对于一个机器学习问题,数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限。由此可见,数据和特征在模型的整个开发过程中是比较重要。特征工程,顾名思义,是对原始数据进行一系列工程处理,将其提炼为特征,作为输入供算法和模型使用。从本质上来讲,特征工程是一个表示和展现数据的过程。在实际工作中,特征工程旨在去除原始数据中的杂质和冗余,以设计更高效的特征以刻画求解的问题与预测模型之间的关系。
虽然说理论上只要我们能掌握一类事件的全部特征,并理解特征在整个事件种发挥的作用,我们就可以预测一件事情发生的过程细节,并精准的获取事件的走向和结果。但是显然这会带来巨大的计算成本,让我们对于一些无足轻重的事情花费巨大的代价(比如预测一个某个患者的生存周期,我们不可能去考虑他出交通事故的可能性,更不可能考虑第三次世界大战的发生导致死亡);当然除了更多的计算成本外,随着特征的增加,我们必须也要补充对应的训练样本,来捕获所有的特征数据及每个特征的作用(权重。所以在实际的模型应用中并不是特征越多越好,特征越多固然会给我们带来很多额外的信息,但是与此同时,一方面,这些额外的信息也增加实验的时间复杂度和最终模型的复杂度,造成的后果就是特征的“维度灾难”,使得计算耗时大幅度增加;另一方面,可能会导致模型的复杂程度上升而使得模型变得不通用。所以我们就要在众多的特征中选择尽可能相关的特征和有效的特征,使得计算的时间复杂度大幅度减少来简化模型,并且保证最终模型的有效性不被减弱或者减弱很少,这也就是我们特征选择的目的。
一般来说,如果特征过多,我们都会在特征工程里面减少输入的特征。其中一种方案,就是进行特征筛选,直接对输入的特征进行维度的过滤。减少模型的特征输入。
剔除方差过低的数据
选择特征的最简单方法是删除方差非常小的特征。如果特征的方差非常小(即非常接近于 0),它们就接近于常量,因此根本不会给任何模型增加任何价值。最好的办法就是去掉它们,从而降低复杂度。请注意,方差也取决于数据的缩放。 Scikit-learn 的 VarianceThreshold 实现了这一点。
1 | from sklearn.feature_selection import VarianceThreshold |
剔除高相关特征
我们还可以删除相关性较高的特征。要计算不同数字特征之间的相关性,可以使用皮尔逊相关性。
1 | import pandas as pd |
我们可以针对所有数值型的特征得到相关性矩阵,然后针对一些强相关的特征进行剔除。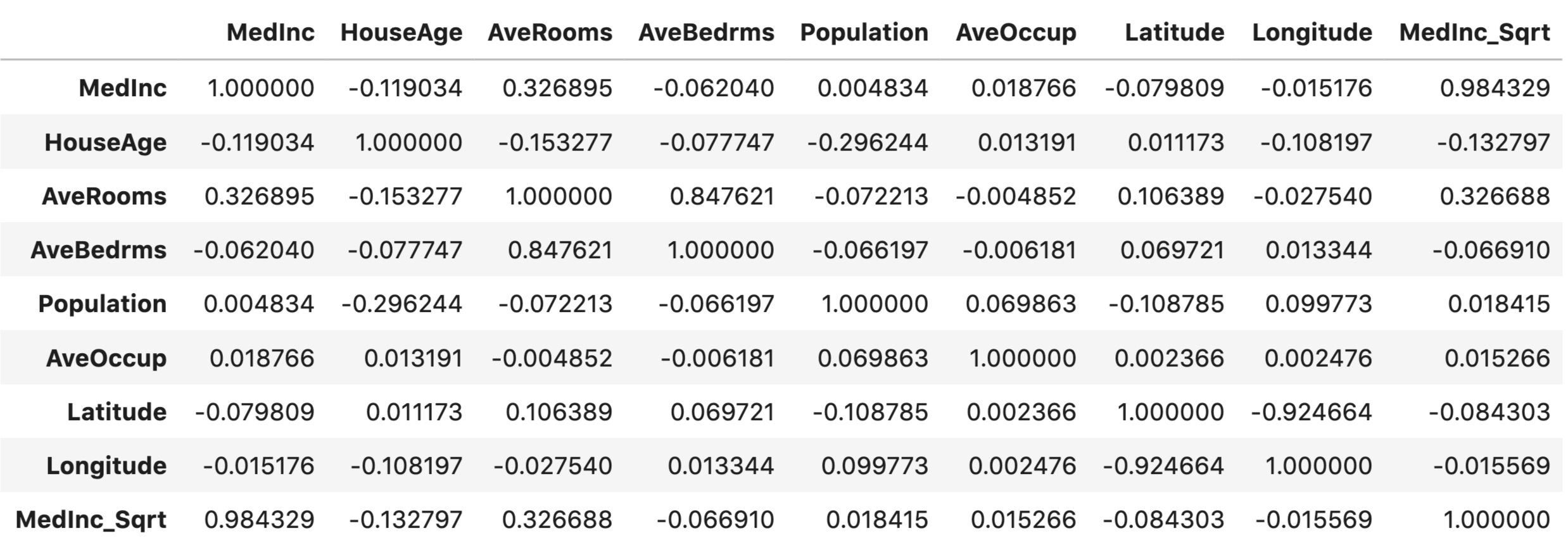
我们看到, MedInc_Sqrt 与 MedInc 的相关性非常高(0.9843)。因此,我们可以删除其中一个特征。
单变量选择
单变量特征选择是针对给定目标对每个特征进行评分。互信息、方差分析 F 检验和卡方检验(非负数据才能使用卡方检验) 是一些最常用的单变量特征选择方法。在 scikit- learn 中,有两种方法可以使用这些方法。
- SelectKBest:保留得分最高的 k 个特征;
- SelectPercentile:保留用户指定百分比内的顶级特征。
在自然语言处理中,当我们有一些单词或基于 tf-idf 的特征时,这是一种特别有用的特征选择技术。我们可以为单变量特征选择创建一个包装器,从而可以用于未来的新问题进行特征选择。
1 | from sklearn.feature_selection import chi2 |
贪婪特征选择
前面的方法起始都是从特征本身入手,筛选过程和下游方法可能关系没有那么大。而贪婪特征选择的方法是和我们要应用的模型强相关的。在贪婪特征选择中:
- 第一步是选择一个模型。
- 第二步是选择损失/评分函数。
- 第三步也是最后一步是反复评估每个特征,如果能提高损失/评分,就将其添加到 “好 “特征列表中。
这个逻辑本身很直接。但是需要注意这种特征选择过程在每次评估特征时都会适合给定的模型。而且相当于在遍历各种可能的情况,所以这种方法的化,计算量会非常大。
1 | import pandas as pd |
贪婪特征选择方法,会不断的遍历所有的特征,每次遍历会得到剩余特征中带来帮助最大(模型预测得分提升最高)的一个特征,将最优特征放入特征列表(在下一轮会作为固定特征使用),直至特征的增加不会带来性能的帮助(或者现有的特征已经能达到我们所要求的性能需求),会返回得分和特征列表。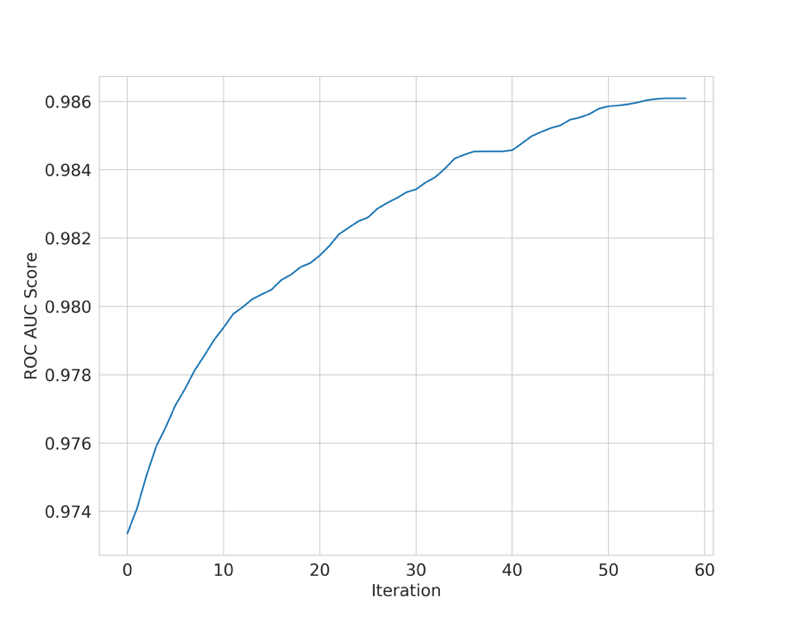
递归特征消除法
贪婪特征选择,我们是从1个特征开始,不断的添加特征,而递归特征消除法则是从所有特征开始,剔除一个对模型帮助最小的特征(线性支持向量机(SVM)或逻辑回归等模型,我们会为每个特征得到一个系数,该系数决定了特征的重要性。而对于任何基于树的模型,我们得到的是特征重要性,而不是系数。在每次迭代中,我们都可以剔除最不重要的特征,直到达到所需的特征数量为止)。
进行递归特征剔除时,在每次迭代中,我们都会剔除特征重要性较高的特征或系数接近 0 的特征。基于之前的贪婪特征选择代码我们可以很容易实现反向的特征剔除。同时 scikit-learn 也提供了 RFE。下面的示例展示了一个简单的用法。
线性回归示例
1 | import pandas as pd |
随机森林示例
1 | import pandas as pd |
我们可以看到不同特征的重要性因子如下图。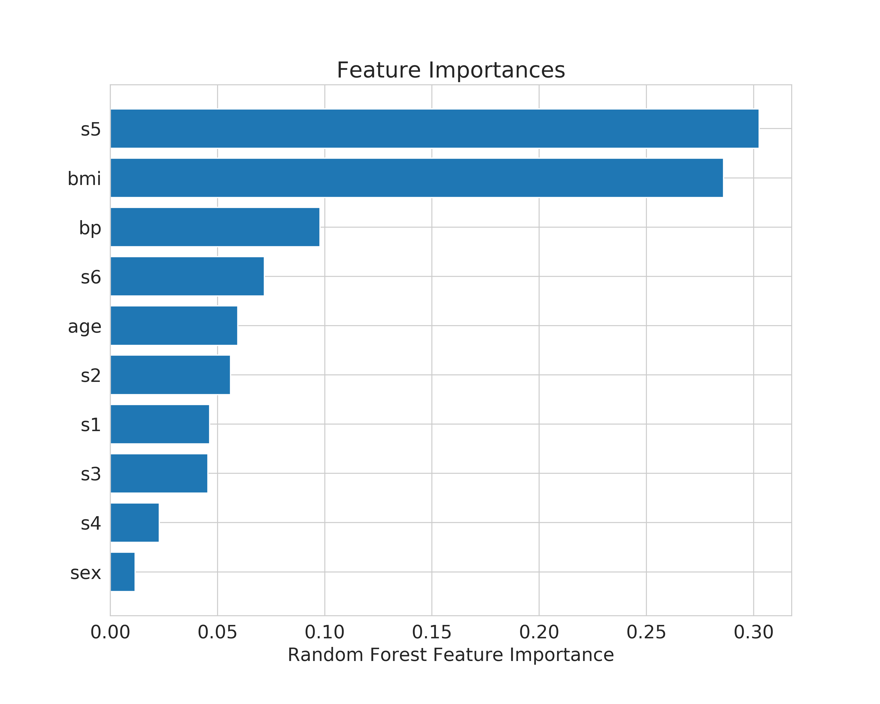
原文链接