← 上级:RL-03.算法分类与选型 · 前置:RL-03-10-算法-TRPO · 数据结构:RL-05 Rollout Buffer
近端策略优化(Proximal Policy Optimization,PPO)(Schulman et al., 2017)通过限制策略更新幅度,在实现简单性与稳定性之间取得平衡,是 OpenAI、Stable-Baselines3 等的默认 On-Policy 基线。
段末注释:近端策略优化(Proximal Policy Optimization,PPO)用裁剪替代 KL 硬约束,限制新旧策略概率比;后文沿用 PPO。
一、从 TRPO 到 PPO
TRPO 用 KL 散度约束 $\text{KL}(\pi_{\theta_{old}} | \pi_\theta) \leq \delta$,保证单调改进,但共轭梯度 + 线搜索实现复杂。
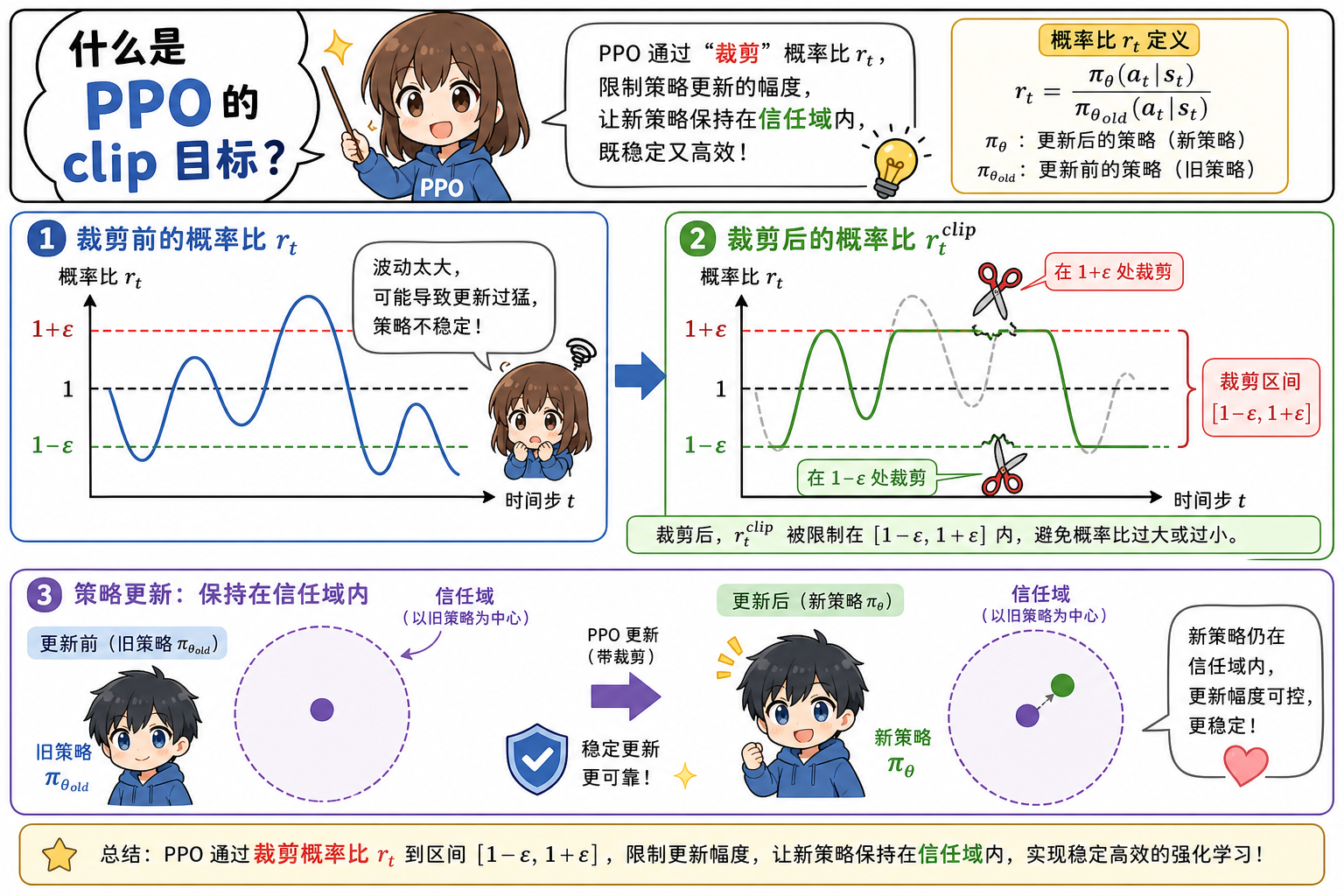
PPO 用裁剪实现类似「信任域」效果,仅一阶优化。
二、概率比与 Surrogate 目标
$$
r_t(\theta) = \frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{old}}(a_t|s_t)}
$$
无约束 surrogate:
$$
L^{CPI}(\theta) = \mathbb{E}_t \left[ r_t(\theta) \hat{A}_t \right]
$$
PPO-Clip:
$$
L^{CLIP}(\theta) = \mathbb{E}_t \left[ \min\left( r_t(\theta) \hat{A}_t, ; \text{clip}(r_t(\theta), 1-\epsilon, 1+\epsilon) \hat{A}_t \right) \right]
$$
- $\hat{A}_t > 0$:限制 $r_t$ 过大(防止过度增强该动作)
- $\hat{A}_t < 0$:限制 $r_t$ 过小
常用 $\epsilon = 0.2$。
三、完整损失(Actor-Critic)
$$
L = -L^{CLIP} + c_1 \mathcal{L}^{VF} - c_2 \mathcal{H}[\pi_\theta]
$$
| 项 | 含义 |
|---|---|
| $L^{CLIP}$ | 策略损失 |
| $\mathcal{L}^{VF} = (V_\theta(s_t) - V_t^{target})^2$ | 价值函数 MSE |
| $\mathcal{H}$ | 熵 bonus,鼓励探索 |
四、GAE 优势估计
广义优势估计(Generalized Advantage Estimation,GAE):
$$
\hat{A}t = \sum{l=0}^{\infty} (\gamma \lambda)^l \delta_{t+l}, \quad \delta_t = r_t + \gamma V(s_{t+1}) - V(s_t)
$$
$\lambda \in [0,1]$:0 接近 TD(0),1 接近 MC。常用 $\lambda=0.95$。
段末注释:广义优势估计(Generalized Advantage Estimation,GAE)在偏差与方差之间插值估计优势函数;后文沿用 GAE。
五、训练流程
- 用 $\pi_{\theta_{old}}$ 收集 Rollout 长度 $T$(如 2048 步)
- 算 $V(s_t)$、$\hat{A}_t$、returns
- 对同一批数据做 $K$ 个 epoch mini-batch 更新(如 $K=10$)
- $\theta_{old} \leftarrow \theta$,重复
数据存于 Rollout Buffer,不复用旧策略数据(On-Policy)。
六、超参数(SB3 默认量级)
| 超参 | 典型 |
|---|---|
| Rollout 步数 | 2048 |
| Batch / epoch | 64 × 10 |
| $\gamma$ | 0.99 |
| GAE $\lambda$ | 0.95 |
| Clip $\epsilon$ | 0.2 |
| 学习率 | 3e-4 |
| 熵系数 $c_2$ | 0.01 |
| 价值系数 $c_1$ | 0.5 |
七、PPO 优缺点
| 优点 | 缺点 |
|---|---|
| 实现简单、调参鲁棒 | On-Policy,样本效率一般 |
| 离散/连续统一 | 大量 epoch 可能过拟合小 batch |
| 工业界广泛使用 | 极长 horizon 任务仍难 |
八、小结
- PPO = Clip surrogate + GAE + 多 epoch 小批量更新。
- 工程首选 On-Policy 算法;连续控制也可试 SAC。
- 相关:Actor-Critic