← 上级:RL-03.算法分类与选型 · 前置:RL-03-01-算法-动态规划 · 后续:RL-03-05-算法-时序差分
蒙特卡洛(Monte Carlo,MC)方法用完整 episode 的采样回报 $G_t$ 估计价值函数,不做 Bootstrap。它是 TD 与 Q-Learning 的采样理论对照,也用于 episode 短、需无偏估计的场景。
段末注释:蒙特卡洛(Monte Carlo,MC)指用完整轨迹回报估计价值的 RL 方法;后文沿用 MC。
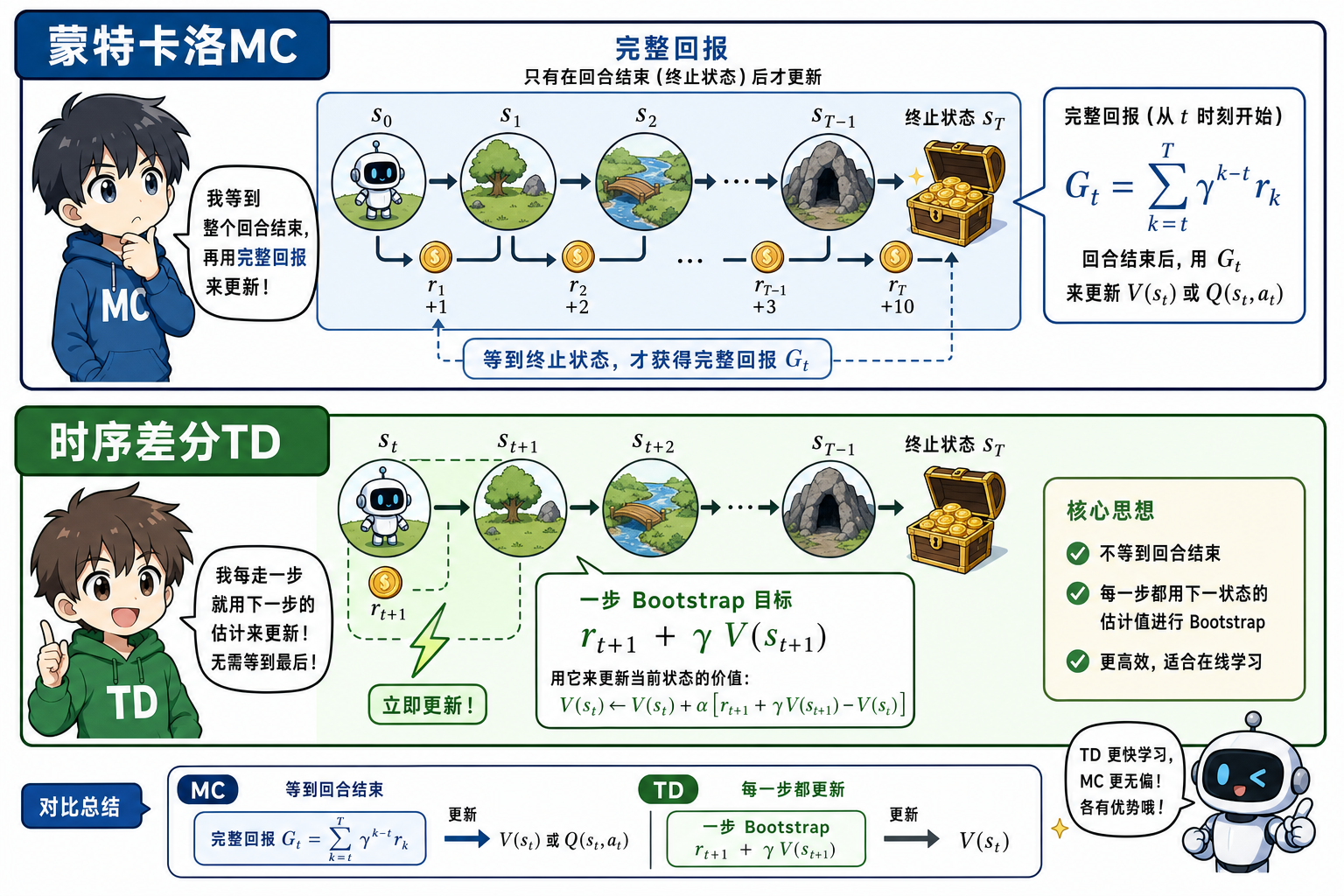
一、MC vs TD(概览)
| 蒙特卡洛 MC | 时序差分 TD | |
|---|---|---|
| 目标 | 完整 episode 回报 $G_t$ | $R_{t+1} + \gamma V(S_{t+1})$ 等 |
| 更新时机 | episode 结束后 | 每步即可 |
| 偏差 | 无偏(对 $V^\pi$) | 有偏(依赖 $V$ 估计) |
| 方差 | 高 | 较低 |
| 适用 | episode 短、终止明确 | 连续任务、长 episode |
TD 详解见专篇 RL-03-05-算法-时序差分。
二、回报与 MC 预测
从 $t$ 时刻起的回报:
$$
G_t = R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + \cdots
$$
MC 预测:对策略 $\pi$,用多次 episode 中访问 $s$ 后的 $G_t$ 样本平均估计 $V^\pi(s)$。
三、首次访问 vs 每次访问
| 变体 | 规则 |
|---|---|
| First-Visit MC | 每个 episode 中,$s$ 首次出现后的 $G_t$ 计入平均 |
| Every-Visit MC | $s$ 每次出现后的 $G_t$ 都计入 |
两者在适当条件下均收敛到 $V^\pi$;First-Visit 更常用。
更新(增量形式):
$$
V(S_t) \leftarrow V(S_t) + \alpha \left( G_t - V(S_t) \right)
$$
四、MC 估计 $Q^\pi(s,a)$
对 $(s,a)$ 首次访问后的回报取平均,用于 MC 控制:
- 策略评估:MC 估 $Q^\pi$
- 策略改进:$\pi(s) = \arg\max_a Q(s,a)$(需 $\varepsilon$-soft 保证探索)
与 动态规划 的策略迭代结构相同,但用采样回报替代 Bellman 期望。
五、MC 控制(GLIE)
广义迭代探索(Greedy in the Limit with Infinite Exploration,GLIE):探索率渐近趋于 0,但每 $(s,a)$ 仍被无限次访问。
常用 $\varepsilon$-soft 策略改进 + MC 评估,收敛到最优策略(表格、适当条件)。
六、MC 的优缺点
| 优点 | 缺点 |
|---|---|
| 无 Bootstrap 偏差 | 必须等 episode 结束 |
| 概念简单 | 高方差 |
| 适用于 episodic 任务 | 不适合连续、非 episodic 任务 |
REINFORCE 策略梯度可看作用 $G_t$ 的 MC 策略梯度特例,见 Policy Gradient。
七、算法族关系
1 | 动态规划(已知 P, R) |
八、选型建议
| 情况 | 推荐 |
|---|---|
| 短 episode、要无偏 | MC |
| 在线、每步更新 | TD(0) |
| 表格控制、Off-Policy | Q-Learning |
| 深度 RL | n-step return、GAE(PPO 侧) |
九、小结
- MC 用完整 $G_t$,无 Bootstrap;TD 用一步目标,可每步学。
- MC 控制 = MC 评估 + 贪心改进 + 持续探索。
- 下一篇:时序差分 · 控制:Q-Learning