DeepSeek(深度求索)是近年来开源大语言模型(Large Language Model,LLM)领域最具代表性的 混合专家(Mixture of Experts,MoE)+ 解码器 Transformer 路线实践者:在 671B 级总参数量下仅激活约 37B 参数/token,通过 多头潜注意力(Multi-Head Latent Attention,MLA) 压缩 KV Cache、DeepSeekMoE 稀疏路由与 FP8 训练工程,把预训练成本压到同类稠密模型的数量级分之一;DeepSeek-R1 则在同一骨干上用大规模强化学习(Reinforcement Learning,RL) 激发链式推理。2026 年 DeepSeek-V4 进一步以 压缩稀疏注意力(Compressed Sparse Attention,CSA)、重度压缩注意力(Heavily Compressed Attention,HCA) 与 流形约束超连接(Manifold-Constrained Hyper-Connections,mHC) 将原生上下文推至 1M token。
段末注释:MoE 指每 token 仅激活部分专家子网络;MLA 用低秩潜向量压缩 Key/Value 缓存;KV Cache 为自回归推理时缓存的历史 Key/Value 向量。
前置阅读:5003.大模型-架构-0.大模型架构范式综述(MoE 范式定位)
插图约定:配图为科普动漫风学术示意(非官方原图),位于 5003.大模型-架构-DeepSeek-0.概述/。
1. 在架构范式中的位置
DeepSeek 主线属于 Decoder-only 自回归 Transformer,在「规模与路由」维度走 MoE 而非纯稠密堆叠;在「序列混合」维度,V2–V3.2 以 MLA(可视为带 KV 压缩的注意力变体)为主,V3.2 叠加 DeepSeek Sparse Attention(DSA),V4 改为 CSA/HCA 混合注意力栈。
| 维度 | DeepSeek 选择 | 对照 |
|---|---|---|
| 训练目标 | 下一 token 交叉熵(+ V3 多 token 预测辅助目标) | 与 GPT/LLaMA 相同 |
| 混合机制 | MLA → DSA → V4 CSA/HCA | LLaMA 用 GQA;Mamba 用 SSM |
| 规模路由 | 256 路由专家 + 1 共享专家 / 层 | Mixtral 8×7B 为较小 MoE |
| 后训练 | SFT + RLHF(V3 Chat);纯/少 SFT + 大规模 RL(R1) | R1 代表「推理能力来自 RL」 |
对生物信息学读者:DeepSeek 通常作为 Agent 编排、文献/协议问答、代码与 pipeline 生成的通用推理后端,而非像 ESM / DNABERT 那样在领域序列上预训练——选型时需区分「通用 LLM API」与「领域基础模型」。
2. 核心架构:以 DeepSeek-V3 为基准
DeepSeek-V3(2024-12,arXiv:2412.19437)是当前理解整个系列的架构锚点:671B 总参数,每 token 激活约 37B;128K 上下文;在 14.8T token 上预训练,官方称约 2.788M H800 GPU·小时(业界常引用 ~550 万美元量级,随集群与电价浮动)。
整体仍为 Pre-Norm Transformer 解码器栈(RMSNorm、SwiGLU FFN 被 MoE 替换、RoPE 位置编码),单层逻辑如图 1。
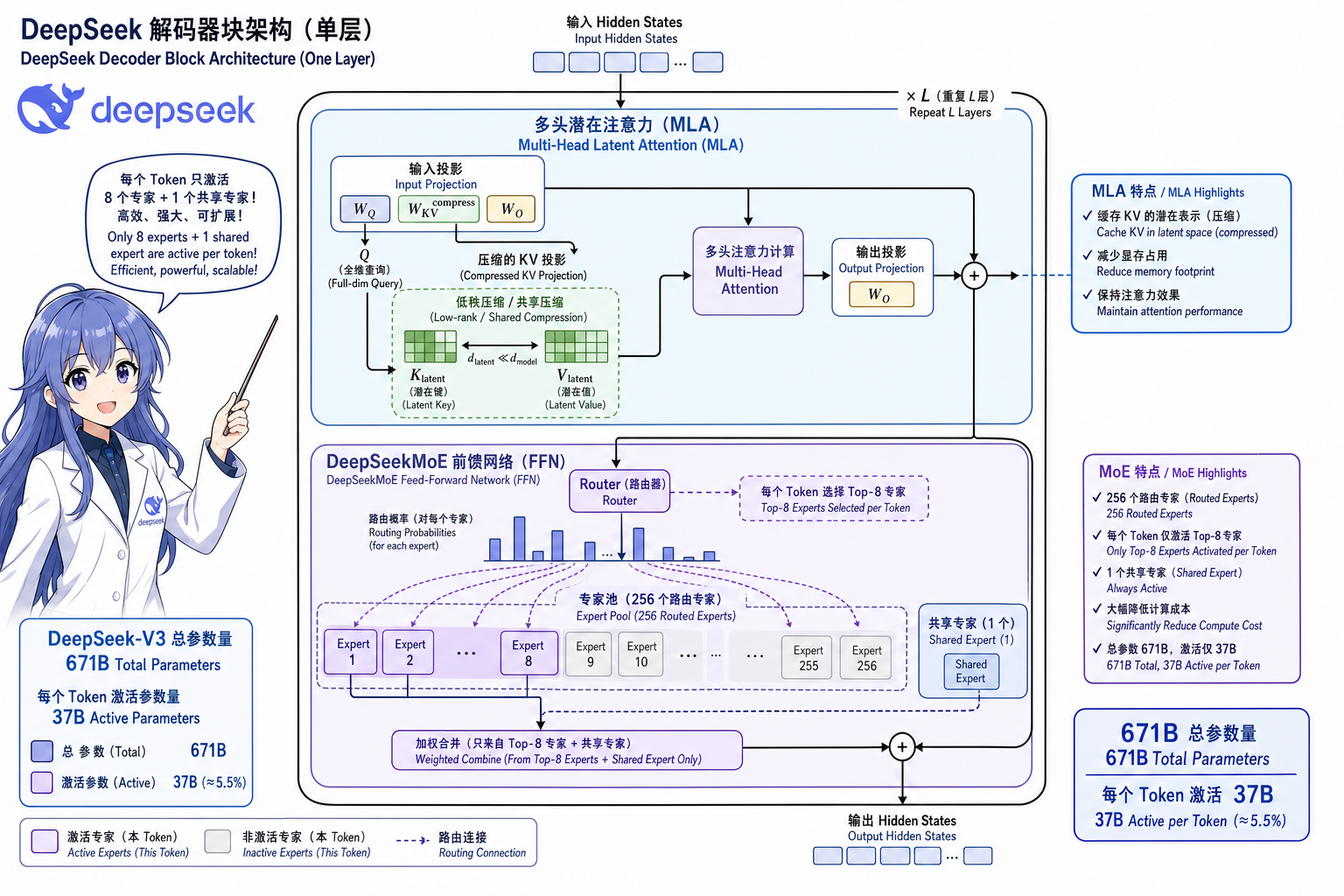
2.1 Multi-Head Latent Attention(MLA)
问题:标准多头注意力(Multi-Head Attention,MHA)推理时需缓存完整 K/V,长上下文下 KV Cache 显存占主导。
做法(DeepSeek-V2 提出,V3 延续并细化):将 K/V 投影到低秩潜空间 (c_t^{KV}),推理时只缓存潜向量,需要时再上投影还原各头 K/V:
[
c_t^{KV} = W^{DKV} h_t, \quad k_t = W^{UK} c_t^{KV}, \quad v_t = W^{UV} c_t^{KV}.
]
Q 侧也可做类似低秩分解(MQA 模式)。效果:在可比质量下 KV 缓存显著减小(社区实测常引 ~90%+ 量级,依实现与头数而异),长上下文推理更可行。
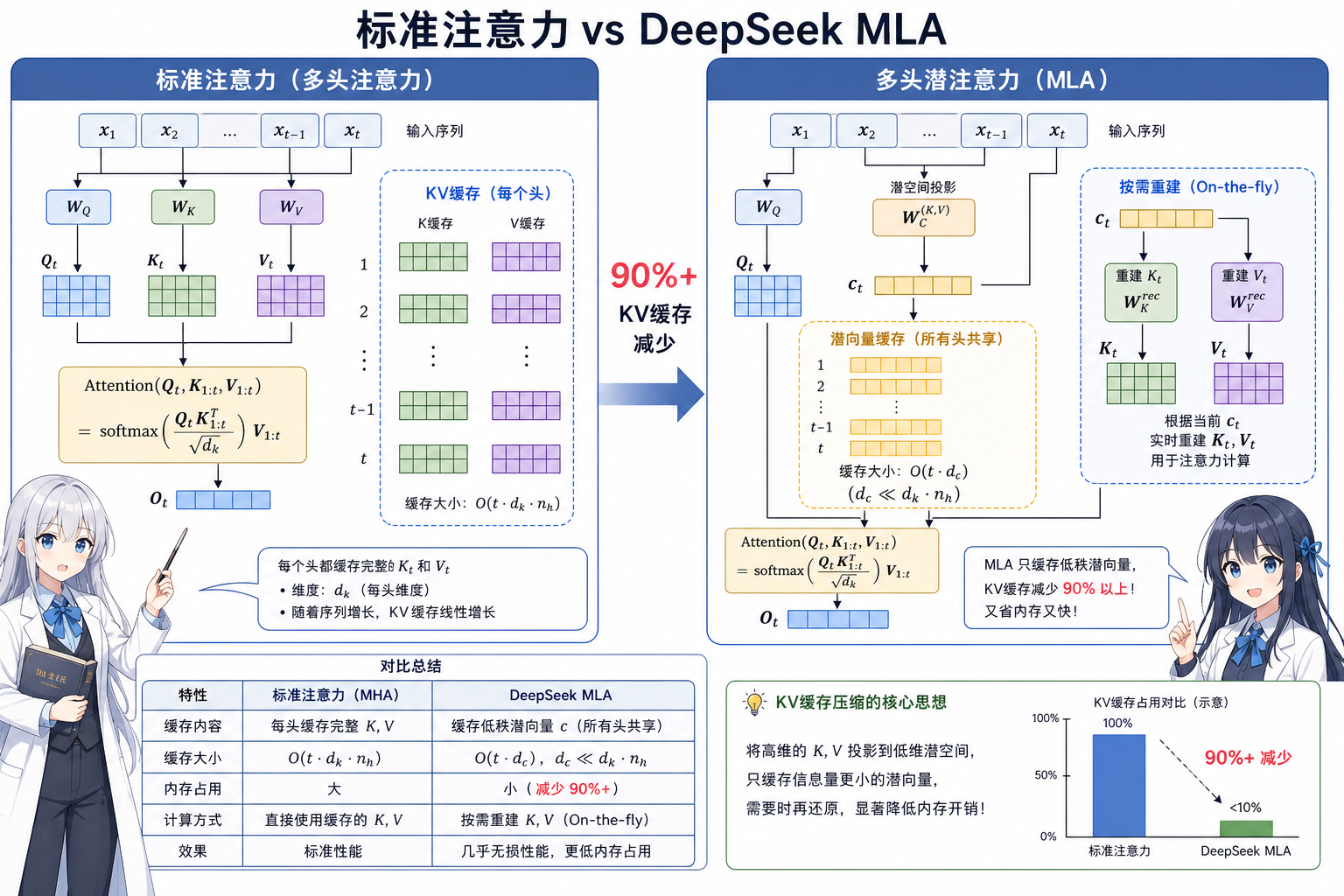
段末注释:MHA 为每头独立 Q/K/V;MQA(Multi-Query Attention)为多 Q 头共享一组 K/V;MLA 在潜空间统一压缩后再按头上投影。
2.2 DeepSeekMoE 前馈层
FFN 层替换为 DeepSeekMoE(DeepSeek-V2/V3 技术报告):
| 组件 | V3 典型配置 | 作用 |
|---|---|---|
| 路由专家(Routed Experts) | 256 个 / 层 | 门控网络按 token 选 Top-(k)(常 8) |
| 共享专家(Shared Expert) | 1 个 / 层 | 始终激活,捕获通用模式 |
| 细粒度专家 | 较 Switch Transformer 更细分 | 知识分解更均匀,单专家更窄 |
相对 DeepSeek-V2,V3 路由专家数 160→256,FFN 容量显著增大而每 token 激活 FLOPs 可控。
设备受限路由(Device-Limited Routing):先在 (M) 个设备(GPU)内选专家,限制跨机通信——与 HPC 协同设计绑定。
2.3 无辅助损失的负载均衡(Auxiliary-Loss-Free Balancing)
MoE 常见问题是专家负载倾斜(routing collapse / 专家坍缩)。传统做法加 auxiliary load balancing loss,但会损害下游质量。概念详解见 LLM概念解析-01.专家坍缩。
DeepSeek-V3 采用 bias-only 动态路由:给门控分数加可学习偏置 (b_i),训练时若专家 (i) 过载/欠载则按步更新 (b_i)(不进入总 loss),使 token 分布更均匀。这是 V3 相对 V2 的关键架构/训练策略增量之一。
2.4 多 Token 预测(Multi-Token Prediction,MTP)
V3 训练引入 MTP 辅助头:除下一 token 外,同时预测后续多个 token,作为额外监督。论文报告有助于提升整体 benchmark,并带来 15–20% 量级训练收敛加速(依实现而定)。
2.5 FP8 混合精度预训练
DeepSeek-V3 是首批大规模 FP8 预训练开源 LLM 之一:
- 权重/激活采用 E4M3 等 FP8 格式(细粒度 tile 量化,非整行粗量化);
- 配合 DualPipe 等流水线并行与 PTX 级内核优化;
- 目标:在 H800 集群上完成 671B MoE 训练而不超预算。
这使「稀疏大模型 + 低精度 HPC」成为可复现工程路径,而非仅算法论文。
3. DeepSeek-V3.2:DeepSeek Sparse Attention(DSA)
DeepSeek-V3.2(2025-12,arXiv:2512.02556)在 V3.1-Terminus 上继续训练引入 DSA,架构与 V3.2-Exp(2025-09 实验版)一致:
- Lightning Indexer:轻量索引头,用 MLA 潜表示对历史 token 打相关性分数(ReLU + 加权和);
- Top-(k) Token 选择:仅对得分最高的 (k) 个 token 做完整 MLA 注意力;
- 复杂度由 (O(L^2)) 降为约 (O(Lk))((k \ll L)),长上下文 decode/prefill 成本近常数化趋势。
V3.2 同时放大后训练 RL 算力(官方称超过预训练算力的 10%)与 Agent 任务生态(1800+ 环境、85000+ 任务),使开源模型在推理、工具调用上与闭源旗舰缩小差距。DeepSeek-V3.2-Speciale 为高算力长思考变体,偏研究/竞赛(IMO、IOI 等),日常 chat 非首选。
4. DeepSeek-V4:2026 架构跃迁
DeepSeek-V4(2026-04)在注意力与连接方式上不再沿用纯 MLA,转向混合长上下文栈(见图 4):
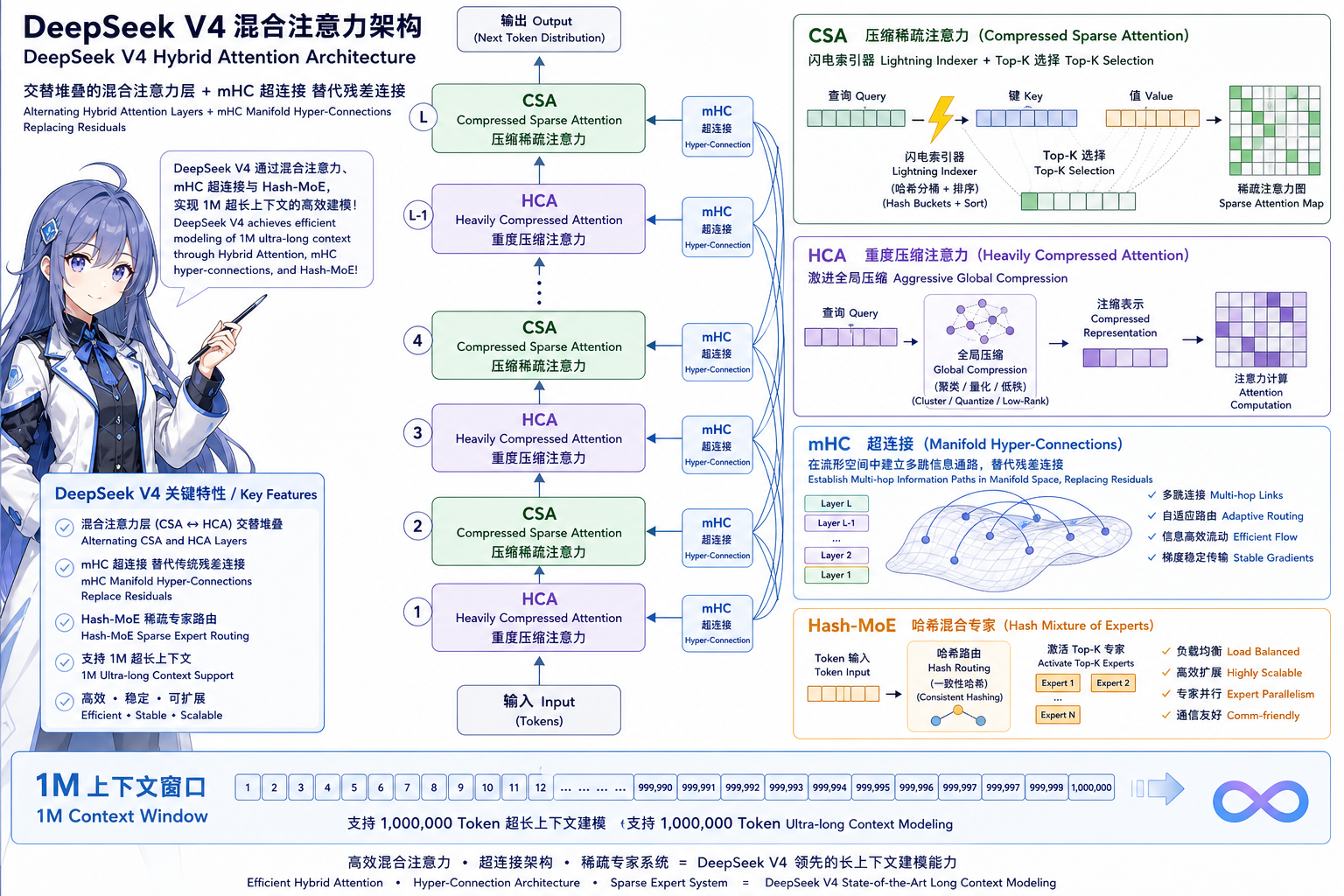
| 模块 | 含义 | 作用 |
|---|---|---|
| CSA | 低压缩率块 + Lightning Indexer Top-(k) | 细粒度局部关联 |
| HCA | 高压缩率(如 (m’=128))块级聚合 | 廉价全局视野 |
| mHC | 多流形约束超连接,替代标准残差 | 稳定超深/超长训练 |
| Hash-MoE | 前几层用 token-id→expert 静态哈希路由 | 引导 MoE 冷启动 |
规格(公开资料):
| 型号 | 总参数 | 每 token 激活 | 上下文 | 预训练 token |
|---|---|---|---|---|
| V4-Pro | ~1.6T | ~49B | 1M | 32T+ |
| V4-Flash | ~284B | ~13B | 1M | 32T+ |
相对 V3.2,在 1M token 场景下,V4-Pro 推理 FLOPs ~27%、KV Cache ~10%(Flash 更低)——长代码库、多文档 Agent、跨会话记忆成为一等公民。
三种推理模式:Non-think(快答)、Think High(链式推理)、Think Max(极限推理预算;需特定 system prompt 前缀)。
5. DeepSeek-R1:同架构、不同训练范式
DeepSeek-R1(2025-01,arXiv:2501.12948)与 V3 共享 MoE 骨干,差异几乎全在后训练:
1 | flowchart LR |
| 模型 | 后训练 | 输出风格 | 典型场景 |
|---|---|---|---|
| V3 / V3-0324 / V3.1 | SFT + RLHF;V3.1 支持 思考/非思考 双模式 | 直接回答或可控 CoT | 通用对话、代码、Agent |
| R1-Zero | 无 SFT,纯 RL | 强推理但可读性差、易混语言 | 研究 ablation |
| R1 / R1-0528 | 少量冷启动 SFT + 大规模 RL | 输出含 think 推理块 + 最终答案 |
数学、竞赛编程、多步规划 |
| R1-Distill | 小模型 + R1 合成数据 SFT | 小参数上的推理能力 | 本地 7B–70B 部署 |
R1-0528(2025-05):推理 token 预算显著增加(如 AIME 上均值 12K→23K),幻觉率下降,支持 system prompt;工具调用在 thinking 模式下仍有限制。
生物信息学提示:用 R1 做 实验设计推演、统计检验选择、生信脚本 debug 时,宜在 prompt 中要求分步推理;部署成本远高于 V3-Flash 类模型,需按任务选 V3.1 混合模式 或 蒸馏 R1。
6. 生物信息学与开源部署要点
| 场景 | 推荐型号 | 备注 |
|---|---|---|
| 文献综述、邮件、报告起草 | V3 / V3.1 非思考模式 | 延迟低 |
| 复杂 pipeline、Snakemake/WDL 生成 | V3.1 思考模式 或 R1-0528 | 需验证语法 |
| 长 PDF / 多组学文档问答 | V3.2+(DSA)或 V4(1M ctx) | 注意隐私与合规 |
| 本地私有化(有限 GPU) | R1-Distill-Qwen/Llama 7B–32B | 非领域 FM |
| 领域序列/embeddings | ESM / DNABERT / NT 等 | 非 DeepSeek 替代 |
硬件粗算:完整 671B MoE 推理通常需 多卡 H200/H800 级;生产常见 vLLM / SGLang + FP8/INT4 量化 + 专家并行。切勿用通用 LLM 替代在基因组上预训练的 GFM 做 variant effect 等任务。
7. 版本迭代史:从 DeepSeek-LLM 到 V4
下图概括主线里程碑;下文按时间展开架构与能力增量。

7.1 2024:奠基与效率架构
| 时间 | 版本 | 架构/训练要点 | 意义 |
|---|---|---|---|
| 2024-01 | DeepSeek-LLM | 7B/67B 稠密;双语 2T token;非 embedding FLOPs/token 缩放律 | 确立数据-算力-模型规模配比方法论 |
| 2024-02 | DeepSeek-Math | 数学语料继续预训练 | 为后续 R1 推理与 V3.2-Speciale 打基础 |
| 2024-05 | DeepSeek-V2 | MLA + DeepSeekMoE 首次系统亮相;236B 总 / 21B 激活 | KV 与 FFN 双路径降本 |
| 2024-11 | DeepSeek-V2.5 | V2 + Coder 能力合并 | 代码能力并入主线 |
| 2024-12 | DeepSeek-V3 | 671B / 37B 激活;256 专家;无 aux-loss 均衡;MTP;FP8 全链路预训练 | 开源 MoE 旗舰;训练成本震惊业界 |
并行产品线:DeepSeek-Coder(代码)、DeepSeek-VL(视觉语言)等,共享部分训练基建但架构各异。
7.2 2025 上:推理模型与混合模式
| 时间 | 版本 | 相对前代升级 | 关键点 |
|---|---|---|---|
| 2025-01 | DeepSeek-R1-Zero | V3-Base + 纯 RL | 证明无 SFT 亦可涌现 CoT;可读性不足 |
| 2025-01 | DeepSeek-R1 | 冷启动 SFT + RL;R1-Distill 系列 | 开源推理标杆;6 个蒸馏小模型 |
| 2025-03 | DeepSeek-V3-0324 | V3-Base + 改进后训练(借鉴 R1 RL 技巧) | 通用能力 + 推理/代码跳升 |
| 2025-05 | DeepSeek-R1-0528 | 更多 RL 算力;推理链更长;幻觉↓ | 支持 system prompt;接近 o3 级数学编程 |
| 2025-08 | DeepSeek-V3.1 | 思考/非思考同一权重双模板;128K 续训;Agent/tool 强化 | 「一个模型两种人格」 |
| 2025-09 | DeepSeek-V3.1-Terminus | 语言一致性、Agent 稳定性修补 | V3.1 小步稳定版 |
| 2025-09 | DeepSeek-V3.2-Exp | 引入 DSA 实验架构 | 长上下文效率验证 |
| 2025-12 | DeepSeek-V3.2 | DSA 定型 + 大规模 RL + Agent 生态 | 对标 GPT-5-High 级开源综合 |
| 2025-12 | DeepSeek-V3.2-Speciale | 高算力长思考 + DeepSeek-Math-V2 定理能力 | IMO/IOI 金牌级;偏研究 |
7.3 2025 下–2026:长上下文原生架构
| 时间 | 版本 | 架构变化 | 能力定位 |
|---|---|---|---|
| 2026-04 | DeepSeek-V4-Flash | CSA/HCA 混合注意力;mHC;Hash-MoE;1M ctx | 高性价比超长上下文 |
| 2026-04 | DeepSeek-V4-Pro | 同上,规模更大(~1.6T / 49B active) | 开源最强综合 + 世界知识跃升 |
7.4 迭代逻辑总结(三代架构思想)
| 代际 | 代表 | 核心问题 | 解法 |
|---|---|---|---|
| 第一代 | V2 | KV 与 FFN 太贵 | MLA + DeepSeekMoE |
| 第二代 | V3 | 671B 如何训得起、推得动 | FP8 + DualPipe + 无 aux MoE 均衡 + MTP |
| 第三代 | V3.2 | 长上下文仍贵 | DSA 稀疏注意力 + 大 RL |
| 第四代 | V4 | 1M ctx 必须「原生」而非硬撑 | CSA/HCA 层间交替 + mHC + 更大 MoE |
后训练路线亦在分化:V3 线 = SFT/RLHF 对齐通用助手;R1 线 = RL 激发推理;V3.1+ = 合并为可切换思考模式;V4 = 内置 Non-think / Think High / Think Max 三档。
8. 与其它 MoE 开源模型对照
| 模型 | 总参 / 激活 | 注意力 | 长上下文 | 开源许可 |
|---|---|---|---|---|
| DeepSeek-V3 | 671B / 37B | MLA | 128K | MIT |
| Mixtral 8×22B | ~176B / ~39B | GQA | 64K | Apache 2.0 |
| Qwen3-MoE | 随版本 | GQA/MLA 类 | 128K+ | 各版本不同 |
| DeepSeek-V4-Pro | ~1.6T / 49B | CSA+HCA | 1M | MIT |
DeepSeek 的差异化在于 MLA→DSA→CSA/HCA 连续演进与 RL 推理线深度耦合,而非单点堆参数量。
9. 小结
- 架构主线:Decoder-only MoE + KV 高效注意力(MLA → DSA → V4 混合压缩注意力)+ HPC 协同(FP8、专家并行、无 aux 负载均衡)。
- V3/R1 关系:同一 V3-Base 骨干;Chat vs R1 是后训练配方之分,不是两套 Transformer。
- 最新 V4:面向 1M token 与 Agent/代码库 重新设计注意力与连接,Pro/Flash 分级覆盖旗舰与性价比。
- 版本史:2024 解决「能训、能推」→ 2025 解决「会推理、会调工具」→ 2026 解决「超长上下文原生可用」。
段末注释:CoT(Chain-of-Thought)指模型生成中间推理步骤再给出答案;SFT 为监督微调(Supervised Fine-Tuning)。
参考与延伸阅读
- DeepSeek-AI, DeepSeek-V3 Technical Report(arXiv:2412.19437).
- DeepSeek-AI, DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning(arXiv:2501.12948).
- DeepSeek-AI, DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model(arXiv:2405.04434).
- DeepSeek-AI, DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models(arXiv:2512.02556).
- Dai et al., DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models(arXiv:2401.06066).
- Hugging Face Transformers — DeepSeek-V4 模型文档.
- 本目录:范式综述、Transformer 概述.