← 系列入口:RL-00.系列概述 · 上一篇:RL-01.概述与问题建模
在 RL-01 中,我们用 Agent–Environment 循环建立了直觉。本文把该循环形式化为马尔可夫决策过程(Markov Decision Process,MDP),并导出价值函数与 Bellman 方程——几乎所有 RL 算法都是对这些对象的不同近似与更新方式。
段末注释:马尔可夫决策过程(Markov Decision Process,MDP)由状态集、动作集、转移概率、奖励与折扣因子构成;后文沿用 MDP。
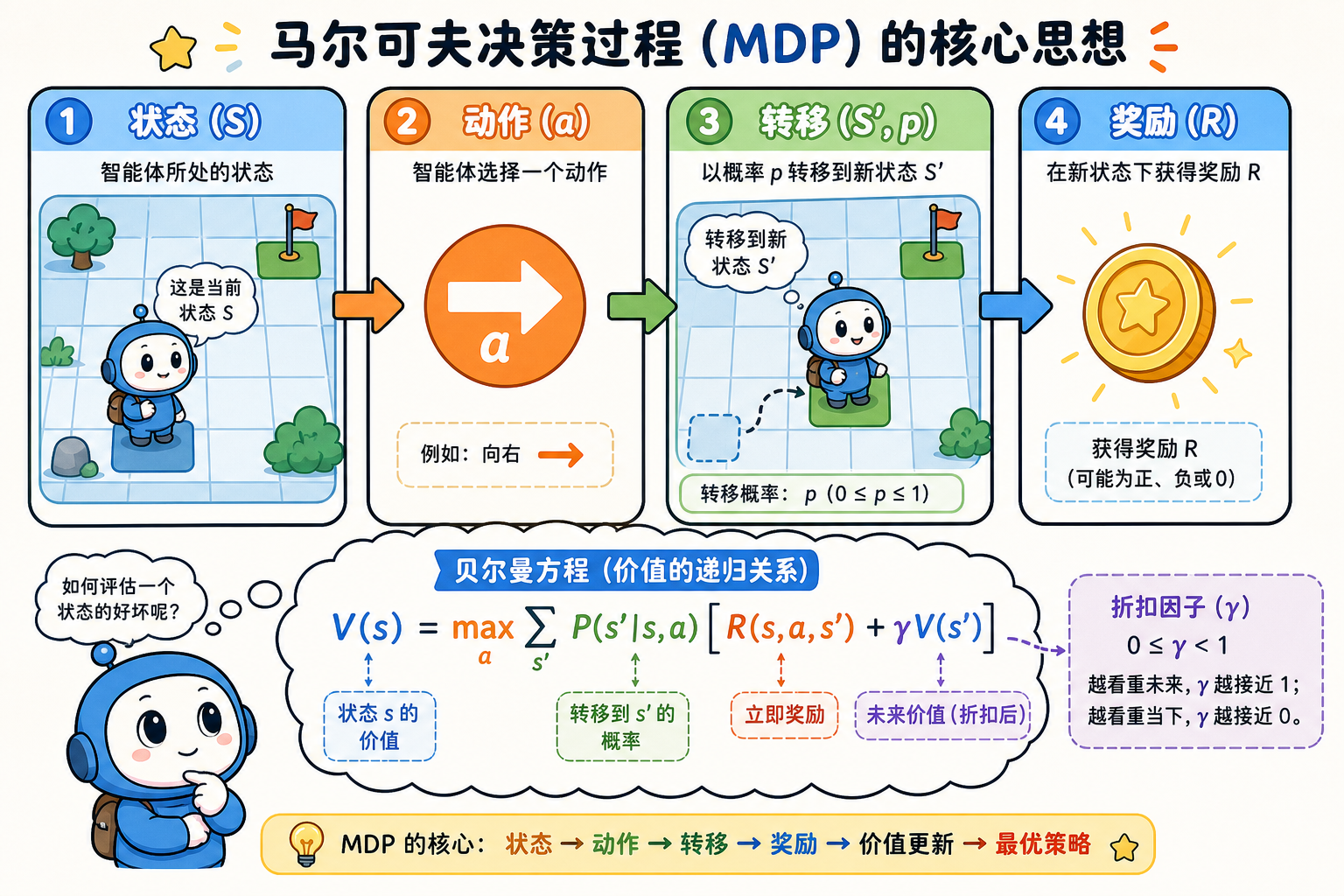
一、MDP 五元组
一个 MDP 记为 $(S, A, P, R, \gamma)$:
| 符号 | 含义 |
|---|---|
| $S$ | 状态空间 |
| $A$ | 动作空间(可与 $s$ 有关,记 $A(s)$) |
| $P(s’|s,a)$ | 转移概率:在 $s$ 执行 $a$ 后进入 $s’$ 的概率 |
| $R(s,a,s’)$ 或 $R(s,a)$ | 期望即时奖励 |
| $\gamma \in [0,1]$ | 折扣因子 |
马尔可夫性:下一状态只依赖当前 $(s,a)$,与更早历史无关(给定当前状态)。若只有观测 $o$ 而非 $s$,则对应 POMDP。
二、策略与回报
策略 $\pi(a|s)$:在状态 $s$ 选择动作 $a$ 的概率(确定性策略可写 $a=\mu(s)$)。
从 $t$ 时刻起的折扣回报:
$$
G_t = \sum_{k=0}^{\infty} \gamma^k R_{t+k+1}
$$
优化目标:找到 $\pi^*$,使期望回报最大:
$$
J(\pi) = \mathbb{E}_{\tau \sim \pi}\left[ G_0 \right]
$$
三、价值函数
3.1 状态价值函数 $V^\pi(s)$
在策略 $\pi$ 下,从状态 $s$ 出发的期望回报:
$$
V^\pi(s) = \mathbb{E}_\pi\left[ G_t \mid S_t = s \right]
$$
3.2 动作价值函数 $Q^\pi(s,a)$
在 $s$ 先执行 $a$,之后按 $\pi$ 行动的期望回报:
$$
Q^\pi(s,a) = \mathbb{E}_\pi\left[ G_t \mid S_t = s, A_t = a \right]
$$
关系:$V^\pi(s) = \sum_a \pi(a|s) Q^\pi(s,a)$。
3.3 最优价值与最优策略
$$
V^(s) = \max_\pi V^\pi(s), \quad Q^(s,a) = \max_\pi Q^\pi(s,a)
$$
最优策略:$\pi^(a|s) = 1$ 当 $a = \arg\max_a Q^(s,a)$(并列最大时可任意打破平局)。
四、Bellman 方程
Bellman 方程把「当前价值」表达为「即时奖励 + 折扣后继价值」,是动态规划与 RL 更新的核心。
4.1 Bellman 期望方程(给定 $\pi$)
$$
V^\pi(s) = \sum_a \pi(a|s) \sum_{s’} P(s’|s,a) \left[ R(s,a,s’) + \gamma V^\pi(s’) \right]
$$
$$
Q^\pi(s,a) = \sum_{s’} P(s’|s,a) \left[ R(s,a,s’) + \gamma \sum_{a’} \pi(a’|s’) Q^\pi(s’,a’) \right]
$$
4.2 Bellman 最优方程
$$
V^(s) = \max_a \sum_{s’} P(s’|s,a) \left[ R(s,a,s’) + \gamma V^(s’) \right]
$$
$$
Q^(s,a) = \sum_{s’} P(s’|s,a) \left[ R(s,a,s’) + \gamma \max_{a’} Q^(s’,a’) \right]
$$
Q-Learning 即用采样近似上式右侧的 $\max_{a’} Q(s’,a’)$;策略迭代 / 价值迭代 则在已知 $P,R$ 时精确求解。
五、从 Bellman 到算法:三条更新路线
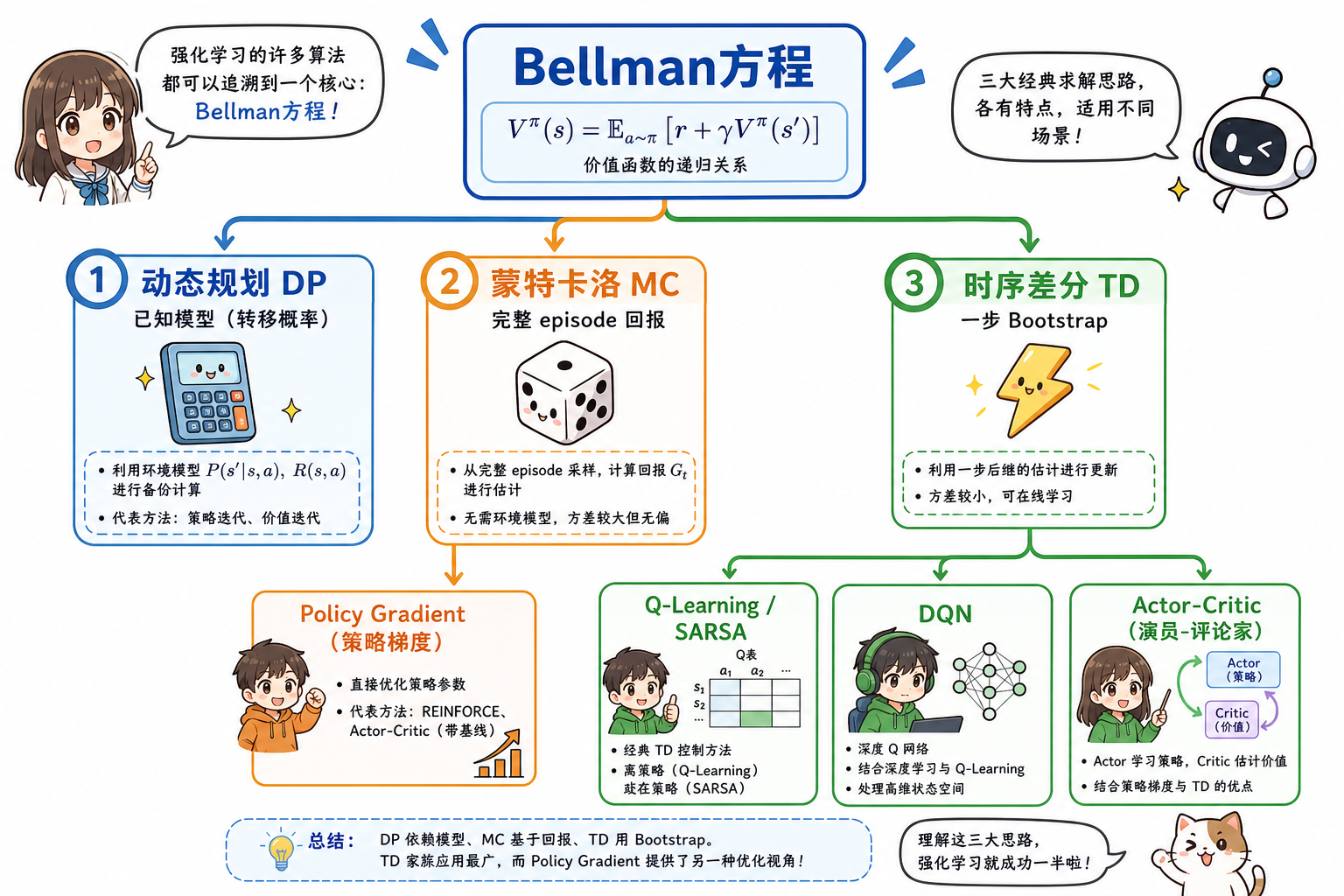
| 路线 | 是否需要模型 $P$ | 代表方法 |
|---|---|---|
| 动态规划 | 需要 | Policy Iteration, Value Iteration |
| 蒙特卡洛(Monte Carlo,MC) | 不需要 | 每局用完整 $G_t$ 更新 |
| 时序差分(Temporal Difference,TD) | 不需要 | TD(0), Q-Learning, SARSA, DQN |
段末注释:时序差分(Temporal Difference,TD)指用一步或多步的 Bootstrap 目标更新价值估计;后文沿用 TD。
六、探索与利用
仅最大化当前 $Q$ 估计会导致未试动作永不被探索。常用启发式:
| 方法 | 做法 |
|---|---|
| $\varepsilon$-greedy | 以概率 $\varepsilon$ 随机动作,否则 $\arg\max_a Q(s,a)$ |
| Softmax / Boltzmann | 按 $Q$ 值比例随机,温度参数控制探索程度 |
| UCB | 偏向上次尝试次数少的动作(多臂 bandit 经典) |
探索率 $\varepsilon$ 常随训练衰减:前期多探索,后期多利用。
七、Model-Based vs Model-Free(原理视角)
- Model-Based:显式学习或给定 $\hat{P},\hat{R}$,在模型内规划(如 Dyna、MCTS 结合学习)。
- Model-Free:不估计转移模型,直接学 $V/Q/\pi$(Q-Learning、PPO 等)。
环境模型未知时,工程上 Model-Free + Deep RL 更常见;见 RL-03.算法分类与选型。
八、本模块二级文档(已发布)
| 文档 | 内容 |
|---|---|
| RL-02-01-MDP与Bellman方程 | MDP 结构、折扣回报、Bellman 推导与算例 |
| RL-02-02-价值函数与策略 | $V$/$Q$ 关系、策略改进定理、价值/策略迭代 |
| RL-02-03-探索与利用 | MAB、$\varepsilon$-greedy、UCB、Softmax |
建议阅读顺序
九、阅读顺序
- 上一篇:RL-01.概述与问题建模
- 下一篇:RL-03.算法分类与选型
- 数据结构中的 Q 表对应 $Q(s,a)$ 的表格存储:RL-05.专属数据结构
十、小结
- MDP 把 RL 问题写为 $(S,A,P,R,\gamma)$ + 策略 $\pi$。
- $V$ / $Q$ 量化「有多好」;Bellman 方程 给出递归结构。
- 算法 = 在未知 $P$ 下对 Bellman 目标的 MC / TD / 梯度 采样更新。
- 下一篇:按 Model-Free、On/Off-Policy、Value/Policy 轴展开算法地图。