课程对比学习(Curriculum Contrastive Learning,C²LR) 将「由易到难」的课程学习(Curriculum Learning)与对比学习(Contrastive Learning)结合:先在相对简单的对比锚点(anchor)上建立粗粒度判别能力,再逐步引入更困难的混合锚点,使嵌入空间对物种、类别或语义边界更加清晰。该策略在 DNABERT-S(Zhou et al., ICLR 2024)中用于从 DNABERT-2 出发学习 物种感知(species-aware) DNA 嵌入,在物种聚类、宏基因组分箱等任务上显著优于纯 MLM 预训练模型。
段末注释:对比学习 通过拉近正样本对、推远负样本对来学习表示;课程学习 按难度递增组织训练样本;锚点 指计算对比损失时作为参考中心的样本(或其表示)。
本文自基础概念讲起,给出 C²LR 的整体流程、两阶段损失、与相关方法(SimCLR、i-Mix)的差异,并附原理示意图。若需 DNABERT 全系列与数据选型背景,可参阅 DNABERT 预训练模型选型指南。
插图约定:下文 PNG 位于与本文同名的 Hexo 资源目录;正文图链仅写文件名(如 fig-c2lr-01-two-phases.png),部署后以 hexo server 页面为准。
1. 为什么需要 C²LR?
1.1 从 MLM 到对比嵌入
掩码语言建模(Masked Language Modeling,MLM) 预训练(如 DNABERT-2)擅长学习局部碱基上下文,但不直接优化「同物种序列靠近、异物种序列远离」这类全局几何结构。物种鉴定、宏基因组分箱等任务更依赖固定维度的序列嵌入及其在空间中的聚类结构。
对比学习通过构造 正样本对 $(x_i, x_i^+)$(语义相似)与 负样本(batch 内其余样本),显式塑造嵌入空间。难点在于:
- 困难负样本(hard negative):与锚点相似但标签不同的样本信息量大,应赋予更高权重;
- 锚点难度:若一开始就使用高度模糊的混合样本,模型难以收敛;
- DNA 离散性:在输入层直接 mixup 碱基序列缺乏生物学可解释性。
C²LR 的回应是:Phase I 用 Weighted SimCLR 打基础;Phase II 在隐层做 Manifold Instance Mixup(MI-Mix),逐步提高锚点难度。
1.2 核心思想一览
1 | flowchart LR |
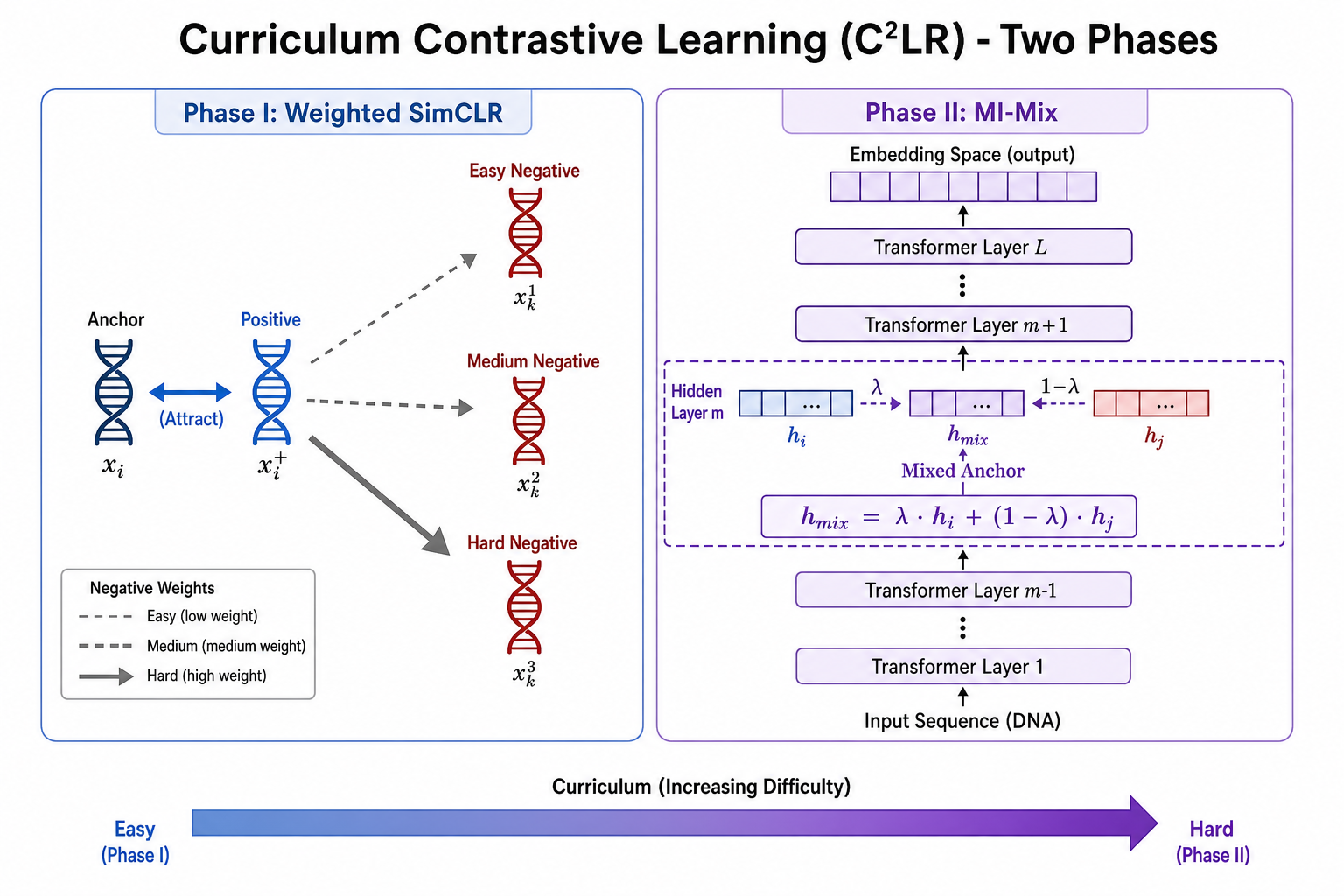
2. 背景知识
2.1 SimCLR 对比框架
SimCLR(Simple Framework for Contrastive Learning)在 batch 内对每个锚点 $x_i$:
- 正样本:增强视图 $x_i^+$;
- 负样本:同 batch 中其余 $2B-2$ 个样本($B$ 为 batch 大小);
- 目标:最大化 $\mathrm{sim}(f(x_i), f(x_i^+))$,最小化与负样本的相似度。
相似度常用 余弦相似度 $s(\mathbf{u},\mathbf{v}) = \mathbf{u}^\top \mathbf{v} / |\mathbf{u}||\mathbf{v}|$,并引入 温度系数(temperature) $\tau$ 缩放 logits:
$$
\ell_{\mathrm{SimCLR}}(i) = -\log \frac{\exp(s(f(x_i), f(x_i^+))/\tau)}{\sum_{j \neq i} \exp(s(f(x_i), f(x_j))/\tau)}
$$
段末注释:温度 $\tau$ 越小,模型越「挑剔」相似度细微差别;DNABERT-S 取 $\tau=0.05$。
2.2 课程学习
课程学习(Bengio et al., 2009;Hacohen & Weinshall, 2019)模仿人类学习:先学简单样本,再学复杂样本。在对比学习中,已有工作分别对 正样本对(Ye et al.)、负样本对(Chu et al., COCO)做课程调度。
C²LR 的创新点(DNABERT-S 论文强调):课程化对象不是单独的正/负 对,而是 对比锚点本身——从「真实序列表示」过渡到「隐层混合表示」,同时影响正负两类对比关系。
2.3 DNABERT-S 中的正样本对构造
与 NLP 中 dropout 双视图不同,DNABERT-S 使用 同物种、非重叠 的基因组片段:
$$
(x_i,, x_i^+) ;\leftarrow; \text{同一参考基因组上两条 10,000 bp 非重叠窗口}
$$
数据来自 GenBank:病毒、真菌、细菌共约 204.8 万对,其中 200 万对 用于训练。这种正样本定义与物种标签 弱监督一致,比随机突变或互补链配对更贴近「物种感知」目标(论文 ablation 中 same_species 策略最优)。
3. Phase I:Weighted SimCLR
3.1 动机
标准 SimCLR 对所有负样本 等权重。但嵌入空间中 靠近锚点的负样本(hard negatives)更能刻画决策边界,应获得更大梯度权重。
3.2 加权损失
对 batch ${(x_i, x_i^+)}{i=1}^B$,定义虚拟标签向量 $v_i \in {0,1}^B$,其中 $v{i,i}=1$ 表示 $x_i^+$ 为正,其余为负。对锚点 $x_i$:
$$
\ell(f(x_i), v_i) = -\sum_{n=1}^{B} v_{i,n} \log \frac{\exp(s(f(x_i), f(x_n^+))/\tau)}{\sum_{j \neq i} \alpha_{ij} \exp(s(f(x_i), f(x_j))/\tau)}
$$
权重 $\alpha_{ij}$ 随与锚点的相似度 增大 而增大(hard negative 加权):
$$
\alpha_{ij} = \frac{\exp(s(f(x_i), f(x_j))/\tau)}{\frac{1}{2B-2}\sum_{k \neq i,i^+} \exp(s(f(x_i), f(x_k))/\tau)}, \quad \alpha_{ii^+}=1
$$
对 $x_i^+$ 同样作为锚点计算 $\ell(f(x_i^+), v_i)$(交换 $x$ 与 $x^+$ 角色)。Phase I 总损失:
$$
\mathcal{L}{\mathrm{I}} = \frac{1}{2B}\sum{i=1}^{B}\Big(\ell(f(x_i), v_i) + \ell(f(x_i^+), v_i)\Big) \tag{2}
$$
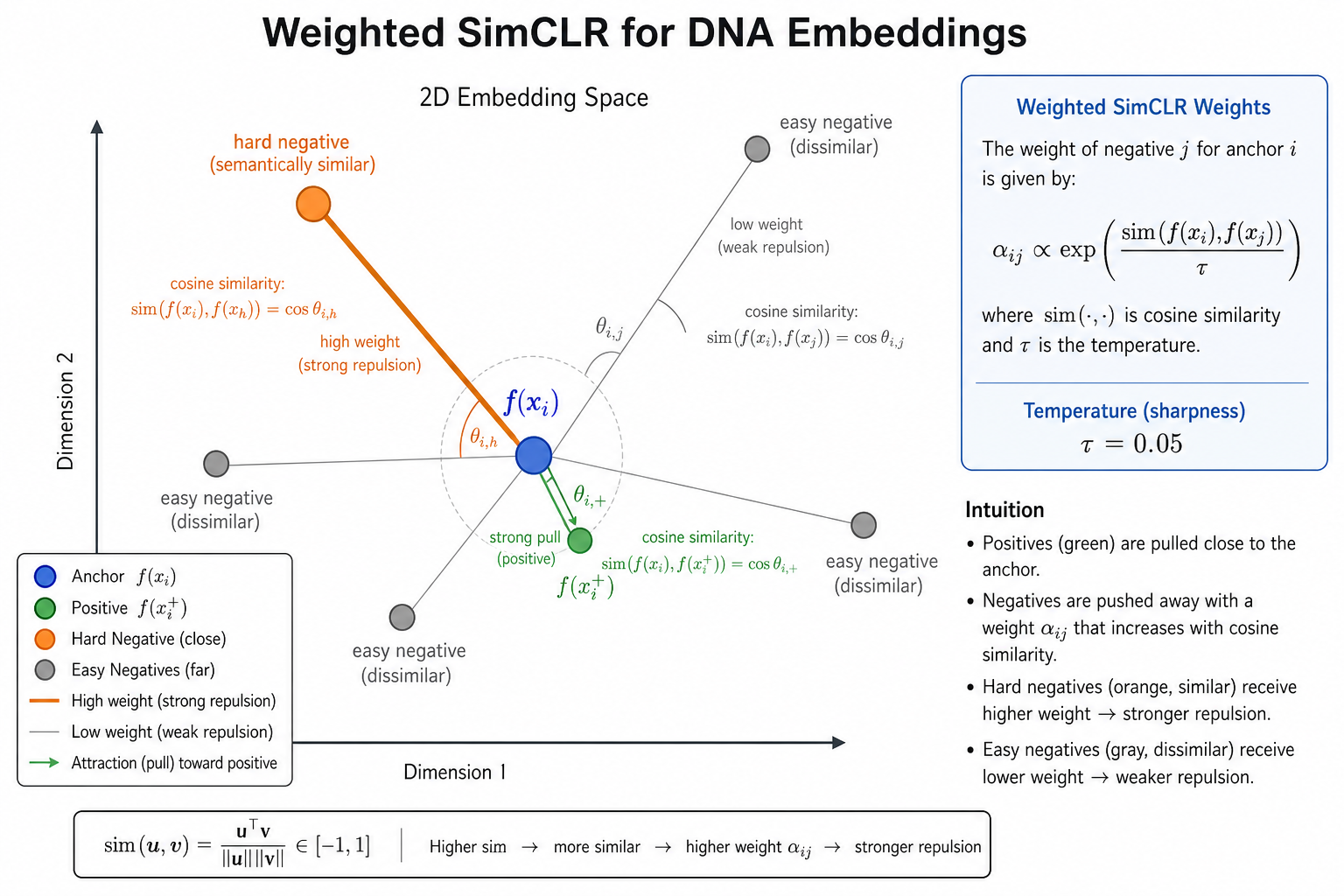
3.3 直观理解
| 元素 | 作用 |
|---|---|
| 双锚点 $(x_i, x_i^+)$ | 每个正样本对贡献两次损失,对称优化 |
| $\alpha_{ij}$ | 相似负样本 → 更大惩罚,边界更清晰 |
| 小 $\tau=0.05$ | 强化细微相似度差异,适合高维嵌入 |
4. Phase II:Manifold Instance Mixup(MI-Mix)
4.1 为何不用输入层 mixup?
Instance Mixup(i-Mix)(Lee et al., 2020)在 输入层 混合:
$$
\tilde{x}_i = \lambda_i x_i + (1-\lambda_i)\hat{x}_i, \quad \lambda_i \sim \mathrm{Beta}(\alpha,\alpha)
$$
对 图像、语音 等连续数据有效,但 DNA 是 离散碱基;直接线性混合 $A/T/C/G$ 会产生非生物学序列。若在 anchor 空间仅 mix $x_i$ 而对比 $x_i^+$,还会 近似翻倍 显存或训练时间(DNABERT-S 附录 A.10)。
4.2 MI-Mix:在隐层流形上混合
将编码器分解为 $f(x) = f_m(g_m(x))$:
- $g_m(\cdot)$:第 $1\ldots m$ 层,输出 第 $m$ 层隐状态;
- $f_m(\cdot)$:第 $m+1\ldots L$ 层 + 投影头,输出最终嵌入。
四步流程:
1 | flowchart TB |
数学形式:
$$
h_i^m = \lambda_i g_m(x_i) + (1-\lambda_i) g_m(\hat{x}_i)
$$
$$
v_i^{\mathrm{mix}} = \lambda_i v_i + (1-\lambda_i) \hat{v}_i
$$
对混合锚点的损失(与 Phase I 结构类似,锚点换为 $f_m(h_i^m)$,标签换为 $v_i^{\mathrm{mix}}$):
$$
\hat{\ell}(f_m(h_i^m), v_i^{\mathrm{mix}}) = -\sum_{n=1}^{B} v_{i,n}^{\mathrm{mix}} \log \frac{\exp(s(f_m(h_i^m), f(x_n^+))/\tau)}{\sum_{j=1}^{B} \alpha_{ij^+} \exp(s(f_m(h_i^m), f(x_j^+))/\tau)} \tag{3}
$$
Phase II 总损失 $\mathcal{L}_{\mathrm{II}} = \frac{1}{B}\sum_i \hat{\ell}(\cdot)$。
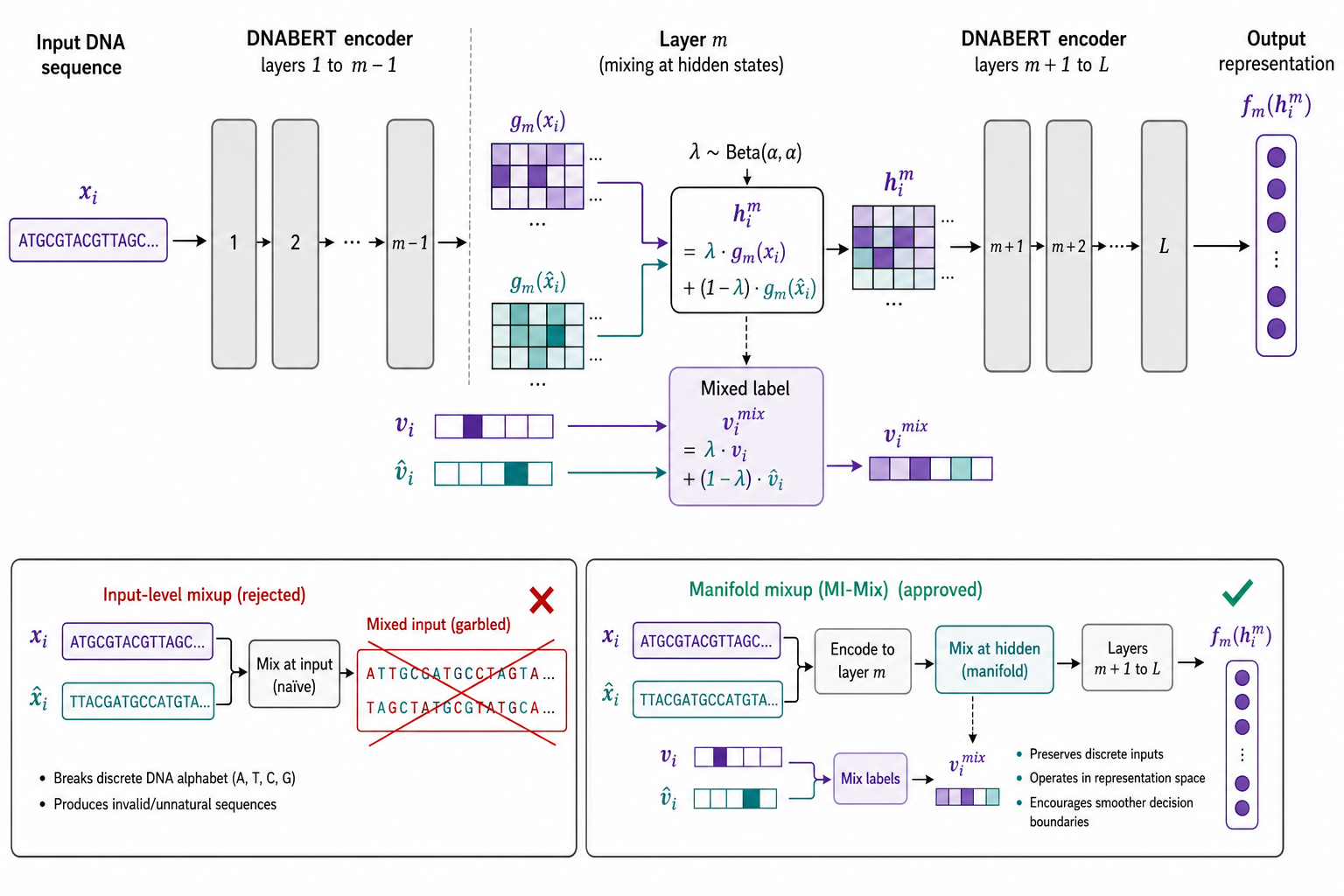
4.3 MI-Mix 与 i-Mix、Manifold Mixup 的关系
| 方法 | 混合位置 | 适用模态 | DNABERT-S 选用 |
|---|---|---|---|
| i-Mix | 输入层 | 连续信号 | 否(DNA 离散 + 算力) |
| Manifold Mixup(Verma et al.) | 指定隐层 | 图像等 | 思想来源 |
| MI-Mix | 随机隐层 $m$ + 仅 mix anchor | DNA 序列 | 是 |
随机选 $m$ 相当于对 不同抽象层级 的特征做增强,迫使模型在 流形(manifold) 上识别「混合比例」对应的软标签 $v_i^{\mathrm{mix}}$,对 长读长、含测序错误 的序列更鲁棒。
5. C²LR 完整训练日程(DNABERT-S)
5.1 两阶段课程
| 阶段 | 损失 | Epoch | 锚点特点 |
|---|---|---|---|
| Phase I | Eq. (2) Weighted SimCLR | 1 | 真实 $f(x_i)$、$f(x_i^+)$ |
| Phase II | Eq. (3) MI-Mix | 2 | 混合 $f_m(h_i^m)$,难度更高 |
总训练 3 epoch;$\tau=0.05$,$\alpha=1.0$(Beta 分布参数);嵌入为 最后一层隐状态 mean pooling → 128 维(再经投影头)。
5.2 实现要点
| 项 | 典型设置 |
|---|---|
| 初始化 | DNABERT-2-117M 权重 |
| 优化器 | Adam,lr $3\times 10^{-6}$ |
| Batch | 48(8×A100-80GB) |
max_length |
2000 token(对应 10 kb DNA 的 0.2× 长度设置) |
| 对比方法 | same_species 正样本对 |
| 开关 | --curriculum + --mix --mix_layer_num -1(-1 表示 manifold / 随机层 MI-Mix) |
5.3 消融结论(论文 Table 2)
| 变体 | 说明 |
|---|---|
| 仅 Weighted SimCLR | 缺 Phase II,边界较弱 |
| 仅 MI-Mix | 缺 Phase I 基础,不稳定 |
| Phase II 换 i-Mix | 弱于 MI-Mix |
| C²LR(I + II) | ARI / 分箱 / few-shot 综合最优 |
课程顺序不可颠倒:先 SimCLR 建立物种簇,再 MI-Mix 细化边界。
6. 嵌入空间几何:训练前后对比
1 | flowchart LR |
训练目标可概括为:
$$
\min_f ; \mathbb{E}{(x,x^+)\sim \mathcal{D}^+}\Big[\underbrace{-s(f(x),f(x^+))}{\text{Phase I/II 共同:拉近同物种}} + \underbrace{\sum_{x^-} \alpha(x,x^-), s(f(x),f(x^-))}_{\text{Weighted:推远 hard 负样本}}\Big]
$$
Phase II 额外在 $h^m$ 上构造 软标签 $v^{\mathrm{mix}}$,相当于对决策边界做 数据依赖的正则化。
7. 广义 C²LR 与相关文献
C²LR 并非 DNA 独有;同一思想可迁移到其他 需要几何嵌入 的场景:
| 工作 | 课程对象 | 场景 |
|---|---|---|
| COCO(Chu et al.) | 负样本难度 | 图对比学习 |
| Temporal CL + Curriculum(Roy & Etemad) | 时间正样本对 | 语音/时序 |
| Efficient CL + Curriculum(Ye et al.) | 数据增强强度 | 句子嵌入 |
| DNABERT-S C²LR | 对比锚点(真实 → 隐层混合) | 基因组物种嵌入 |
设计自己的 C²LR 时可问三个问题:
- 什么是「简单锚点」?(真实样本、弱增强、短序列)
- 什么是「困难锚点」?(混合表示、强增强、跨域样本)
- 困难锚点应在哪一层构造?(输入 vs 隐层 vs 输出)
对 离散序列(DNA、密码子、SMILES),优先 隐层 mixup 而非 token 级插值。
8. 实践建议与常见坑
8.1 何时考虑 C²LR
- 已有强 MLM/自回归 预训练模型,但下游需要 聚类、检索、分箱 等几何任务;
- 有 弱标签结构(如同物种配对、同病人配对、同文档段落);
- 数据含 噪声或长读长错误,需要 Phase II 式鲁棒边界。
8.2 常见坑
| 问题 | 建议 |
|---|---|
| 跳过 Phase I 直接 MI-Mix | 保持两阶段;论文 ablation 证明课程必要 |
| 正样本定义不当 | 物种任务用 同基因组非重叠片段,慎用纯 dropout 视图 |
| $\tau$ 过大 | 嵌入区分度不足;DNA 场景可试 $0.05$–$0.1$ |
| batch 过小 | 负样本数 $2B-2$ 不足,对比信号弱;适当增大 batch 或 memory bank |
| 与 MLM 混训同一阶段 | DNABERT-S 是 第二阶段 对比微调,而非替换 MLM |
8.3 与 DNABERT-2 选型文档的衔接
| 任务 | 推荐模型 |
|---|---|
| 启动子/增强子 MLM 微调 | DNABERT-2 |
| 物种聚类 / 宏基因组分箱 | DNABERT-S(C²LR 嵌入) |
| 需自定义物种边界 | 可在 DNABERT-2 上 复现 C²LR 流程 |
9. 小结
| 概念 | 一句话 |
|---|---|
| C²LR | 对比学习 + 课程学习;锚点难度 分两阶段递增 |
| Phase I | Weighted SimCLR:hard negative 加权 + 同物种正样本对 |
| Phase II | MI-Mix:在随机 Transformer 层混合隐状态,软标签对比 |
| DNABERT-S | DNABERT-2 + C²LR → 物种感知 128 维 DNA 嵌入 |
C²LR 的价值在于:它把「先易后难」从样本排序推广到 对比锚点的构造方式,并在 DNA 场景用 流形 mixup 避开离散碱基混合的陷阱。理解 Phase I/II 的分工,是在项目中 复用、改造或替换 该策略的基础。
参考文献
- Zhou Z. et al. DNABERT-S: Learning Species-Aware DNA Embedding with Genome Foundation Models. ICLR 2024. arXiv:2402.08777
- Chen T. et al. A Simple Framework for Contrastive Learning of Visual Representations (SimCLR). ICML 2020.
- Zhang Y. et al. Weighted SimCLR. 2021.
- Lee H. et al. i-Mix: A Strategy for Regularizing Contrastive Representation Learning. ICLR 2021.
- Verma V. et al. Manifold Mixup. ICML 2019.
- Bengio Y. et al. Curriculum Learning. ICML 2009.
- Chu G. et al. COCO: Graph Representation with Curriculum Contrastive Learning. 2021.
- 代码:MAGICS-LAB/DNABERT_S