StripedHyena 是由 Together AI 与学术合作者推动的一类深度信号处理(deep signal processing)混合架构:在解码器式语言模型中,在旋转位置编码(Rotary Position Embedding,RoPE)之上叠加分组查询注意力(Grouped-Query Attention,GQA),并与按 **Hyena 层级(Hyena Hierarchy)论文思路组织的门控隐式卷积(gated implicit convolutions)**按层配方交替堆叠,使「大范围混合」主要由卷积侧承担,「精确模式召回」由注意力侧补强,从而在短上下文与长上下文任务上同时贴近强开源 Transformer 基线,并在训练与自回归推理上获得更优的渐近行为与工程表现。
段末注释:RoPE 用旋转矩阵编码相对位置;GQA 让多组查询头共享少量 KV 头以省缓存与访存;Hyena 指多阶门控长卷积类 mixer,常以 FFT 或递推实现亚二次复杂度;Transformer 这里指以自注意力为主干的解码器栈。
1. 动机:在 Transformer 之外重排计算
纯 Transformer 解码器以自注意力(Self-Attention)为序列混合核心,其代价随上下文长度呈超线性增长(预填充与 KV 缓存(Key-Value Cache,KV Cache)显存压力尤为突出)。**Hyena 层级(Hyena Hierarchy)**等工作表明:用门控卷积与状态空间模型(State-Space Model,SSM)等算子承担大部分「全局混合」,有望在长序列上接近线性扩展;但完全去掉注意力又会在某些需要强「联想回忆(associative recall)」的模式上吃亏。
段末注释:SSM 这里指可用递推/卷积等价实现的线性时不变或门控动态系统,用于把长卷积写成常数状态更新以解码。
StripedHyena 的设计哲学是混合化(hybridization):在同一计算预算下,异构层(注意力、门控 MLP、门控卷积)的组合往往优于同质堆叠;再通过**算力最优扩展(compute-optimal scaling)**协议调节各算子比例与排布,得到改进的扩展律(相对 Chinchilla 类 Transformer 基线)。
插图约定:下文插入图为科普动漫风、偏平涂的矢量示意(非官方架构原图),画面上中文与关键词尽量采用手写体/马克笔体标注,便于建立直觉;精确拓扑仍以论文、README 与配置为准。配图位于与本文同名的资源目录中;站点已开启 post_asset_folder 并使用 hexo-asset-image,正文里图链只写文件名(如 fig-stripedhyena-01-overall.png),由构建阶段拼到文章永久链接路径。若在编辑器里 Markdown 预览不显示图,属相对路径与 Hexo 处理差异,以 hexo server 或部署后的页面为准。
2. 整体架构鸟瞰
StripedHyena 可理解为**仅解码器(decoder-only)**堆栈:词元嵌入与位置/旋转编码后,进入多层「Hyena 块」与「注意力块」的交错组合;每层仍配合前馈 MLP 与残差、归一化(具体实现依赖官方配置与 flash_attn 等内核)。与标准 GPT 式堆栈的差异在于:序列混合子层在注意力与 Hyena 门控卷积之间分工,而非清一色自注意力。
下图给出逻辑模块级鸟瞰(层内细节见后文)。
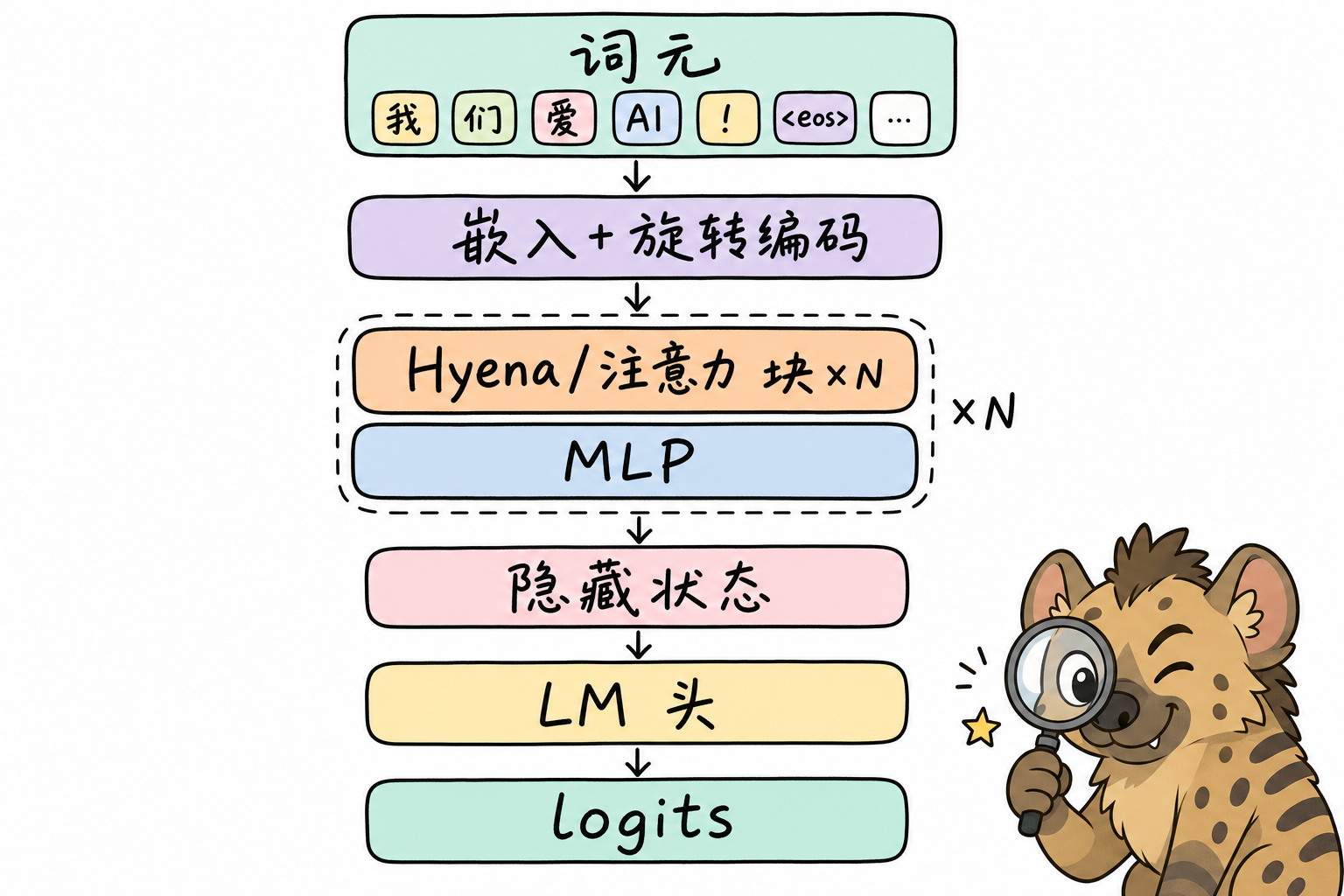
读图要点:矩形「块」在实现中对应配置文件里的层类型与顺序;Hyena 块负责大尺度上下文混合的主要 FLOPs,注意力块补充稀疏、可解释的「查表式」关联能力。
3. 两类序列混合子层的分工(逻辑示意图)
官方 README 与博客强调:Hyena 层承担序列处理的主体计算,注意力层补充定向模式召回。下图从信息流与职责角度抽象两种子层(非某一固定 checkpoint 的精确拓扑,便于建立心智模型)。

直觉:Hyena 路径像可学习的长卷积滤波器组,在频域/状态域高效扫过整段上下文;注意力路径像内容寻址的稀疏检索,对少量关键依赖更敏感。二者交替使模型在「平滑全局混合」与「尖锐局部对齐」之间取得折中。
4. Hyena 算子在 StripedHyena 中的角色(简要)
Hyena 算子族(见论文 Hyena Hierarchy)通过门控与多阶卷积结构构造深层卷积网络式的序列 mixer,可用 FFT 卷积等形式实现亚二次甚至近线性复杂度的长程依赖。StripedHyena 并不重新发明 Hyena,而是把它作为可扩展的主力 mixer,与旋转位置编码(Rotary Position Embedding,RoPE)上的分组注意力协同。
段末注释:RoPE 将位置信息编码为 Q/K 的旋转变换,利于外推与相对位置归纳偏置。
若需 Hyena 数学细节与历史脉络,可与同目录下的 Hyena 主题笔记对照阅读:5003.大模型-基础架构-hyena鬣狗.md。
5. 信号处理视角:FIR、IIR 与推理缓存
Together 博客从经典信号处理借用了对卷积的两种等价视角,用以解释 StripedHyena 推理缓存可小于同规模 GQA Transformer 的原因:
| 视角 | 含义(直觉) | 与推理的关系 |
|---|---|---|
| **有限脉冲响应(Finite Impulse Response,FIR)**卷积 | 有限长滤波器;缓存随已见上下文增长,类比滑动窗口式状态 | 类似「段式」或有限历史的卷积缓存 |
| **无限脉冲响应(Infinite Impulse Response,IIR)**形式 | 可用固定大小状态递推更新 | 解码步只更新常数维状态,利于连续批处理与投机解码 |
段末注释:FIR/IIR 是线性系统两种参数化;实现上可在训练用 FFT 卷积、生成用递推之间切换。
逻辑示意图:预填充(prefill)与自回归解码
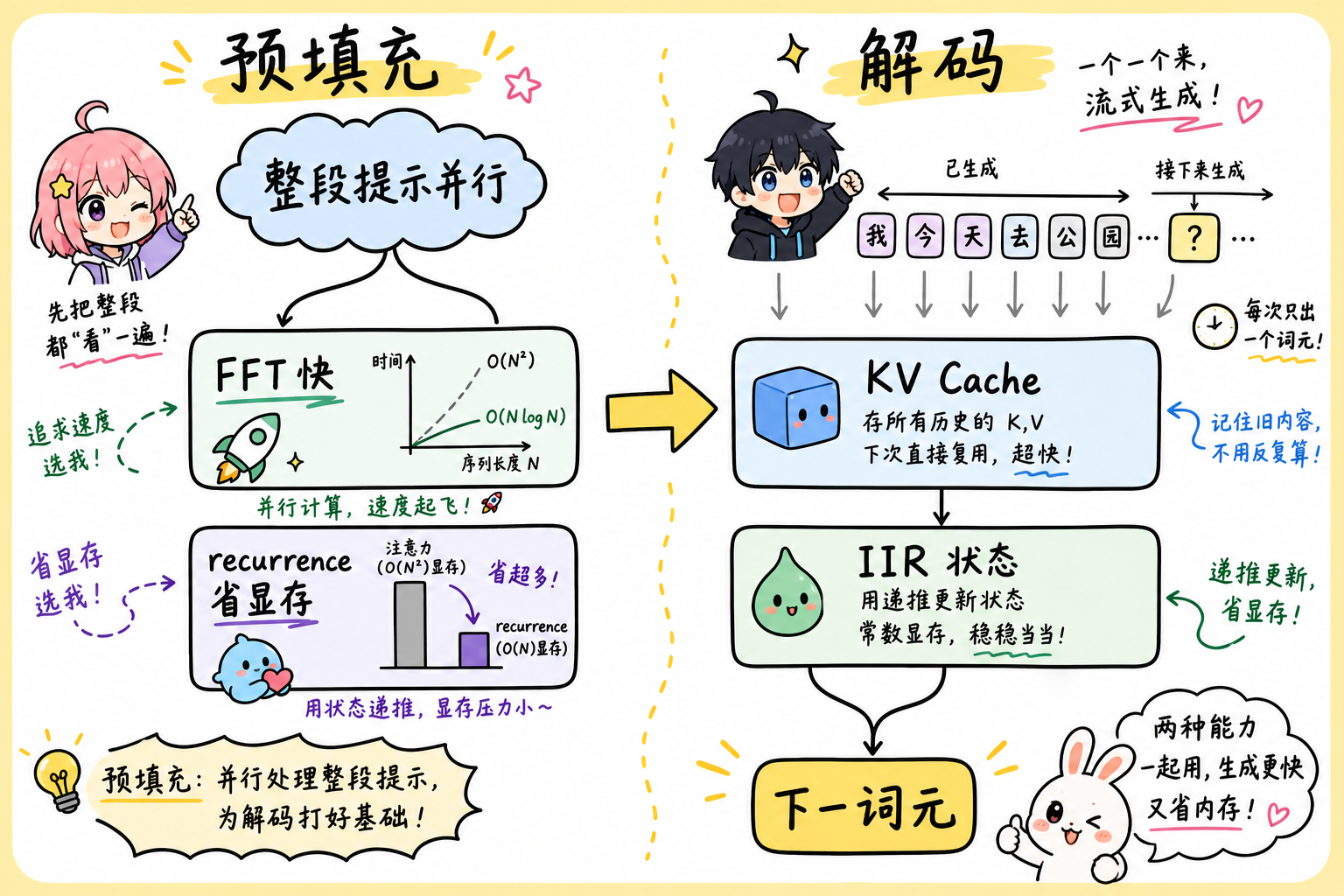
官方独立实现中,prefill_style: fft 与 prefill_style: recurrence 对应上述权衡;极长提示可改用 recurrence 降低峰值显存。生成脚本中 --cached_generation 等选项则与缓存形态相关,需在目标 GPU 上实测。
6. 训练与扩展:为何长上下文更划算
根据 Together 公开博文与 README 的归纳(具体倍数依赖批次、内核版本与基线配置):
- 长序列训练/微调:相对基于 FlashAttention v2 与定制内核优化的 7B 级 Transformer 基线,在 32k、64k、128k 等长度上,StripedHyena 可出现 10%~100%+ 量级的端到端加速,131k 附近微调可报告 >3× 级别优势(请以复现实验为准)。
- 扩展律:在算力最优协议下,注意力 + 门控卷积 + MLP 的混合配方可改善「每 FLOP 带来的损失下降」相对纯 Transformer++ 类结构的表现。
- 模型嫁接(grafting):训练过程中可替换或嫁接子架构组件(例如 Transformer 与 Hyena 部件的组合),便于探索异构堆栈而不必从零固定拓扑。
7. 公开模型与生态
| 模型 | 角色 | 备注 |
|---|---|---|
| StripedHyena-Hessian-7B | 基座 | 长文摘要等 ZeroScrolls 类任务上可与 Mistral 7B 等对照 |
| StripedHyena-Nous-7B | 对话 | 与 Nous Research 合作;指令格式见 HuggingFace 说明 |
| Evo-1-7B | 基因组基础模型 | 字节级核苷酸序列;展示架构在生物序列上的近线性扩展 |
开源实现与权重:
- 代码仓库:togethercomputer/stripedhyena
- 博文:StripedHyena-7B 发布说明
- 可选加速:FlashFFTConv 等自定义卷积内核(README 标明可选)
最小依赖提示:独立仓库需 requirements.txt 与 flash_attn 中的旋转与归一化内核;混合精度训练时注意 README 对 poles / residues 保持 float32 的提醒,以免数值不稳定。
8. 与其他工作的关系(一张概念地图)
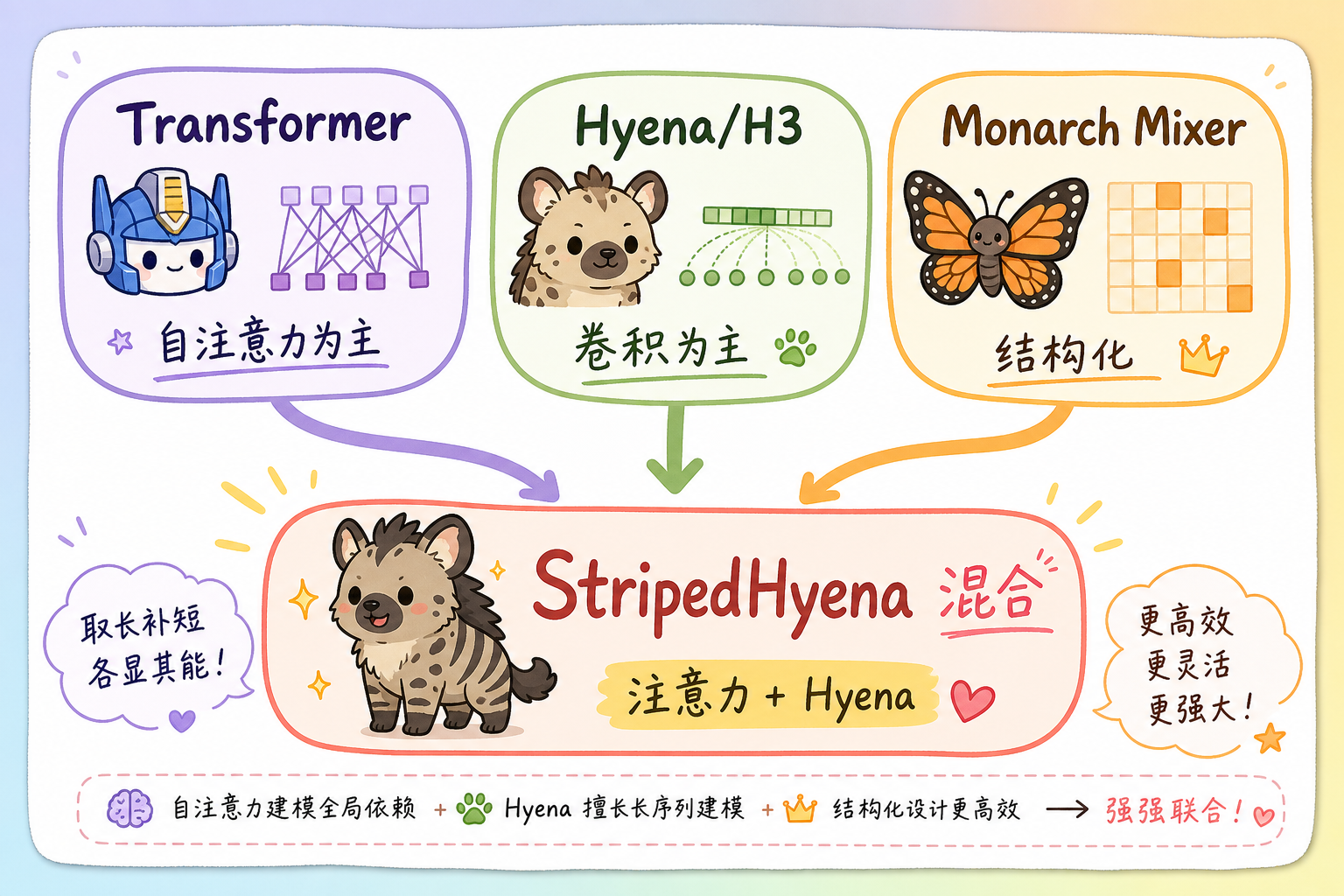
StripedHyena 处于 「保留注意力强项 + 用 Hyena 卷积扛长上下文主负载」 的交汇点;后续工作若继续调参混合比例、层序与内核,仍可能进一步推高同样算力下的质量或同样质量下的吞吐。
9. 小结
- 是什么:面向语言与序列数据的混合解码器,核心为 旋转分组注意力 + Hyena 门控卷积,强调层类专业化分工与算力最优混合比例。
- 为何重要:在开源生态中较早展示「非纯 Transformer 仍可在短/长上下文评测上与强基线竞争」,并带来长序列训练与推理侧的可观工程收益。
- 怎么用:优先阅读官方 README 的配置项(预填充风格、缓存生成、精度);生产环境需结合 flash_attn 版本与 GPU 架构做基准测试。