在生物信息学项目中选型「基础模型(Foundation Model)」时,常见困惑不是「哪个模型最新」,而是「它属于哪类架构范式」——同一任务下,自回归 Transformer、掩码编码器、状态空间模型(State-Space Model,SSM)、图神经网络(Graph Neural Network,GNN) 与 扩散模型(Diffusion Model) 的归纳偏置、上下文长度、训练目标与推理成本差异巨大。本文作为 5003.大模型-架构 系列的总览入口,按四个正交维度梳理当前主流范式,列出代表实现,并映射到 DNA/RNA、蛋白质、分子与单细胞等场景;各子主题的算法细节见本目录专题文章。
段末注释:Foundation Model 指在大规模无标注或弱标注数据上预训练、可迁移至多种下游任务的模型;归纳偏置指架构先验地偏好某类函数或不变性,影响样本效率与外推。
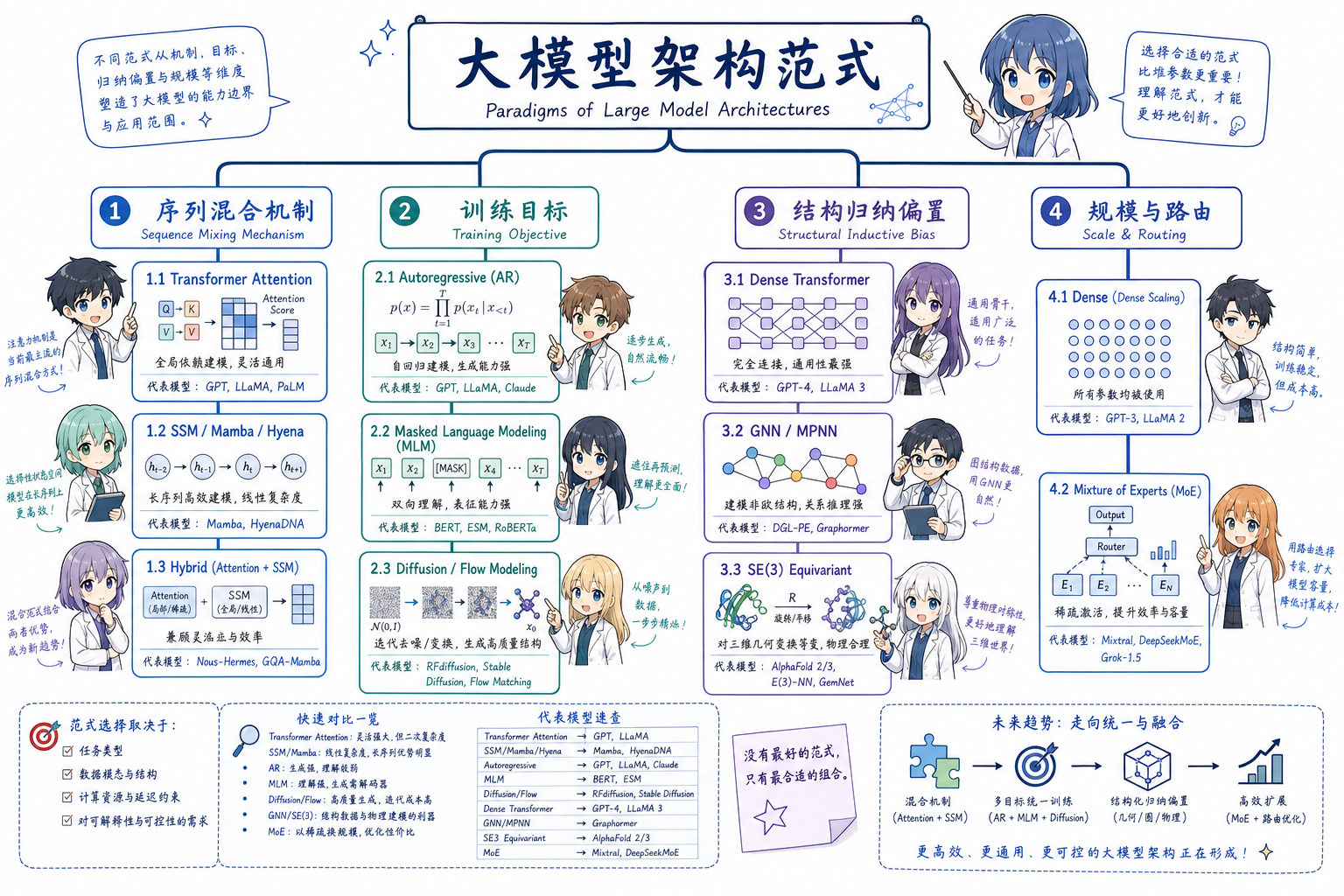
1. 如何读一张「架构范式地图」
大模型架构可从四个相对独立的维度理解(见图 1):
| 维度 | 回答的问题 | 典型选项 |
|---|---|---|
| 序列混合机制 | 信息如何在序列/图上传播? | 自注意力、SSM/卷积、混合、消息传递 |
| 训练目标 | 模型学什么分布/表示? | 自回归(AR)、掩码语言建模(MLM)、对比学习、扩散/流 |
| 结构归纳偏置 | 如何利用领域对称性/拓扑? | plain Transformer、图结构、SE(3)/E(3) 等变 |
| 规模与路由 | 参数如何组织与激活? | 稠密(Dense)、混合专家(Mixture of Experts,MoE) |
同一产品名可能跨维度组合:例如 Evo = SSM 混合 + AR;RFdiffusion = Transformer 骨干 + 扩散目标 + 结构等变;DeepSeek-V3 = MoE + AR Transformer。
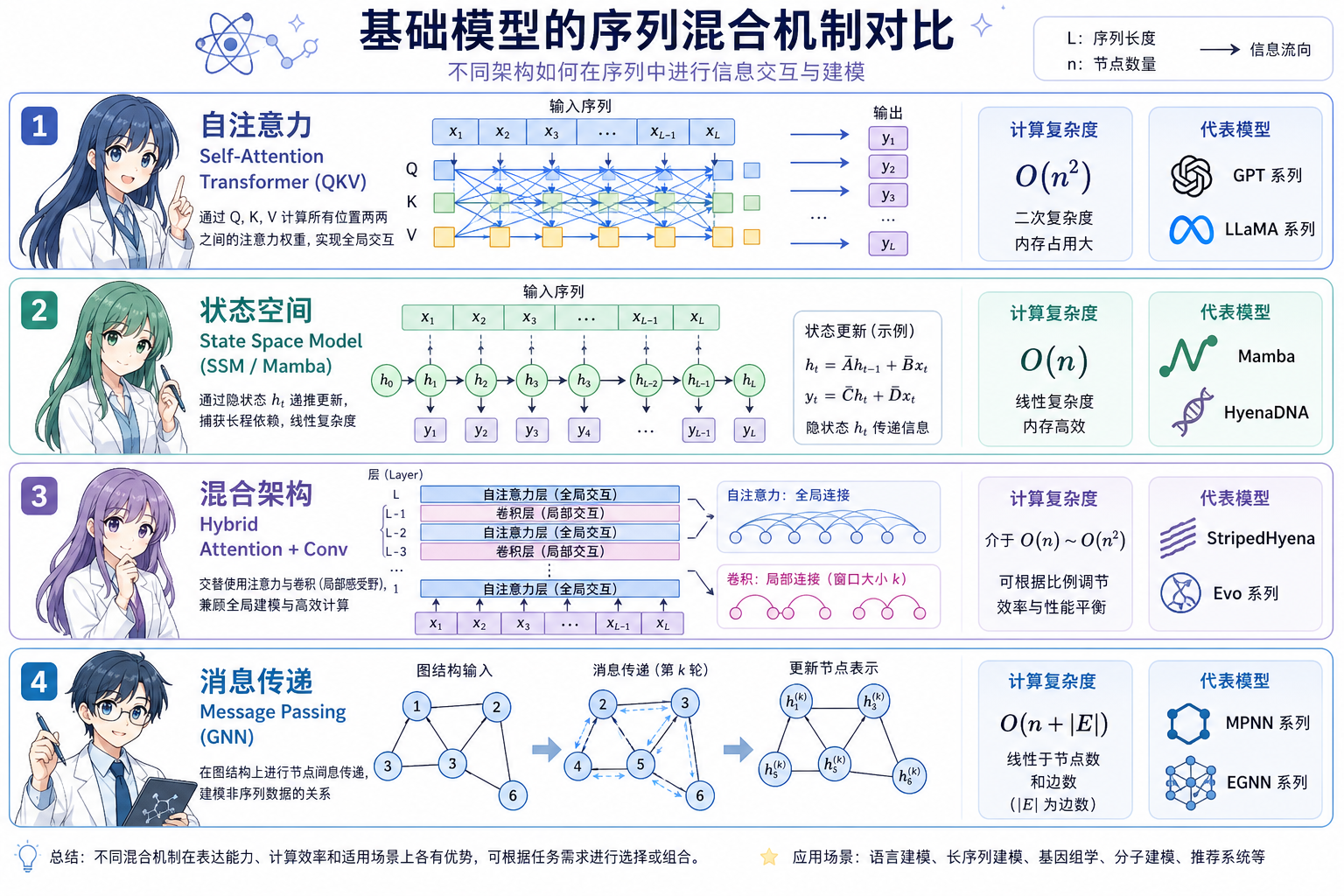
2. 范式一:自注意力 Transformer 族
核心机制:每个 token 通过 Query-Key-Value(QKV) 与全局(或窗口内)token 计算注意力权重,实现内容依赖的软路由;复杂度对序列长度 (L) 通常为 (O(L^2))(全注意力)或 (O(Lw))(窗口 (w))。
2.1 解码器-only + 自回归(Decoder-only AR)
- 训练目标:(p(x)=\prod_i p(x_i\mid x_{<i})),下一 token 交叉熵。
- 代表实现:
- 通用 LLM:GPT 系列、LLaMA / LLaMA 3、Qwen、DeepSeek(见 DeepSeek 概述)
- 生物序列:ProGen / ProGen2(蛋白质 AR)、Evo / Evo 1.5(基因组 AR + 长上下文混合骨干)
- 优势:生成自然;KV Cache 使自回归推理高效;生态(HuggingFace、vLLM)成熟。
- 局限:双向上下文需另训;全注意力长序列预填充贵;因果掩码限制「全局一次看清」。
生物信息学典型用途:蛋白质/引物/密码子优化序列生成、LLM 式基因组补全、Agent 工具链中的推理主干。
2.2 编码器-only + MLM(Encoder-only)
- 训练目标:随机遮盖 token,预测被遮盖内容(Masked Language Model,MLM)。
- 代表实现:
- 通用:BERT、RoBERTa
- 蛋白质:ESM-2、ESM-C
- DNA/RNA:DNABERT、DNABERT-2、Nucleotide Transformer(见 DNABERT 选型指南)
- 优势:双向上下文,嵌入质量高;适合分类、回归、变异效应、启动子/剪接预测。
- 局限:原生非生成器(需迭代 mask 或另接解码头);最大长度受训练窗口限制。
2.3 编码器–解码器(Encoder–Decoder)
- 训练目标:序列到序列(Seq2Seq),如 span corruption(T5)或 denoising(BART)。
- 代表实现:T5 / Flan-T5、BART;生物:ProtT5(蛋白质序列↔注释)、部分 AlphaFold 模块中的 pair/stack 思想。
- 优势:统一「理解 + 生成」;条件生成(序列翻译、注释生成)友好。
- 局限:推理常比 decoder-only AR 慢;大规模预训练以 decoder-only 为主流后,相对式微但仍活跃于特定任务。
2.4 工程变体(仍属 Transformer 族)
| 变体 | 作用 | 代表 |
|---|---|---|
| GQA / MQA | 减少 KV 头,省缓存 | LLaMA 2/3、StripedHyena 的注意力块 |
| RoPE / ALiBi | 相对位置外推 | 多数现代 LLM |
| Sliding Window | 局部注意力降复杂度 | Mistral、部分长文本模型 |
| Ring Attention | 分布式长上下文 | 训练级系统优化 |
本目录延伸:Transformer 概述 → Pipeline → Model → Tokenizer
3. 范式二:亚线性序列混合(SSM / Hyena / 线性注意力)
动机:全注意力在 (L>32\text{k}) 时预填充与显存成为瓶颈;DNA 整染色体、长读长、多物种比对等需要 (O(L)) 或 (O(L\log L)) 混合算子。
3.1 状态空间模型(SSM)
- 机制:隐状态 (h_t = A h_{t-1} + B x_t),输出 (y_t = C h_t);长卷积等价形式,用递推或 FFT 实现亚二次计算。
- 代表实现:S4、Mamba、Mamba-2、Jamba 中的 Mamba 块;基因组 Caduceus(双向 SSM)。
- 优势:长序列训练/解码渐近线性;常数大小状态,缓存友好。
- 局限:联想回忆(associative recall) 弱于注意力;纯 SSM 栈在部分合成任务上落后 hybrid。
3.2 Hyena 与门控长卷积
- 机制:多阶门控隐式卷积,用 FFT 实现大范围依赖;可视为 attention 的 subquadratic 替代。
- 代表实现:Hyena、HyenaDNA(131k 单碱基上下文)、StripedHyena(注意力 + Hyena 交替,见 StripedHyena 介绍)、Hyena 原理笔记。
- 优势:长 DNA 建模;与少量注意力层混合后接近 Transformer 质量。
- 局限:实现依赖 CUDA 内核;超参(Hyena 阶数、层配比)调优门槛高。
3.3 其他亚二次方案
| 方案 | 代表 | 备注 |
|---|---|---|
| 线性注意力 / RetNet | RetNet、Based | 核技巧或 retention 机制 |
| RWKV | RWKV-6 | RNN 形式 + 时间混合,推理极快 |
| 混合栈 Hybrid | Jamba、Zamba、Griffin、Evo | 交替 Attention + SSM/Conv |
选型直觉(基因组):(L<512) bp 调控元件 → **DNABERT/NT**;(L>10) kb 系上下文 → HyenaDNA / Caduceus / Evo。
4. 范式三:混合专家(MoE)
机制:前馈层由 (N) 个「专家(Expert)」子网络组成,门控网络(Router) 对每个 token 激活 Top-(k) 个专家;总参数量大但每 token 激活参数量(active params) 可控。
- 代表实现:Switch Transformer、Mixtral 8×7B、DeepSeek-V2/V3、DBRX;生物领域 MoE 专用基础模型仍少,但通用 LLM + 领域微调/RAG 常见。
- 优势:固定推理 FLOPs 下扩大模型容量;适合多任务路由。
- 局限:负载均衡、专家坍缩(见 概念解析-01);训练与部署复杂(EP 并行);生物小样本微调时 MoE 未必优于同 active 参数的 Dense。
段末注释:MoE 通过稀疏激活扩大参数量而不线性增加每 token 计算;EP 为 Expert Parallelism 专家并行。
5. 范式四:图与几何结构模型
当输入是分子图、蛋白接触图、知识图谱或三维坐标时,序列 Transformer 需强行展平,丢失对称性与拓扑。
5.1 消息传递神经网络(MPNN / GNN)
- 机制:节点–边局部消息传递 + 置换不变聚合(见 MPNN 概述)。
- 代表实现:GCN、GraphSAGE、GAT、SchNet、DimeNet;分子性质预测、口袋检测。
- 优势:天然处理 irregular 图;参数效率较高。
- 局限:(k) 层感受野仅 (k) 跳;长程依赖需深堆叠或 rewiring。
5.2 SE(3) / E(3) 等变网络
- 机制:网络输出随输入坐标旋转/平移(及反射)协变或不变。
- 代表实现:AlphaFold2(Evoformer + 结构模块)、ESMFold、OpenFold;分子 EGNN、Tensor Field Networks;生成侧 RFdiffusion、FrameDiff。
- 优势:三维结构任务的样本效率与物理合理性。
- 局限:实现与数据预处理复杂;全原子生成仍贵。
与 Transformer 关系:Evoformer、Pairformer 可视为在「残基对图」上的特化注意力;AlphaFold3 进一步统一 biomolecule 图建模。
6. 范式五:扩散与流匹配生成
机制:学习逐步去噪或向量场,从噪声采样数据(见 Diffusion 系列 0–5)。
| 子类 | 训练信号 | 代表 | 生物场景 |
|---|---|---|---|
| 连续扩散 DDPM/SDE | 去噪 MSE / 得分匹配 | Stable Diffusion、EDM | 分子 3D、蛋白骨架 |
| 离散扩散 D3PM | 分类去噪 | Diffusion-LM | DNA motif-flanking |
| 流匹配 Flow Matching | 向量场回归 | Rectified Flow、CFM | 结构/分子(新兴) |
| 潜扩散 LDM | 潜空间扩散 + VAE | Stable Diffusion、scDiff | 图像、单细胞扰动 |
- 代表实现(生物):RFdiffusion、Chroma(蛋白 design);GeoDiff(分子 3D);scDiff(单细胞 counterfactual)。
- 优势:训练稳定;inpainting 与条件生成强;多模态覆盖好。
- 局限:推理多步;需 DDIM/CFG 等工程技巧(第 3 篇)。
7. 范式六:对比学习与多模态统一
7.1 对比学习(Contrastive Learning)
- 机制:拉近正样本对、推远负样本;学习嵌入空间而非逐 token 生成。
- 代表实现:CLIP(图文)、DNABERT-S(DNA 物种感知嵌入,见 C2LR)、ProteinCLIP。
- 生物用途:检索、聚类、零样本分类、数据库搜索。
7.2 多模态基础模型
- 代表实现:ESM3(序列+结构+功能 token 统一)、AlphaFold3(多 polymer + 配体);通用侧 LLaVA、GPT-4V。
- 趋势:把序列、结构、文本、功能注释** token 化**进同一 Transformer 栈——范式上仍多为 AR 或 MLM + 多模态嵌入。
8. 范式对照总表
| 范式 | 混合/归纳偏置 | 主训练目标 | 代表(通用) | 代表(生物信息) | 推理特点 |
|---|---|---|---|---|---|
| Decoder AR Transformer | 全/窗注意力 | 下一 token CE | GPT-4、LLaMA 3 | ProGen2、Evo | 自回归,KV Cache |
| Encoder MLM | 双向注意力 | MLM | BERT | ESM-2、DNABERT-2 | 编码一次,非原生生成 |
| Encoder–Decoder | 交叉注意力 | Span/Seq2Seq | T5、BART | ProtT5 | 条件生成 |
| SSM / Mamba | 线性递推/卷积 | AR 或 MLM | Mamba-2 | Caduceus | 线性长序列 |
| Hyena / Hybrid | 门控卷积 + 注意力 | AR | StripedHyena | HyenaDNA、Evo | 长 DNA 友好 |
| MoE Transformer | 稀疏 FFN 路由 | AR | DeepSeek-V3、Mixtral | (通用 LLM 微调) | Active params ≪ total |
| GNN / MPNN | 图拓扑 | 监督/自监督 | — | SchNet、GCN 分子 | 图级/节点级 |
| SE(3) 等变 | 3D 对称 | 结构监督 | — | AlphaFold2、ESMFold | 一次前向折叠 |
| 扩散 / 流 | 多步马尔可夫/ODE | 去噪/流匹配 | Stable Diffusion | RFdiffusion、GeoDiff | 多步迭代 |
| 对比学习 | 嵌入空间 | InfoNCE 等 | CLIP | DNABERT-S | 编码 + 相似度 |
9. 时间线与范式演进
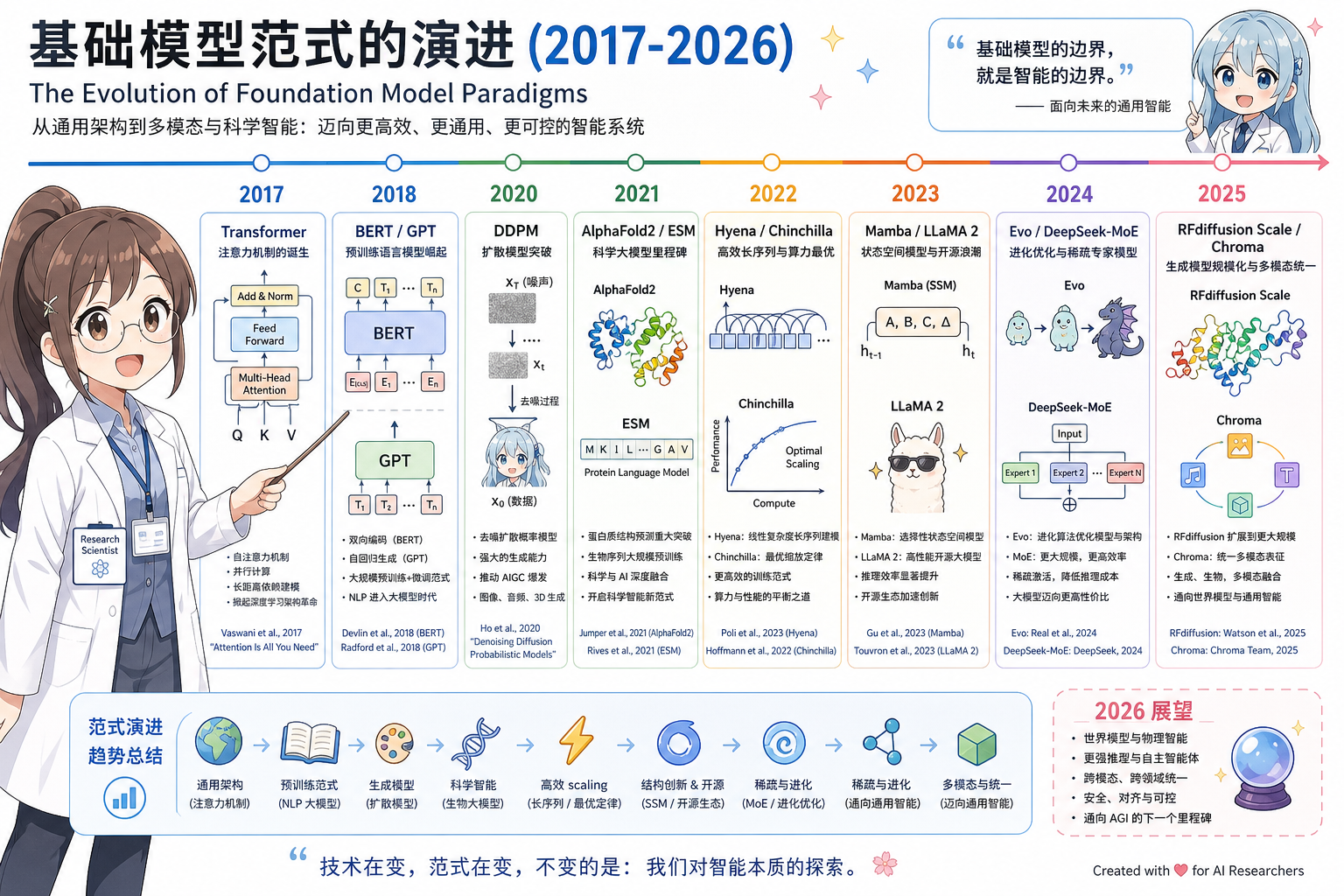
粗略阶段:
- 2017–2019:Transformer 确立;BERT/GPT 分叉「理解 vs 生成」。
- 2020–2021:DDPM 复兴生成;AlphaFold2 证明深度学习 + 等变注意力可解结构生物学核心问题;ESM 开启蛋白质语言模型。
- 2022–2023:Chinchilla 缩放律;Hyena/Mamba 挑战注意力垄断;LLaMA 降低开源门槛;Nucleotide Transformer / DNABERT-2 基因组基础模型爆发。
- 2024–2026:MoE 大规模商用(DeepSeek);Hybrid 成为长序列默认配方;Evo 跨尺度基因组生成;RFdiffusion/Chroma 结构 design 工业化;Flow Matching 与扩散并驾齐驱。
10. 生物信息学选型决策
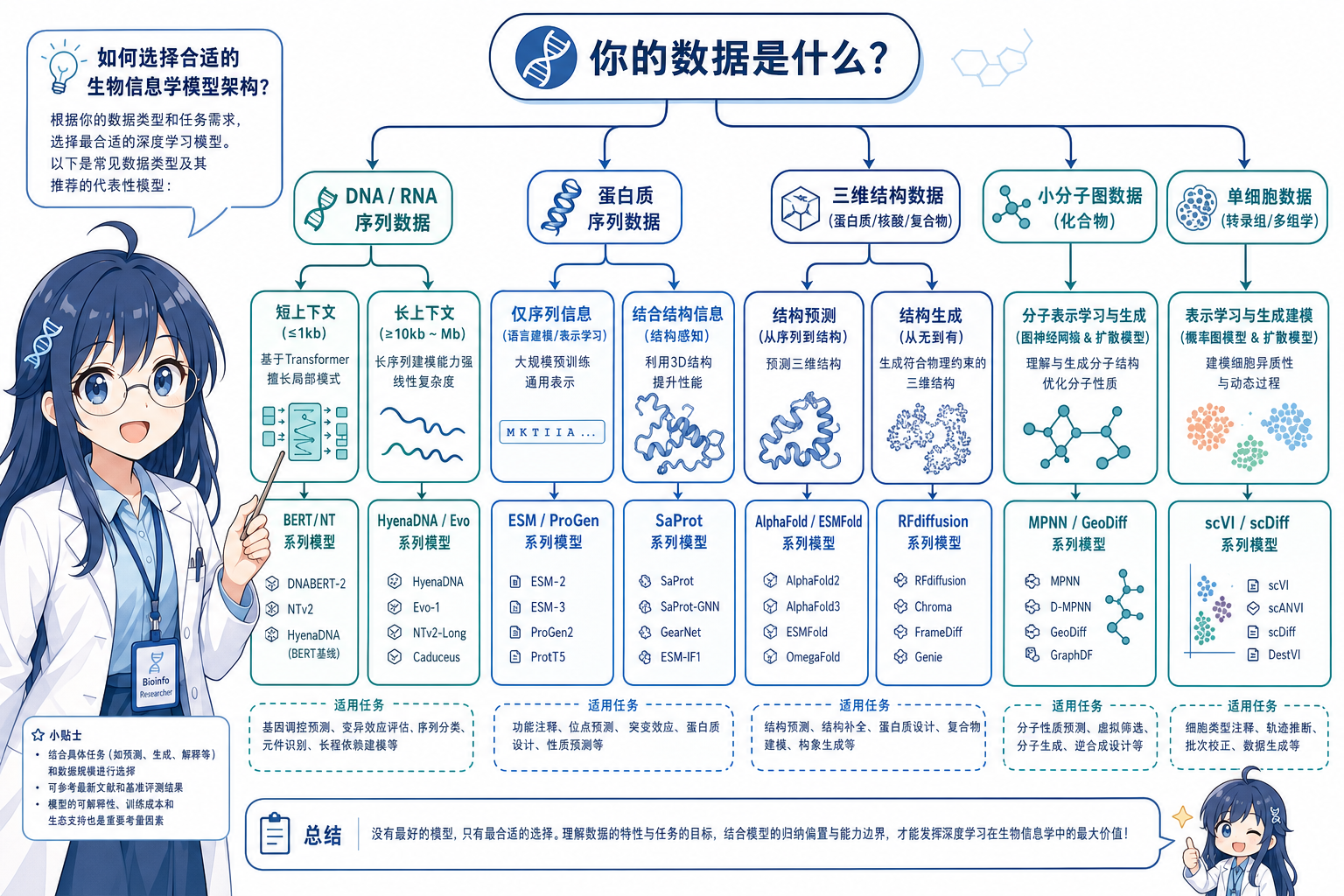
10.1 按数据形态
| 你的数据 | 首选范式 | 代表模型 | 本目录阅读 |
|---|---|---|---|
| 短 DNA/RNA 片段、变异 | Encoder MLM | DNABERT-2、NT | DNABERT 系列 |
| 长基因组、操纵子 | Hybrid SSM/AR | HyenaDNA、Evo、Caduceus | Hyena / StripedHyena |
| 蛋白质序列嵌入 | Encoder MLM | ESM-2 | — |
| 蛋白质序列生成 | Decoder AR | ProGen2、Evo(DNA 区段) | — |
| 结构预测(折叠) | 等变 Transformer | AlphaFold2、ESMFold | — |
| 结构 de novo design | 扩散 + 逆折叠 | RFdiffusion → ProteinMPNN | Diffusion 5 |
| 小分子 3D | E(3) 扩散 / GNN | GeoDiff、EDM | Diffusion + MPNN |
| 分子性质(图) | GNN | SchNet、GAT | MPNN |
| 单细胞扰动 | 潜扩散 / VAE | scDiff、scVI | Diffusion 0 |
| 物种聚类/检索 | 对比学习 | DNABERT-S | DNABERT-1 |
10.2 按任务类型
- 判别(分类/回归/嵌入) → Encoder MLM / GNN / 对比学习
- 生成(序列/结构) → AR 或 扩散(连续几何优先扩散)
- 条件 design(motif/binder) → 条件扩散 + CFG + inpainting
- 长上下文理解 → Hybrid SSM,而非纯 BERT
- 聊天/Agent/文献 → 通用 Decoder AR LLM + RAG(架构外检索层)
10.3 常见误区
- 「参数越大越好」 — Chinchilla 律:数据量、active params、训练 token 数需匹配;生物微调常小数据,过大模型易过拟合。
- 「用 GPT 直接做 DNA」 — 未在基因组预训练的 LLM 缺乏碱基分布先验;应选 GFM 或继续预训练。
- 「扩散一定优于 AR 做序列」 — 长序列 AR 生态更成熟;扩散优势在 3D、inpainting、多模态。
- 「忽视等变性与中心化」 — 结构坐标模型必须处理 SE(3) 与物理单位。
11. 本目录系列导读
| 系列 | 入口 | 覆盖范式 |
|---|---|---|
| Transformer | transformer-0.概述 | 自注意力、Encoder/Decoder |
| Hyena / StripedHyena | StripedHyena-0 | 门控卷积、混合栈 |
| DNABERT / 基因组 FM | DNABERT-0 | MLM、对比学习 |
| MPNN / GNN | MPNN-0、ProteinMPNN-0 | 图消息传递;逆折叠序列设计 |
| Diffusion | Diffusion-0 | 连续/离散扩散、结构 design |
| DeepSeek | DeepSeek-0 | MoE、工程优化 |
| LLM 概念解析 | 概念解析-0.系列导读 | 专家坍缩、过平滑等术语短文 |
建议路径:本文 → 按场景跳转对应系列 → 遇术语查 概念解析 → 需要部署时读 Transformer pipeline 篇。
12. 前沿趋势(2025–2026 观察)
- Hybrid 默认化:纯 Attention 或纯 SSM 栈减少;「少量注意力 + 大量 SSM/Conv」 成为长序列共识。
- Test-time compute:推理侧增加搜索/反思/多样本聚合(o1 类),架构与 AR 耦合而非替换。
- 统一 biomolecule 图:AlphaFold3、RoseTTAFold3 式「一张图建模多 polymer」挤压单任务专用架构空间。
- Flow + Diffusion 融合:训练稳定与步数减少并重。
- 生物专用 scaling law:基因组 token 与蛋白质结构 token 的最优参数量–数据量关系仍在校准,不可直接照搬 NLP Chinchilla 数字。
13. 小结
当前大模型架构并非「Transformer 一统天下」,而是多维范式并存:注意力擅长灵活关联;SSM/Hyena 攻克长 DNA;GNN/等变网络 编码拓扑与三维对称;扩散/流 支撑可控生成;MoE 在固定算力下扩容。生物信息学选型应先定数据形态与任务(判别 vs 生成 vs design),再选范式,最后挑具体 checkpoint——本文图 4 的决策树可作为团队讨论的第一张白板。
段末注释:GFM(Genome Foundation Model)指基因组预训练基础模型;RAG(Retrieval-Augmented Generation)为检索增强生成,非序列混合范式但在 Agent 系统中普遍与 AR LLM 组合。
参考与延伸阅读
- Vaswani et al., Attention Is All You Need(Transformer).
- Devlin et al., BERT;Brown et al., GPT-3(MLM vs AR).
- Gu & Dao, Mamba;Poli et al., Hyena Hierarchy(SSM / Hyena).
- Fedus et al., Switch Transformers(MoE).
- Gilmer et al., Neural Message Passing(MPNN).
- Jumper et al., AlphaFold2;Watson et al., RFdiffusion.
- Ho et al., DDPM;Liu et al., Flow Straight and Fast.
- Hoffmann et al., Training Compute-Optimal Large Language Models(Chinchilla).