初识SVM算法
支持向量机(Support Vector Machine,SVM)是一种经典的监督学习算法,用于解决二分类和多分类问题。其核心思想是通过在特征空间中找到一个最优的超平面来进行分类,并且间隔最大。它的基本模型是定义在特征空间上的间隔最大的线性分类器,间隔最大使它有别于感知机;SVM还包括核技巧,这使它成为实质上的非线性分类器。SVM的的学习策略就是间隔最大化,可形式化为一个求解凸二次规划的问题,也等价于正则化的合页损失函数的最小化问题。SVM的的学习算法就是求解凸二次规划的最优化算法。
SVM能够执行线性或非线性分类、回归,甚至是异常值检测任务。它是机器学习领域最受欢迎的模型之一。SVM特别适用于中小型复杂数据集的分类
SVM算法原理
SVM通过优化一个凸二次规划问题来求解最佳的超平面,其中包括最小化模型的复杂度(即最小化权重的平方和),同时限制训练样本的误分类情况。这个优化问题可以使用拉格朗日乘子法来求解。对于非线性可分的情况,SVM可以通过核函数(Kernel Function)将输入特征映射到高维空间,使得原本线性不可分的数据在高维空间中变得线性可分。常用的核函数包括线性核、多项式核、高斯核等。
硬间隔和软间隔:
硬间隔分类:
在上面我们使用超平面进行分割数据的过程中,如果我们严格地让所有实例都不在最大间隔之间,并且位于正确的一边,这就是硬间隔分类。
硬间隔分类有两个问题,首先,它只在数据是线性可分离的时候才有效;其次,它对异常值非常敏感。
当有一个额外异常值的鸢尾花数据:左图的数据根本找不出硬间隔,而右图最终显示的决策边界与我们之前所看到的无异常值时的决策边界也大不相同,可能无法很好地泛化。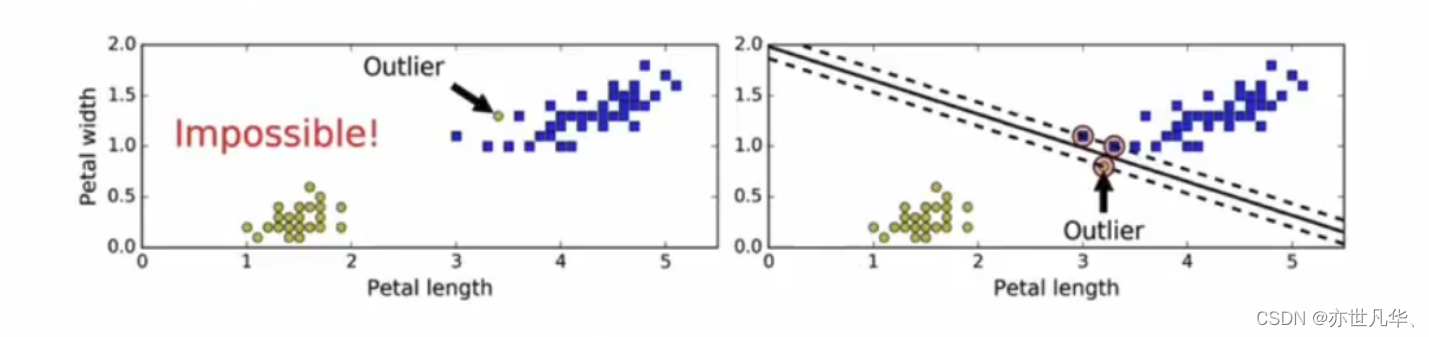
软间隔分类:
要避免这些问题,最好使用更灵活的模型。目标是尽可能在保持最大间隔宽阔和限制间隔违例(即位于最大间隔之上,甚至在错误的一边的实例)之间找到良好的平衡,这就是软间隔分类。
在Scikit-Learn的SVM类中,可以通过超参数C来控制这个平衡:C值越小,则间隔越宽,但是间隔违例也会越多。上图显示了在一个非线性可分离数据集上,两个软间隔SVM分类器各自的决策边界和间隔。
左边使用了高C值,分类器的错误样本(间隔违例)较少,但是间隔也较小。
右边使用了低C值,间隔大了很多,但是位于间隔上的实例也更多。看起来第二个分类器的泛化效果更好,因为大多数间隔违例实际上都位于决策边界正确的一边,所以即便是在该训练集上,它做出的错误预测也会更少。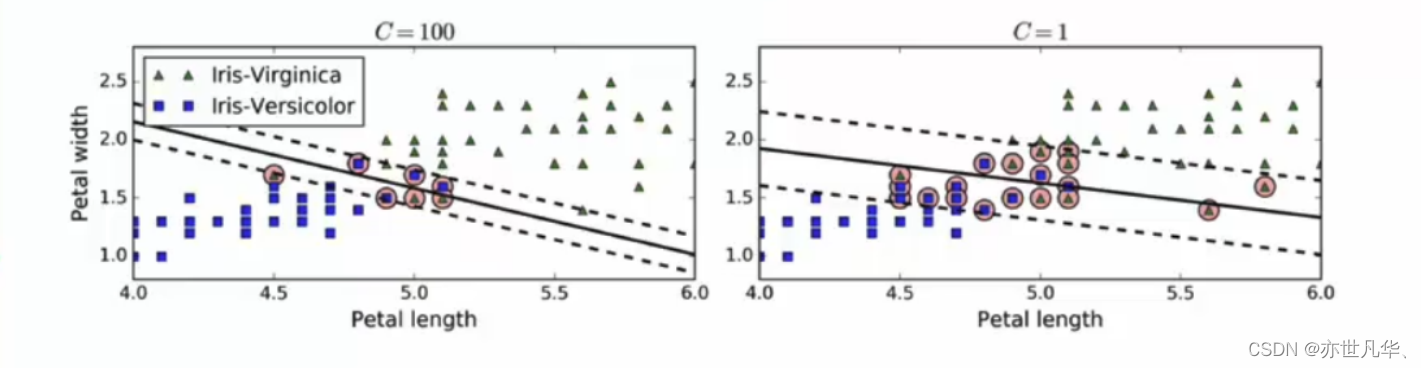
SVM算法的优点:
1)SVM方法既可以用于分类(二/多分类),也可用于回归和异常值检测。
2)SVM具有良好的鲁棒性,对未知数据拥有很强的泛化能力,特别是在数据量较少的情况下,相较其他传统机器学习算法具有更优的性能。
使用SVM作为模型时,通常采用如下流程:
1)对样本数据进行归一化
2)应用核函数对样本进行映射(最常采用和核函数是RBF和Linear,在样本线性可分时,Linear效果要比RBF好)
3)用cross-validation和grid-search对超参数进行优选
4)用最优参数调练得到模型
5)测试