交叉检验是构建机器学习模型过程中的一个步骤,它可以帮助我们确保模型准确拟合数据,同时确保我们不会过拟合。
起始随着深度学习的兴起,我们可以想想一下,只要我们的特征足够多,那么任何问题我们都可以在训练集达到 100% 的性能。甚至最极端的方法,我们的分析方法甚至于完全可以采用枚举的方法(当然这是不对的)这种随着特征的过度增加,或者方法的过度复杂,训练集的性能虽然不断提升,但是测试集却开始变差。那这时就进入了过拟合的状态。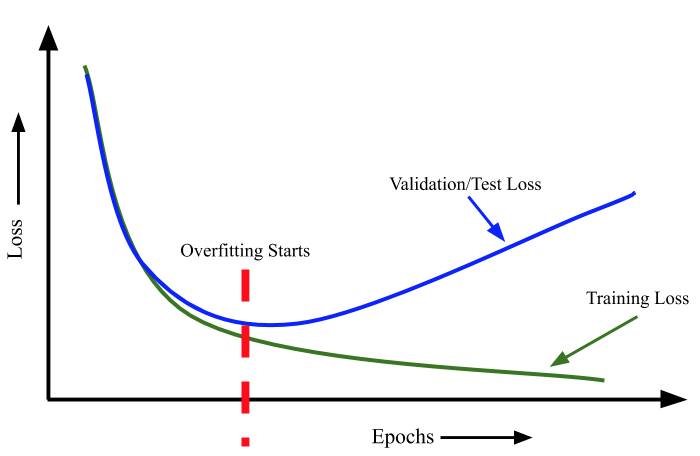
因此除了训练数据外,我们总是需要一些测试数据来评估我们的模型,来确认我们模型的泛化能力。这时候,常采用的方法就是进行交叉检验,交叉检验是将训练数据分层几个部分,我们在其中一部分上训练模型,然后在其余部分上进行测试。常用的交叉检验方法如下:
k 折交叉检验
其中一种方法是将我们的数据平均分为 k 个互不关联的不同集合。这就是所谓的 k 折交叉检验。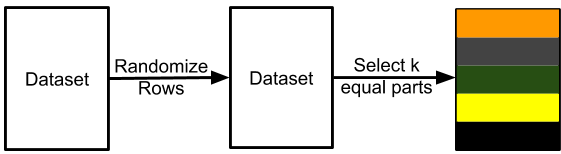
每个样本分配一个从 0 到 k-1 的值。
1 | # 导入 pandas 和 scikit-learn 的 model_selection 模块 |
分层 k 折交叉检验
K折交叉检验,针对正常数据已经够用了,但是有时候,我们拿到的数据可能并不是均匀分布的,比如阴阳性比例悬殊,极端点,可能有 90% 的数据是阴性,只有 10% 的数据是阳性。这时候简单的k折可能会导致 10%的阳性样本基本都分到训练集,导致测试集基本都是阴性样本。这类数据使用 分层k折交叉检验 可以规避掉数据分布不均的问题。
分层 k 折交叉检验可以保持每个折中标签的比例不变。因此,在每个折叠中,都会有相同的 90% 正样本和 10% 负样本。因此,无论您选择什么指标进行评估,都会在所有折叠中得到相似的结果。
1 | # 导入 pandas 和 scikit-learn 的 model_selection 模块 |
分层k折交叉检验基本上全方位优于k折交叉检验,所以起始可以默认使用分层。
暂留交叉检验
上面的方法是针对比较小的数据量,我们会同时计算训练集和测试集的性能表现。
但是假设我们有 100 万个样本。5 倍交叉检验意味着在 800k 个样本上进行训练,在 200k 个样本上进行验证。根据我们选择的算法,对于这样规模的数据集来说,训练甚至验证都可能非常昂贵。在这种情况下,我们可以选择暂留交叉检验。
创建保持结果的过程与分层 k 折交叉检验相同。对于拥有 100 万个样本的数据集,我们可以创建 10 个折叠而不是 5 个,并保留其中一个折叠作为保留样本。这意味着,我们将有 10 万个样本被保留下来,我们将始终在这10W的保留样本集上计算损失、准确率和其他指标,并在 90 万个样本上进行训练。
留一交叉检验
在很多情况下,我们必须处理小型数据集,而使用大量数据用于验证意味着模型学习过程能使用的训练数据非常有限。在这种情况下,我们可以选择留一交叉检验,相当于特殊的 k 折交叉检验其中 k=N ,N 是数据集中的样本数。这意味着在所有的训练折叠中,我们将对除 1 之外的所有数据样本进行训练。这种类型的交叉检验的折叠数与数据集中的样本数相同。只留一例样本进行验证,剩下的样本都用于训练集,只适合非常小型的数据集,基本用不到。