所述,BLAST得分是损失函数的重要组成部分。当需要提升特异性时,系统可以动态增加BLAST得分的权重,迫使优化过程优先选择与非目标区域匹配度低的引物。
3. 协议智能体 (Protocol Agent)
- 功能:将引物智能体输出的引物列表,自动转化为可在液体处理机器人上执行的实验方案。
- 核心技术:利用检索增强生成 (RAG) 技术。它将复杂的建库流程分解为一系列 “可调协议代码块 (APBs)”。通过匹配用户所选建库试剂盒的步骤,检索最匹配的代码块,并由大语言模型根据样本量、引物特性等计算具体的实验参数(如试剂体积、PCR循环数),最终生成可执行的Python脚本。
4. 实验智能体 (Experiment Agent)
- 功能:在自动化实验过程中进行实时监控和异常检测,充当系统的“眼睛”。
- 硬件:集成三台摄像头,分别监控台面布局、移液吸头状态和孔板底部。
- 核心技术:使用经过两阶段微调的视觉语言模型 (VLM) 对实时视频流进行分析。它能识别吸头安装错误、孔板摆放错误、磁珠混合不均等问题。发现问题后,系统会尝试自我修复(如调整移液参数重试),失败时再请求人工干预。
性能表现:多场景下的实验验证
PrimeGen在四种典型的靶向测序应用场景中进行了湿实验验证,展示了其强大的性能:
- SARS-CoV-2 全基因组测序:设计了 131重 引物面板。在100拷贝/μL浓度下,基因组覆盖度达 98.7%,优于ARTIC v5.3.2 (91.2%) 和 PrimeGen-Primer3 (97.1%),与PrimalScheme (98.9%) 相当。
- 扩展性携带者筛查 (ECS) panel:针对人类基因组,设计了覆盖35个疾病相关基因外显子的 955个扩增子 (1910条引物)。湿实验结果显示,97.85% 的编码序列(CDS)区域测序深度超过30×,二聚体率仅 1.77%。
- 结核分枝杆菌 (MTB) 耐药检测:针对1200个耐药相关SNP位点设计了引物面板。第二轮优化后的面板(131重)实现了 88.8% 的靶向率 和 91.9% 的均匀性,SNP区域覆盖度在30×深度下达 97.9%。同时开发的24重物种鉴定panel能有效区分MTB与其他12种分枝杆菌。
- 酶突变体质粒测序:为四种酶(Luc, KODm, Cid1, TdT)设计了引物面板。针对TdT面板的“单扩增子重设计”,将其30×深度下的目标区域覆盖率从 94.7% 提升至 100%。
方法依赖情况:软件与工具
PrimeGen的运行依赖于多个成熟的软件工具和数据库,体现出现代生物信息学工具链的集成特征。
| 类别 | 依赖的工具/数据库 | 用途 |
|---|---|---|
| 核心模型与框架 | GPT-4o (控制器), 多种视觉语言模型 (Qwen2-VL, Phi-3.5等), ms-swift (微调框架), vLLM (推理引擎) | 智能体协作、意图理解、代码生成、异常检测 |
| 序列分析与比对 | BLAST+, MAFFT, MUSCLE, Biopython | 序列检索、多重比对、相似性搜索、特异性评估 |
| 引物设计核心 | Primer3, SADDLE算法, PrimalScheme | 引物候选生成、二聚体损失计算、面板优化 |
| 数据质控与处理 | fastp, cutadapt, BWA | 测序数据质控、去接头、比对 |
| 专业数据库 | NCBI, OMIM, COSMIC, ClinVar, UniProt, WHO, CARD, SILVA, Gencode | 目标序列、变异信息、分类学信息、耐药基因等数据源 |
横向比较:PrimeGen vs. 其他工具
文章在引言和讨论部分,将PrimeGen与现有工具进行了定性比较,指出了它们的局限性,并在SARS-CoV-2实验中与ARTIC和PrimalScheme进行了定量对比。
- vs. 传统引物设计工具 (如PMPrimer, Primer3, DECIPHER等):
- PrimeGen的优势:不仅仅是设计引物,而是构建了一个从需求理解到实验执行的完整自动化工作流。它引入了大语言模型的语义理解、多智能体协作、自我反思和持续优化能力,这是传统工具所不具备的。
- vs. 其他大语言模型科学智能体 (如Coscientist, ChemCrow):
- 定位不同:Coscientist等主要面向化学合成。PrimeGen是首个专注于靶向测序引物设计这一高度复杂生物学任务的专用智能体系统,并成功集成了视觉语言模型进行实验监控,实现了更深入的实验闭环。
- vs. 现有引物面板优化算法 (SADDLE, 贪婪算法, 遗传算法):
- 创新点:在 78重优化任务 中,PrimeGen提出的 大语言模型优化器 在优化效率上显著优于AdaLead和遗传算法,最终损失值可与贪婪算法媲美,但探索路径不同(一次改变多个变量)。这展示了大语言模型在处理高维组合优化问题上的潜力。
总结
PrimeGen 将引物序列设计嵌入到检索—设计—协议—实验监控的闭环中;与传统工具相比,更强调 LLM 语义理解、多智能体分工与湿实验反馈。部署与运维成本(模型/API、机械臂与视觉)需结合实际评估。
局限性
- 模型依赖:GPT-4o 等闭源 API 的可用性、价格、条款与可复现性(温度、版本)影响科研审计。
- 幻觉与工具调用错误:自然语言理解与代码生成链路长,需人工复核引物序列与机器人参数。
- 生物学假阴/假阳:BLAST / SADDLE / 滑动窗口 与湿实验条件(聚合酶、Mg²⁺、循环数)仍可能不一致。
- 硬件与集成:液体处理 + 多摄像头 VLM 非通用基础设施,失败时回退成本高。
- 与传统工具对比:见论文讨论;非所有场景都需要 PrimeGen 级别复杂度。
参考资料
- Wang Y, et al. Nat Biomed Eng 2025. https://doi.org/10.1038/s41551-025-01455-z
- PrimeGen GitHub. https://github.com/melobio/PrimeGen
- PubMed. https://pubmed.ncbi.nlm.nih.gov/40738975/