← 系列入口:RL-00.系列概述 · 相关:RL-04.实现框架与实践
监督学习常见 Dataset + DataLoader;RL 则反复出现几类与 MDP 交互强绑定的结构。理解它们的语义、内存布局与选型,读 DQN/PPO 源码和写自研训练器会轻松很多。
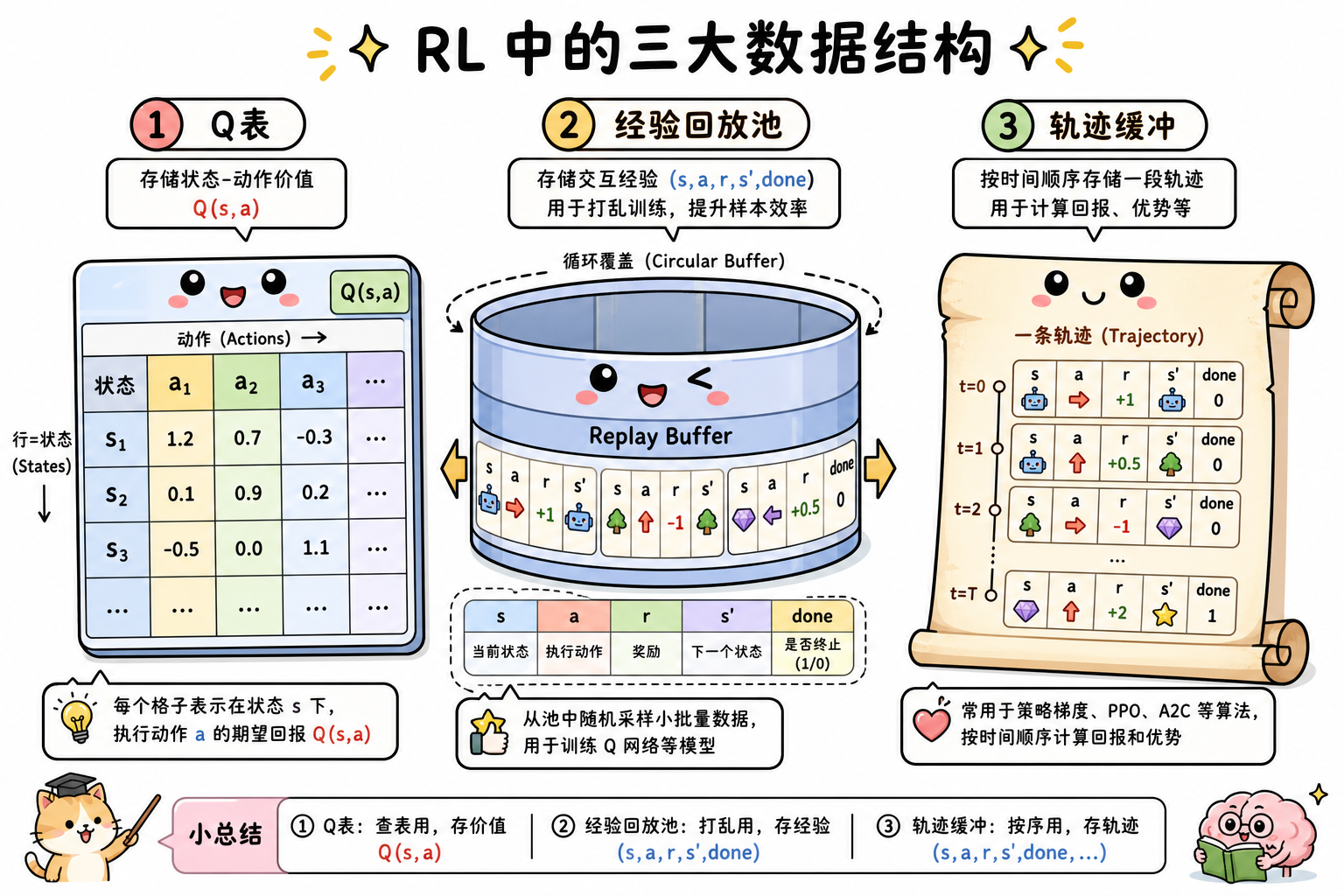
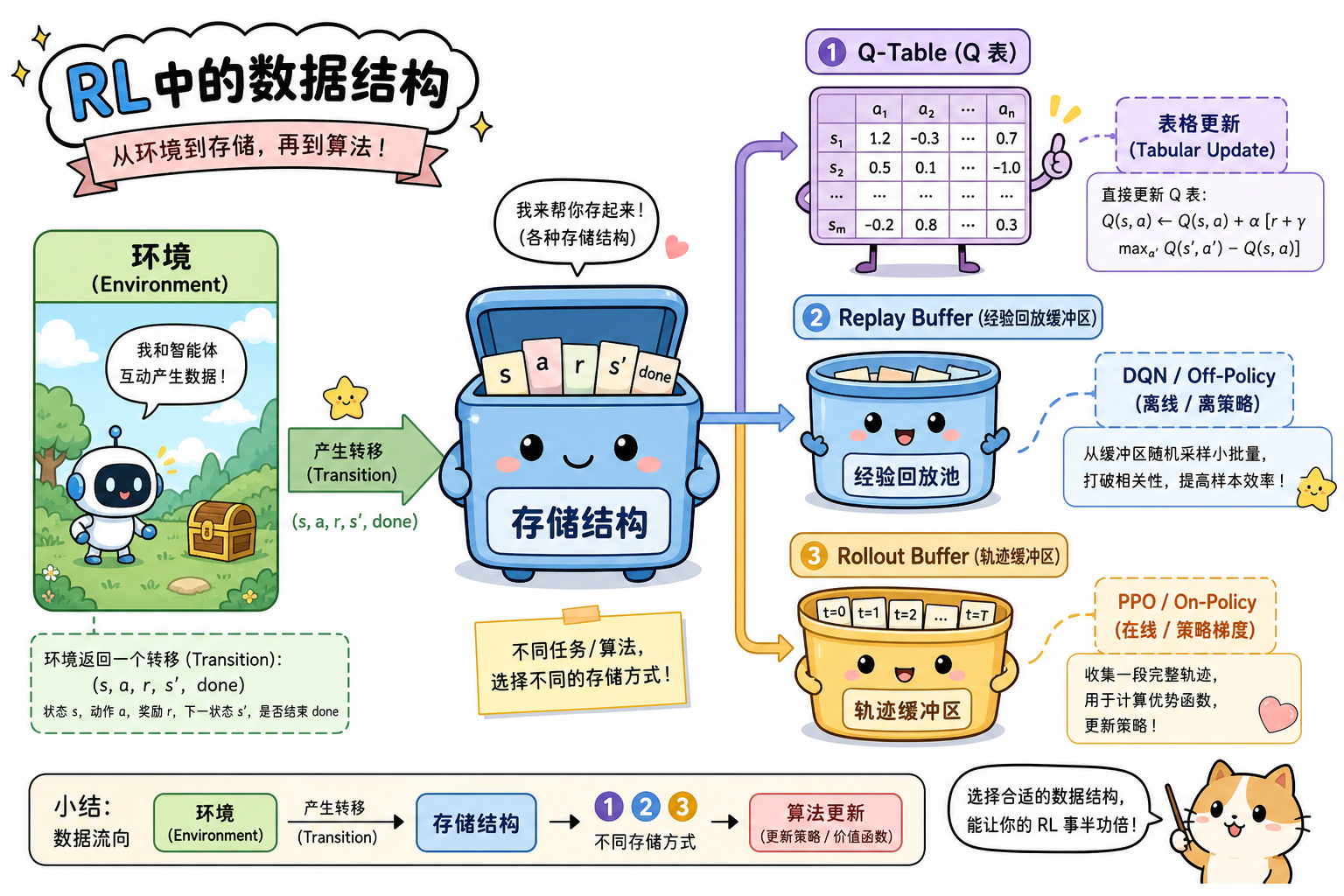
一、总览:结构与环境
| 结构 | 典型算法 | 核心用途 |
|---|---|---|
| Q-Table | Q-Learning、SARSA | 离散 $S \times A$ 查表 |
| Replay Buffer | DQN、DDPG、SAC | 打破时序相关、重复利用样本 |
| Rollout Buffer | A2C、PPO | 存当前策略整条轨迹 |
| Prioritized Replay | PER、Rainbow | 优先学习 TD 误差大的样本 |
| Eligibility Trace | TD($\lambda$) | 多步信用分配 |
| 策略输出缓冲 | PPO、SAC | 存 logits / $\mu,\sigma$ 等 |
二、Transition 元组(统一字段约定)
最小 transition(或 experience):
$$
(s_t,, a_t,, r_{t+1},, s_{t+1},, \text{done})
$$
| 字段 | 类型 | 说明 |
|---|---|---|
s |
向量/离散索引 | 当前观测或状态 |
a |
int / 向量 | 动作 |
r |
float | 即时奖励 |
s' |
同 s |
下一状态 |
done |
bool | 终止(episode 结束) |
扩展字段(按算法需要):
| 字段 | 用于 |
|---|---|
log_prob |
PPO、策略梯度 |
value |
Actor-Critic、GAE |
advantage |
PPO 更新 |
hidden |
RNN/POMDP |
truncated |
Gymnasium 超时截断 |
约定:全系列实现统一用 (s, a, r, s', done) 命名,扩展放 dict 或 namedtuple。
三、Q-Table
定义:$Q \in \mathbb{R}^{|S| \times |A|}$,单元 $Q[s,a]$ 表示在 $s$ 选 $a$ 的估计动作价值。
| 方面 | 说明 |
|---|---|
| 索引 | $s$ 为整数 id 或 hash(离散化状态) |
| 初始化 | 常 0 或 Optimistic 初值促探索 |
| 更新 | TD:$Q[s,a] \leftarrow Q[s,a] + \alpha \delta$ |
| 复杂度 | 空间 $O( |
| 实现 | NumPy 二维数组;可用 defaultdict 稀疏 |
与原理对应:表格即 $Q^\pi(s,a)$ 的显式存储,见 RL-02。
二级篇:RL-05-02-结构-Q-Table.md。
四、Replay Buffer(经验回放)
动机:连续 transition 高度相关;随机 mini-batch 更接近 i.i.d.,稳定 SGD。
结构:固定容量环形队列,FIFO 覆盖最旧样本。
1 | buffer: [(s,a,r,s',done), ...] 容量 N |
| 参数 | 典型值 |
|---|---|
| 容量 $N$ | $10^5$ ~ $10^6$ |
| batch | 32 ~ 128 |
| 预热 | 先收集若干步再更新 |
变体:
- n-step return:存 n 步累积奖励
- Frame stacking:Atari 存连续 4 帧
- Hindsight Experience Replay(HER):目标条件 RL,改目标重标奖励
二级篇:RL-05-03-结构-Replay-Buffer.md。
五、Prioritized Replay(优先经验回放)
按 TD 误差 $|\delta|$ 分配采样优先级:
$$
P(i) \propto (|\delta_i| + \epsilon)^\alpha
$$
用 重要性采样权重 $w_i$ 修正分布偏移($\beta$ 退火至 1)。
| 优点 | 缺点 |
|---|---|
| 样本效率更高 | 实现复杂;需 sum-tree 等 $O(\log N)$ 结构 |
| 难样本被多练 | 超参 $\alpha,\beta$ 敏感 |
二级篇:RL-05-04-结构-Prioritized-Replay.md。
六、Rollout / Trajectory Buffer
On-Policy 算法(PPO、A2C)在当前策略下收集一整段轨迹再更新,通常清空不复用旧策略数据。
典型字段(每步一条记录):
| 字段 | 用途 |
|---|---|
obs, action, reward, done |
基础 |
log_prob |
策略比率 $\pi/\pi_{old}$ |
value |
Critic 输出 |
advantage, returns |
GAE 计算后写入 |
GAE(Generalized Advantage Estimation)在 Rollout 上反向扫描算 $\hat{A}_t$。
空间:$O(T \cdot \text{dim})$,$T$ 为 rollout 长度(如 2048)。
二级篇:RL-05-05-结构-Rollout-Buffer.md。
七、Eligibility Trace(资格迹)
用于 TD($\lambda$):对最近访问的 $(s,a)$ 分配指数衰减信用。
向量 $e(s,a)$ 与 TD 误差 $\delta_t$ 配合:
$$
Q(s,a) \leftarrow Q(s,a) + \alpha \cdot \delta_t \cdot e(s,a)
$$
表格型中小状态空间可用;深度 RL 中较少直接实现,思想与 GAE($\lambda$ 参数)相通。
二级篇:RL-05-06-结构-资格迹.md。
八、策略输出的参数化存储
| 动作类型 | Actor 输出 | 存储内容 |
|---|---|---|
| 离散 | logits | softmax → 分布;log_prob(a) |
| 连续 | $\mu, \sigma$ | 高斯采样;tanh squash 到有界动作 |
| SAC | 重参数化 | mean, log_std, sample |
PPO 更新需保留 old_log_prob 以算 ratio $r_t(\theta) = \exp(\log\pi_\theta - \log\pi_{\theta_{old}})$。
二级篇:RL-05-07-结构-策略输出.md。
九、选型决策树
1 | 状态空间小且离散? |
| 场景 | 推荐结构 |
|---|---|
| 教学迷宫 | Q-Table |
| Atari / 离散控制 DQN | Replay + 帧栈 |
| 机器人 PPO | Rollout + GAE |
| 连续控制 SAC | Replay + 双 Q |
十、复杂度与内存粗算
| 结构 | 空间 | 采样 |
|---|---|---|
| Q-Table | $ | S |
| Replay | $N \times \text{size(transition)}$ | $O(\text{batch})$ 均匀随机 |
| Prioritized | 同上 + 树 | $O(\log N)$ |
| Rollout | $T \times \text{fields}$ | 顺序扫描 |
十一、本模块二级文档(已发布)
| 文档 | 内容 |
|---|---|
| RL-05-01-结构-Transition元组 | 字段标准 |
| RL-05-02-结构-Q-Table | 稠密/稀疏 Q 表 |
| RL-05-03-结构-Replay-Buffer | 环形队列 |
| RL-05-04-结构-Prioritized-Replay | PER / SumTree |
| RL-05-05-结构-Rollout-Buffer | GAE、PPO |
| RL-05-06-结构-资格迹 | TD($\lambda$) |
| RL-05-07-结构-策略输出 | 离散/连续分布 |
十二、阅读顺序
- 实现循环:RL-04.实现框架与实践
- 算法对应:RL-03.算法分类与选型
- 评估环境:RL-06.评估环境与工具链
十三、小结
- Transition 是 universal 原子;Q-Table / Replay / Rollout 是三种典型聚合。
- Off-Policy → Replay;On-Policy → Rollout;小空间 → Q-Table。
- 读源码时先找「数据存在哪、何时 sample、字段有哪些」。