LangGraph 是 LangChain(LangChain 生态)之上的有向状态图编排库:把 大语言模型(large language model,LLM)应用建模为节点(node)、边(edge)与共享状态(state)的图,支持环(循环)、条件分支、人在回路(human-in-the-loop,HITL)与检查点(checkpoint)持久化。它解决的是「仅靠线性 Chain 难以表达多步推理、工具重试、审批与恢复」的工程问题。
段末注释:LangGraph 与「画一张 DAG 跑批」不同,它显式允许回边,天然适合 ReAct(reason + act)类 Agent。
下文配图均为科普动漫风架构示意,便于与正文术语对齐,非 LangChain 官方发布图。
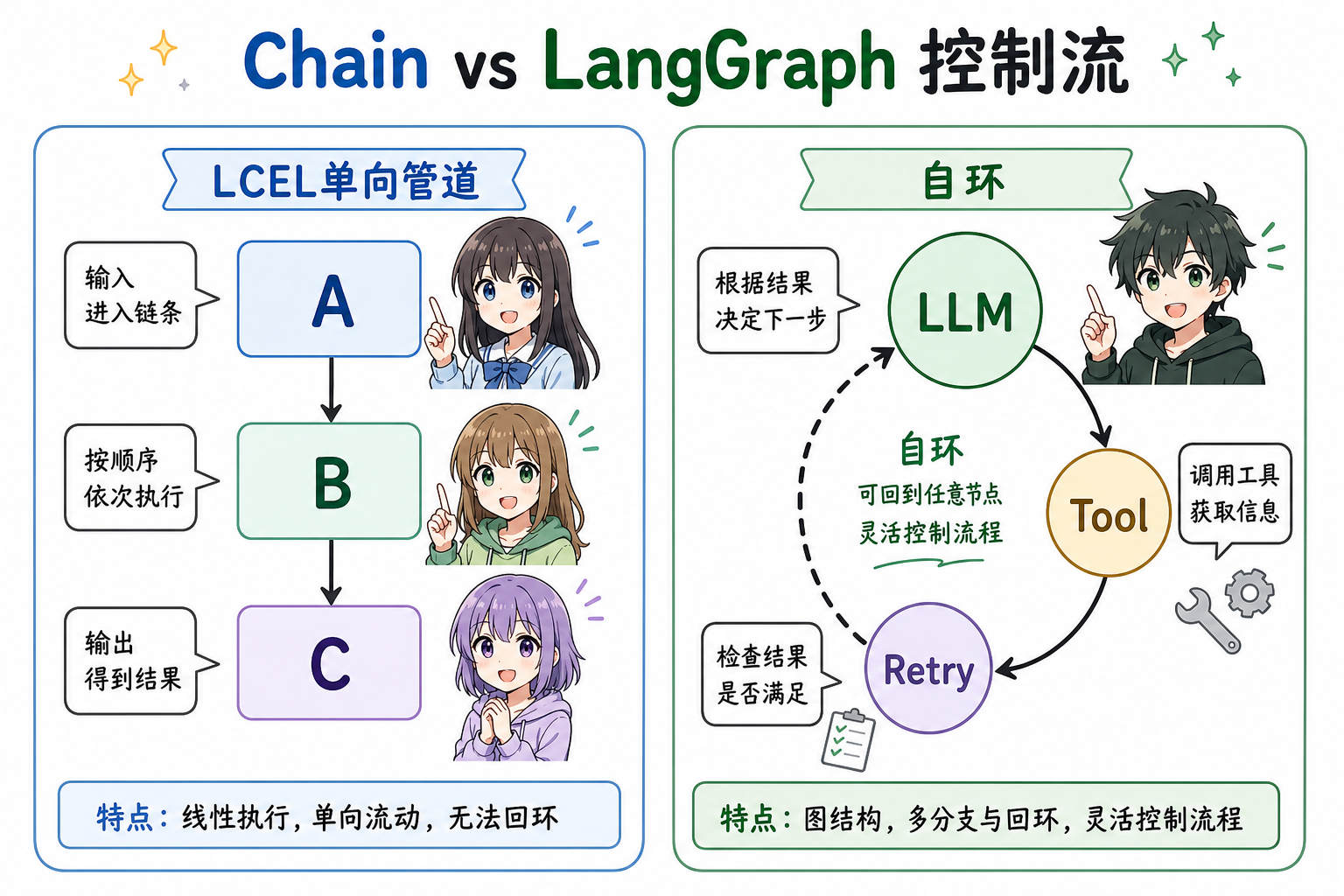
1. 方法定位:与 Chain、纯 Agent 框架的差异
| 维度 | 线性 Chain / LCEL | LangGraph |
|---|---|---|
| 控制流 | 多为单向管道 | 任意图:分支、合并、自环 |
| 状态 | 常隐式在上下文对象里 | 显式 State,节点读写契约清晰 |
| 持久化 | 需自行拼 | 一等 checkpointer + thread_id |
| 人在回路 | 要自己阻塞与恢复 | interrupt、从检查点 resume 等模式 |
若业务只是「一次 RAG(retrieval-augmented generation)问答」,用轻量 Chain 即可;若需要「多轮工具 + 失败重试 + 人工审批某一步」,LangGraph 更贴切。
2. 实现原理(心智模型)
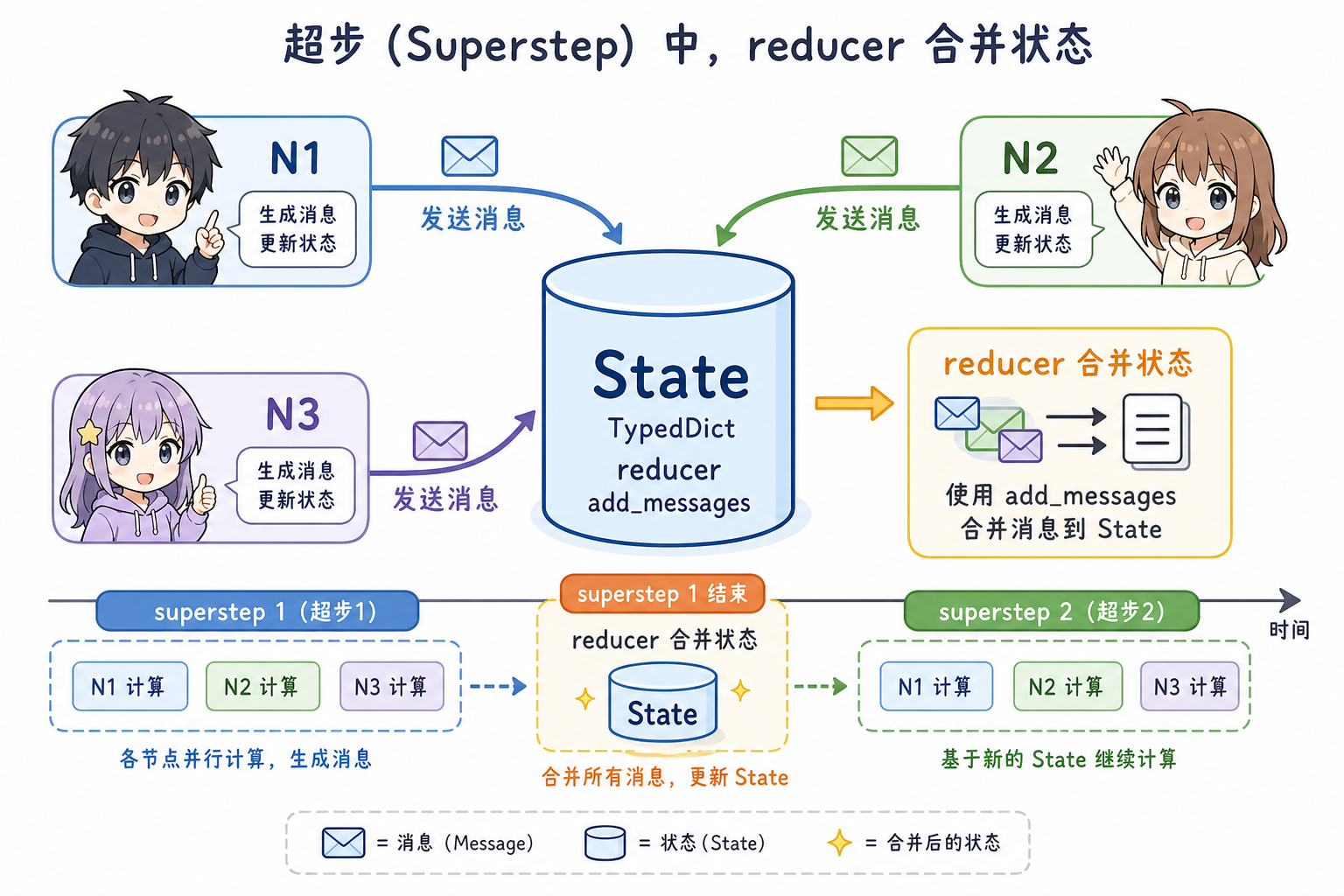
2.1 状态图(StateGraph)与超步(superstep)
- 图:
StateGraph(StateSchema)注册若干节点函数;每条边表示「上一节点结束后,下一节点谁可运行」。 - 状态
State:一般用TypedDict(或 Pydantic)描述;列表型字段常用Annotated[..., reducer](如add_messages)定义「多节点写入时如何合并」,避免互相覆盖。 - 执行:一次 invoke/stream 可理解为多轮 superstep:每轮中,无前置依赖未满足的节点可被调度(并行潜力由图结构决定);状态按 reducer 合并后再进入下一轮,直到到达 END 或无节点可运行。
2.2 compile() 与运行时可配置项
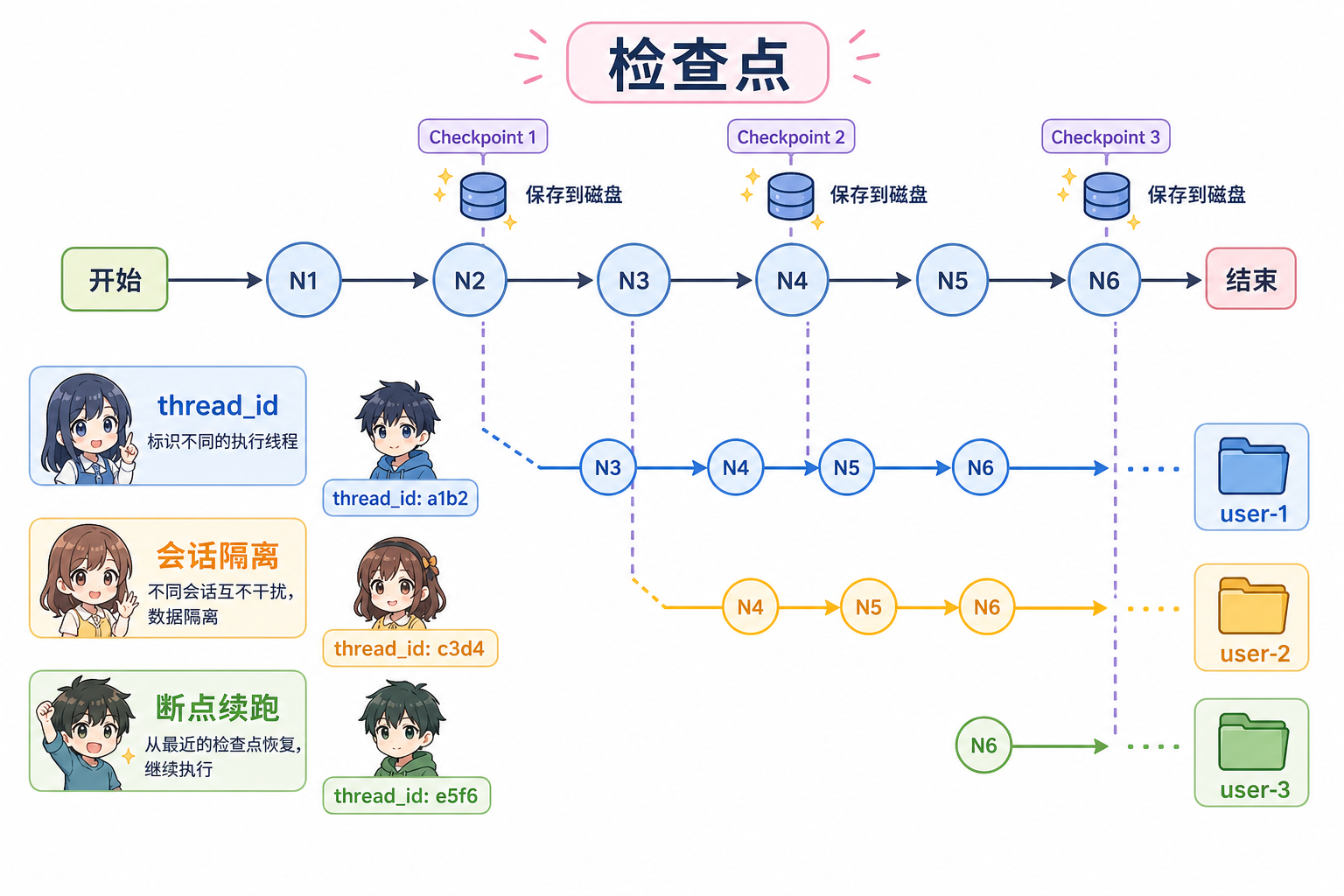
graph = builder.compile(...)生成可调用对象;可注入 checkpointer、interrupt 策略、调试回调等。config["configurable"]["thread_id"]:逻辑会话键;检查点按thread_id隔离,实现多租户会话与断点续跑。
2.3 检查点(checkpoint)与持久化
- 检查点在节点边界落盘(或存内存):保存状态快照与待调度集等元数据,使你可以:
- 进程崩溃后从上次节点恢复;
- 在审批节点暂停,待人输入后再 resume;
- 做「时间旅行」式调试(回溯历史状态)。
- 生产常见 PostgreSQL / Redis 等 Saver;本地开发常用
InMemorySaver。
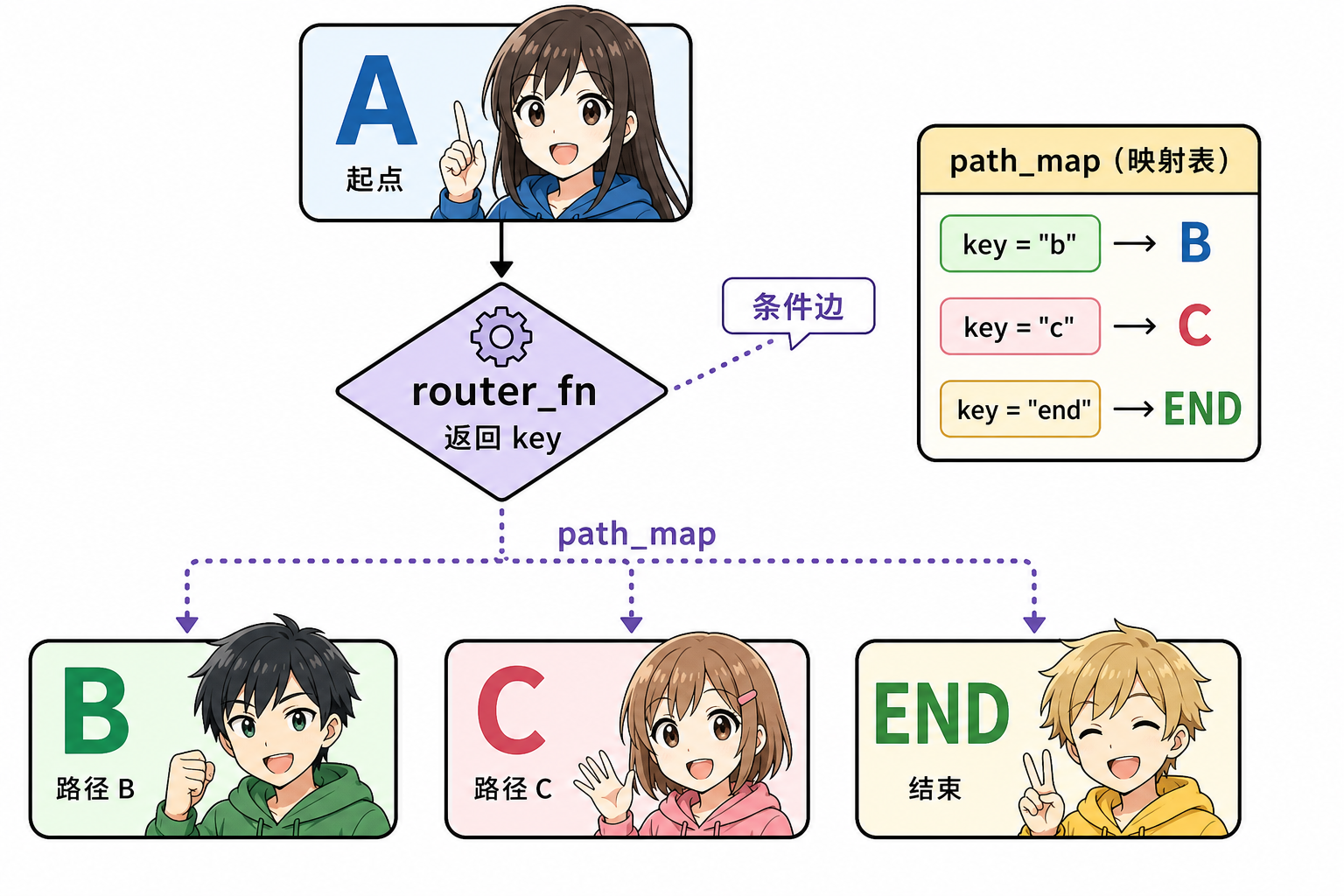
2.4 条件边与「动态路由」
add_conditional_edges("node_a", router_fn):router_fn(state) -> str返回下一节点名(或预定义的 END),实现 LLM 决定走「检索 / 直接答 / 调用工具」等分支。- 与硬编码
if相比,路由逻辑仍在你写的 Python 里,可控、可测;与完全黑盒 Agent 相比,图结构本身即文档。
2.5 与 LangChain 组件的关系
节点内部通常仍调用 ChatModel、Tool、Retriever 等 LangChain 抽象;LangGraph 负责何时调用、状态如何累积、如何持久化与中断——分工上是「编排层」与「能力层」。
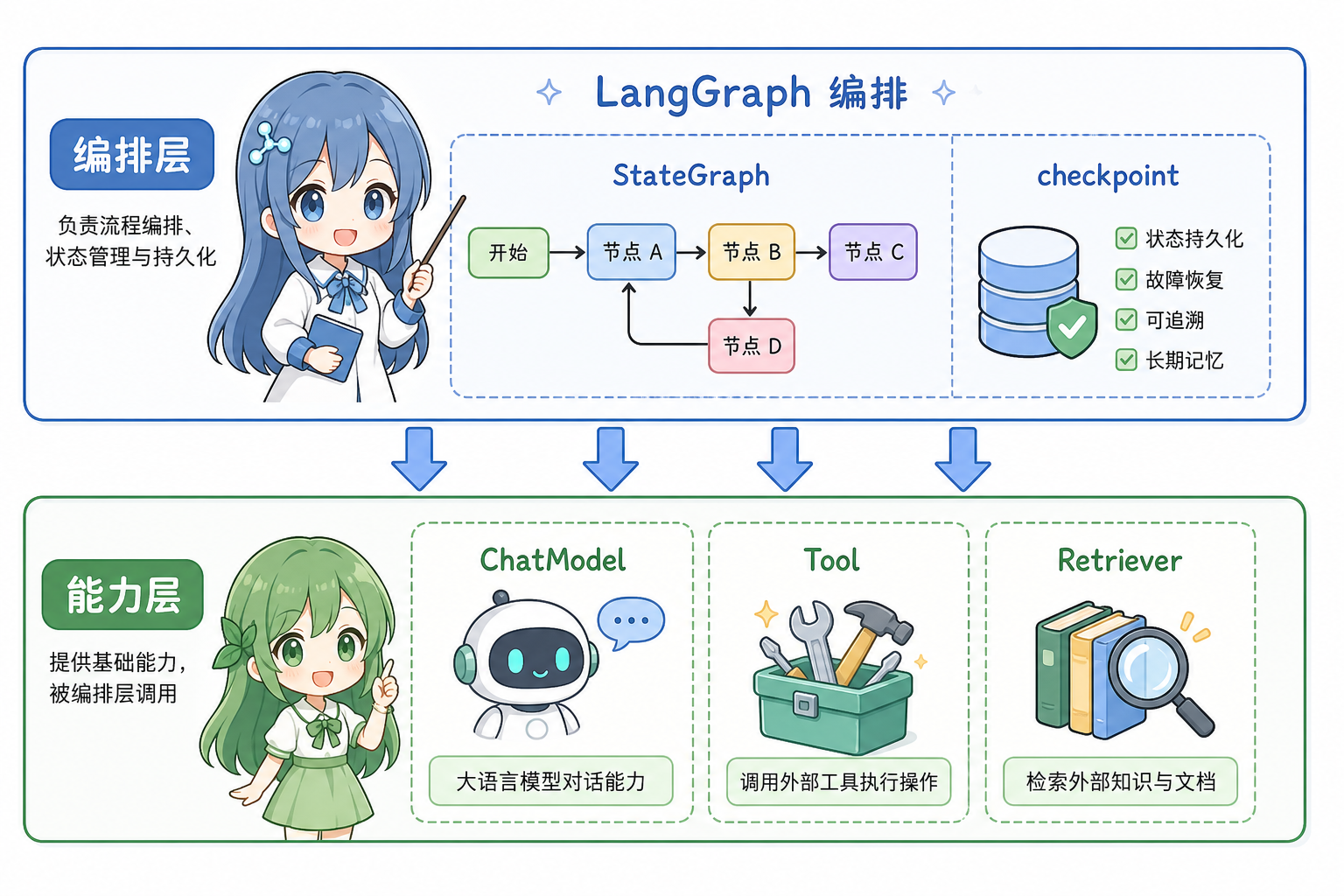
3. 优势与劣势
优势
- 显式控制流:图即设计文档,便于 Code Review(代码评审)与合规审计(对比完全自由文本 Agent)。
- 原生循环与重试:工具失败 → 回到 LLM 再规划,无需用递归提示词 hack。
- 检查点一等公民:HITL、容错、多轮会话与「从某步重放」有统一抽象。
- 流式与部分输出:
stream_mode等可与 SSE / WebSocket 对齐,利于产品化。
劣势
- 概念与样板偏多:
State/ reducer / checkpointer / interrupt 学习曲线陡于「单文件 Agent」。 - 生态绑定:与 LangChain 版本、包拆分(
langgraph、langchain-core等)强相关,升级需跟发行说明(release notes)。 - 过度设计风险:简单问答硬上图会增加文件数与心智负担。
- 分布式与并发:单机图编排清晰;多机多实例时要自己处理 thread_id、外部存储一致性与幂等。
4. 优势场景(何时优先选 LangGraph)
- 多工具、多步、可失败重试的 Agent(客服、运维 SOP、研究助理)。
- 需要 HITL:支付、删库、对外发信等高风险动作前必须人工点确认。
- 需要 可恢复的长任务:爬虫 + 总结 + 入库,任一步崩溃可从检查点续跑。
- 多分支 RAG:先路由到不同知识库 / 不同 prompt,再合并答案。
- 要把 LLM 应用做成可观测服务:节点级日志、指标与状态快照对齐。
5. 代码示例
以下示例与上文 条件边示意(START → router → path_map → 子节点)的拓扑一致,可直接对照理解 add_conditional_edges 三参数写法。
以下示例基于当前主流的 langgraph Python API 写法;安装可参考:
1 | pip install langgraph langchain-core langchain-openai |
(模型与 API Key 请用环境变量配置;示例用占位说明。)
5.1 最小线性图:单节点接 END
1 | from typing import Annotated, TypedDict |
要点:add_messages 把各节点返回的 messages 追加合并,而不是整表替换。
5.2 条件边:根据最后一条消息是否含「搜索」关键字分支
1 | from langgraph.graph import StateGraph, START, END |
要点:router 返回值须与 path_map 的键一致,并由 path_map 映射到已注册节点名;若某分支直接结束,可将该键映射到 END(视 LangGraph 版本在 path_map 中写 END 常量)。
5.3 检查点 + thread_id:多轮对话在内存中持久
1 | from langgraph.checkpoint.memory import InMemorySaver |
要点:同一 thread_id 的多次 invoke 共享检查点链;换 thread_id 即新会话。
6. 落地建议
- 先画状态与边,再写节点;
State字段越少越好,避免「万能字典」。 - 路由函数保持纯:尽量只读
state与轻量规则;重逻辑放独立节点,便于单测。 - 生产持久化优先选官方支持的 Saver;内存 Saver 仅用于开发与单测。
- 关注官方文档版本:Graph API、Persistence / checkpointing。
小结
LangGraph 用显式状态图 + 检查点把 Agent 编排从「提示词驱动」提升为「可恢复、可审计的控制流」;代价是学习成本与 LangChain 生态耦合。适合多步工具、HITL 与长任务容错;简单单次 RAG 则不必强行上图。
段末注释:TypedDict 为 PEP 589 描述的字典类型提示;reducer 指多写入方合并状态的函数(LangGraph 内置
add_messages等)。