文本嵌入是文本的向量表示,它编码了语义信息。由于机器需要数值输入来进行计算,文本嵌入是许多下游 NLP 应用的关键组成部分。例如,谷歌使用文本嵌入来驱动其搜索引擎。文本嵌入还可用于通过聚类在大量文本中发现模式,或作为文本分类模型的输入,例如在我们最近的 SetFit 工作中。然而,文本嵌入的质量高度依赖于所使用的嵌入模型。openAI,gemini,阿里、火山、豆包都有各自开发的嵌入模型。所以对于使用者,有一个相对成熟标准的评估方法至关重要,这可以让我们更直观的感受不同嵌入模型的异同优劣。
所以在这里介绍一些评估嵌入模型性能的常见基准数据集和方法。
MTEB:大规模文本嵌入基准
MTEB 是一个用于衡量文本嵌入模型在各种嵌入任务上性能的大规模基准。包含 8 个任务的 58 个数据集,包含多达 112 种不同语言(紫色阴影数据)。目前在排行榜上总结了超过 2000 个结果。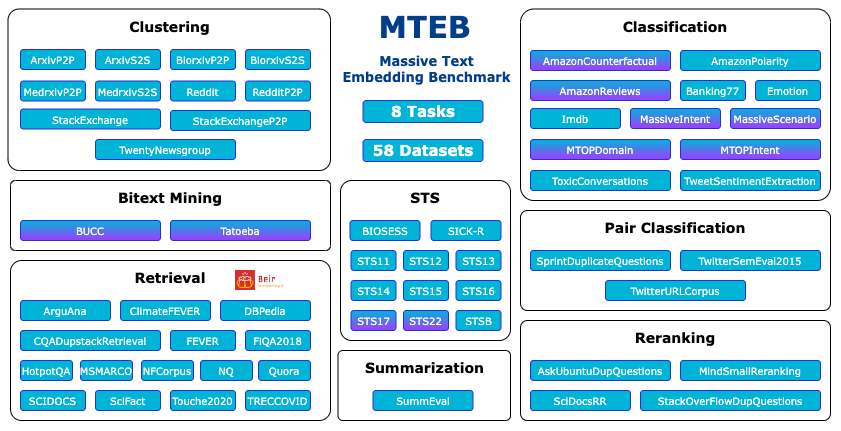
评估结果
🥇 排行榜 全面展示了在各种任务中最优秀的文本嵌入模型。并且提供了多个维度的对比,从表现、到模型大小、 不同任务、不同语言的表现。
📝 论文 介绍了 MTEB 中任务和数据集的背景,并分析了排行榜的结果!
💻 Github 仓库 包含了用于基准测试和将任何您选择的模型提交到排行榜的代码。
评估使用方法
安装 mteb 库
1 | pip install mteb |
接下来,在一个数据集上对模型进行基准测试,例如在 Banking77 上测试 komninos 词嵌入。
1 | from mteb import MTEB |
这应该会生成一个 results/average_word_embeddings_komninos/Banking77Classification.json 文件!
现在,您可以通过将其添加到 Hub 上任何模型的 README.md 文件的元数据中,将结果提交到排行榜。
运行我们的自动脚本来生成元数据
1 | python mteb_meta.py results/average_word_embeddings_komninos |
该脚本将生成一个 mteb_metadata.md 文件,内容如下:
1 | tags: |
CMTEB
CMTEB(Chinese Massive Text Embedding Benchmark)是一个专门针对中文文本向量的评测基准,它基于MTEB构建,旨在评测中文文本向量模型的性能,是目前业界公认的最全面、最权威的中文文本嵌入模型评测基准。CMTEB收集了35个公共数据集,并分为6类评测任务,包括
- 文本分类(classification):使用嵌入训练逻辑回归模型,主要评估指标为F1值
- 文本聚类(clustering):使用mini-batch k-means算法(批大小32,k等于类别数),评估指标为v-measure
- 句子对分类(pair classification):判断两个文本是否属于同一类别,主要指标为平均精度得分
- 重排序(reranking):对相关和不相关文本进行排序,评估指标为MRR@k和MAP
- 检索(retrieval):从语料库中检索相关文档,主要指标为nDCG@k
- 语义文本相似度(STS):评估句子对的相似度,使用基于余弦相似度的Spearman相关系数
评测方法
1 | # 首先需要安装必要的依赖包: |