← 上级:RL-02.原理与数学基础 · 前置:RL-02-01-MDP与Bellman方程
价值函数回答「有多好」;策略回答「怎么做」。本文厘清 $V$ 与 $Q$ 的换算、如何从 $Q^$ 得到 $\pi^$,以及策略改进定理为何保证贪心迭代不会变差。
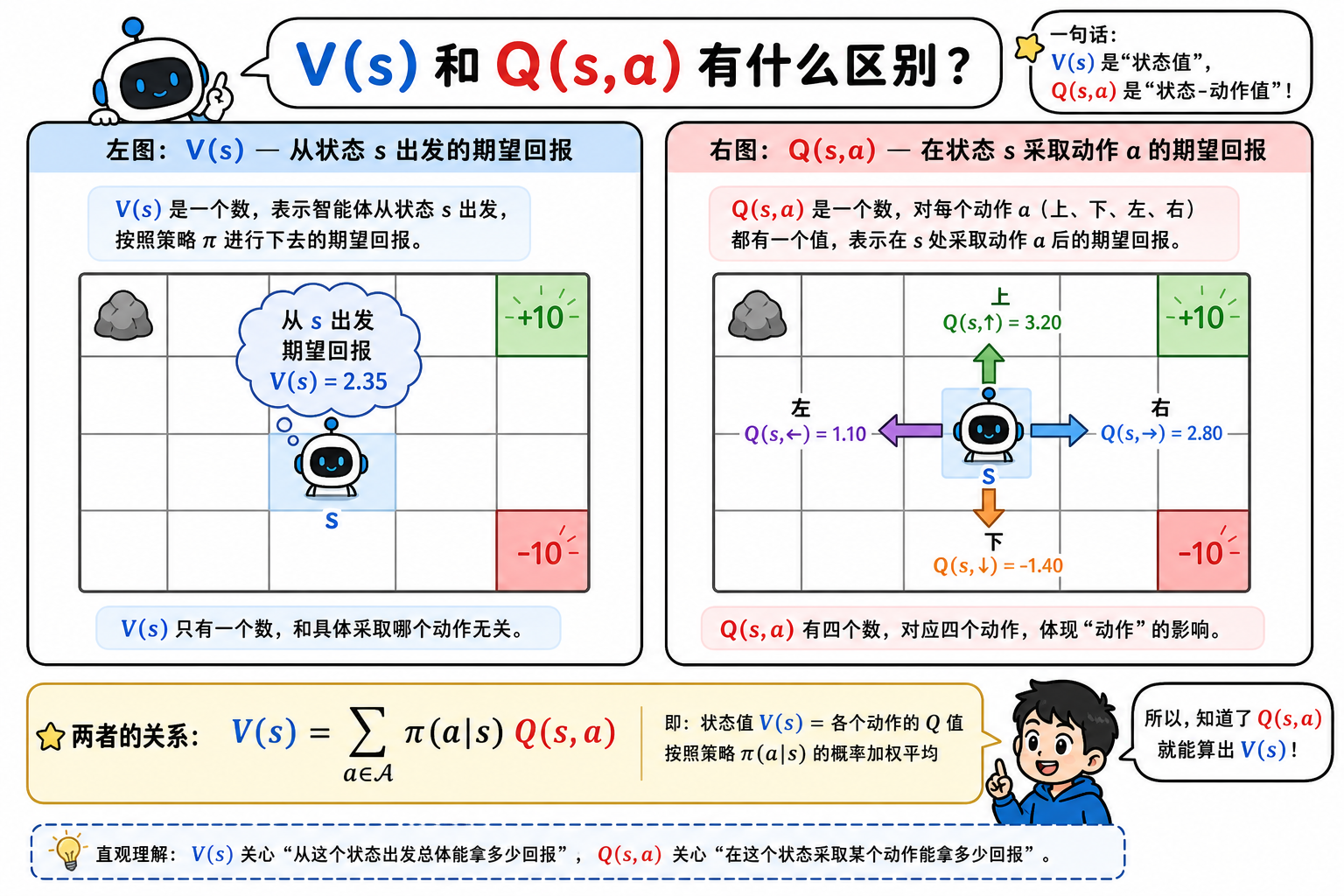
一、两种价值函数
| 函数 | 定义 | 问的问题 |
|---|---|---|
| $V^\pi(s)$ | $\mathbb{E}_\pi[G_t \mid S_t=s]$ | 在 $s$ 按 $\pi$ 走,期望多好? |
| $Q^\pi(s,a)$ | $\mathbb{E}_\pi[G_t \mid S_t=s, A_t=a]$ | 在 $s$ 先做 $a$ 再按 $\pi$,期望多好? |
关系(对同一策略 $\pi$):
$$
V^\pi(s) = \sum_{a \in A(s)} \pi(a|s) , Q^\pi(s,a)
$$
$$
Q^\pi(s,a) = \sum_{s’} P(s’|s,a) \left[ R(s,a,s’) + \gamma V^\pi(s’) \right]
$$
第二式:$Q$ 展开一步转移后,后继按 $\pi$ 的期望价值即 $V^\pi(s’)$。
二、最优价值与最优策略
上标 $*$ 表示 最优(在所有策略中取期望回报最大);上标 $\pi$ 表示 在该策略下。详见 RL-01-01-术语与符号约定 第四节。
$$
V^(s) = \max_\pi V^\pi(s), \qquad Q^(s,a) = \max_\pi Q^\pi(s,a)
$$
确定性最优策略(任一状态至少一个最优动作):
$$
\pi^(s) \in \arg\max_a Q^(s,a)
$$
若多个动作并列最大,任选一个即可(需保证所有状态可达性等条件)。
从 $V^*$ 导出:
$$
\pi^(s) = \arg\max_a \sum_{s’} P(s’|s,a) \left[ R(s,a,s’) + \gamma V^(s’) \right]
$$
三、策略改进定理(Policy Improvement Theorem)
设 $\pi’ = \text{greedy}(V^\pi)$,即:
$$
\pi’(s) = \arg\max_a \sum_{s’} P(s’|s,a) \left[ R + \gamma V^\pi(s’) \right]
$$
则对所有 $s$:
$$
V^{\pi’}(s) \geq V^\pi(s)
$$
直觉:$\pi’$ 在每个状态都选「对当前 $V^\pi$ 看起来最好」的动作,不会比 $\pi$ 更差。严格相等当且仅当 $\pi$ 已最优。
推论:策略迭代单调改进,有限 MDP 下必收敛到 $\pi^*$。
四、策略迭代 vs 价值迭代
| 策略迭代 | 价值迭代 | |
|---|---|---|
| 每轮 | 完整评估 $V^\pi$ + 贪心改进 | 直接用 Bellman 最优 更新 $V$ |
| 更新式 | 期望方程(固定 $\pi$) | $V(s) \leftarrow \max_a \sum_{s’} P[\cdots]$ |
| 收敛 | 策略稳定即停 | $V$ 变化小于阈值 |
| 特点 | 每轮评估可能很慢 | 常更少轮数,但最后需导出 $\pi$ |
两者在极限下都得到 $V^$ 与 $\pi^$(表格、有限 MDP)。算法实现见 RL-03-01-算法-动态规划。
五、$V$ 与 $Q$ 在算法中的分工
| 算法 | 主要估计 | 动作选择 |
|---|---|---|
| Q-Learning / DQN | $Q$ | $\arg\max_a Q(s,a)$ |
| SARSA | $Q$ | 同左(但更新 On-Policy) |
| PPO / A2C | $V$ 或 $Q$ | $\pi_\theta(a |
| Actor-Critic | $V$ + $\pi$ | Actor;Critic 供优势 |
Dueling DQN 显式分解 $Q(s,a) = V(s) + A(s,a) - \text{mean}_a A(s,a)$,见 DQN 变体。
六、优势函数(衔接 Actor-Critic)
$$
A^\pi(s,a) = Q^\pi(s,a) - V^\pi(s)
$$
含义:在 $s$ 选 $a$ 比「按 $\pi$ 平均水平」好多少。策略梯度中用 $\hat{A}$ 替代 $G_t$ 降方差,见 RL-03-09-算法-Actor-Critic。
七、存在性与唯一性(梗概)
有限状态、有界奖励、$\gamma < 1$ 时:
- $V^$、$Q^$ 存在且唯一(Bellman 最优算子的压缩映射)。
- 压缩系数 $\gamma$:迭代 $V_{k+1} = \mathcal{T}^* V_k$ 以 $\gamma$ 速率收敛。
八、与后续算法链接
1 | V*, Q* (Bellman 最优) |
九、小结
- $V^\pi$ 是 $Q^\pi$ 在 $\pi$ 下的期望;$Q^$ 上 $\arg\max$ 得 $\pi^$。
- 策略改进定理保证贪心改进单调不降。
- 下一篇:探索与利用 · 算法:Q-Learning