三维点云、分子构象与蛋白质骨架都生活在三维欧氏空间里:我们对体系做平移与旋转(合称三维特殊欧氏群(three-dimensional special Euclidean group,SE(3))中的刚体变换(rigid transform))时,物理规律不应改变,但笛卡尔坐标会整体变掉。若网络把坐标当普通特征随意混合,学到的表示往往依赖任意坐标系选取,泛化差、数据效率低。SE(3)-等变图神经网络(SE(3)-Equivariant Graph Neural Network,下文简称 SE(3)-等变 GNN)把「坐标如何变、特征如何跟著变」写进网络结构,使模型在图消息传递(graph message passing)中自然尊重三维几何对称性。
前置阅读:图神经网络:原理、算法与分子建模入门(消息传递、GCN/GAT、图级读出)。本文在其基础上梳理 SE(3) 对称性、等变层与工程使用场景。
段末注释:$\mathrm{SE}(3)$ 为三维旋转与平移组成的李群;刚体变换保持点间距离与角度;GNN 在图结构数据上通过邻居聚合学习表示;等变指变换输入时输出按规则同步变换,不变指输出不随变换改变。
1. 为什么需要「等变」而不是只喂距离
把原子或点建成图 $G=(V,E)$:节点携带类型/电荷等标量(scalar)属性,边常由空间距离 $r_{ij}=|\mathbf{x}_i-\mathbf{x}_j|$ 定义。普通 GNN 若只使用距离(distance)或内积(inner product)等旋转不变量,输出对旋转是不变(invariant)的——这适合预测能量、溶解度等标量性质,但不足以表达力、扭矩、局部坐标系方向等向量(vector)或张量(tensor)量。
反之,若直接把 $(x,y,z)$ 与标量特征拼接进多层感知机(Multi-Layer Perceptron,MLP),网络通常不保证旋转后输出只是「转了一下」:同一分子在不同朝向会得到不一致的向量预测,违背物理直觉。
SE(3)-等变 GNN 的目标可以概括为:
| 对象 | 期望行为(直觉) |
|---|---|
| 标量通道(能量、logit) | SE(3)-不变:旋转/平移坐标后数值不变 |
| 向量通道(力、位移、法向) | SE(3)-等变:坐标系旋转 $\mathbf{R}$ 后,向量输出满足 $\mathbf{f}(\mathbf{R}\mathbf{x})=\mathbf{R}\mathbf{f}(\mathbf{x})$(平移对标量/相对量处理需另述) |
| 高阶张量 | 按不可约表示(irreducible representation,irrep)的阶数变换 |
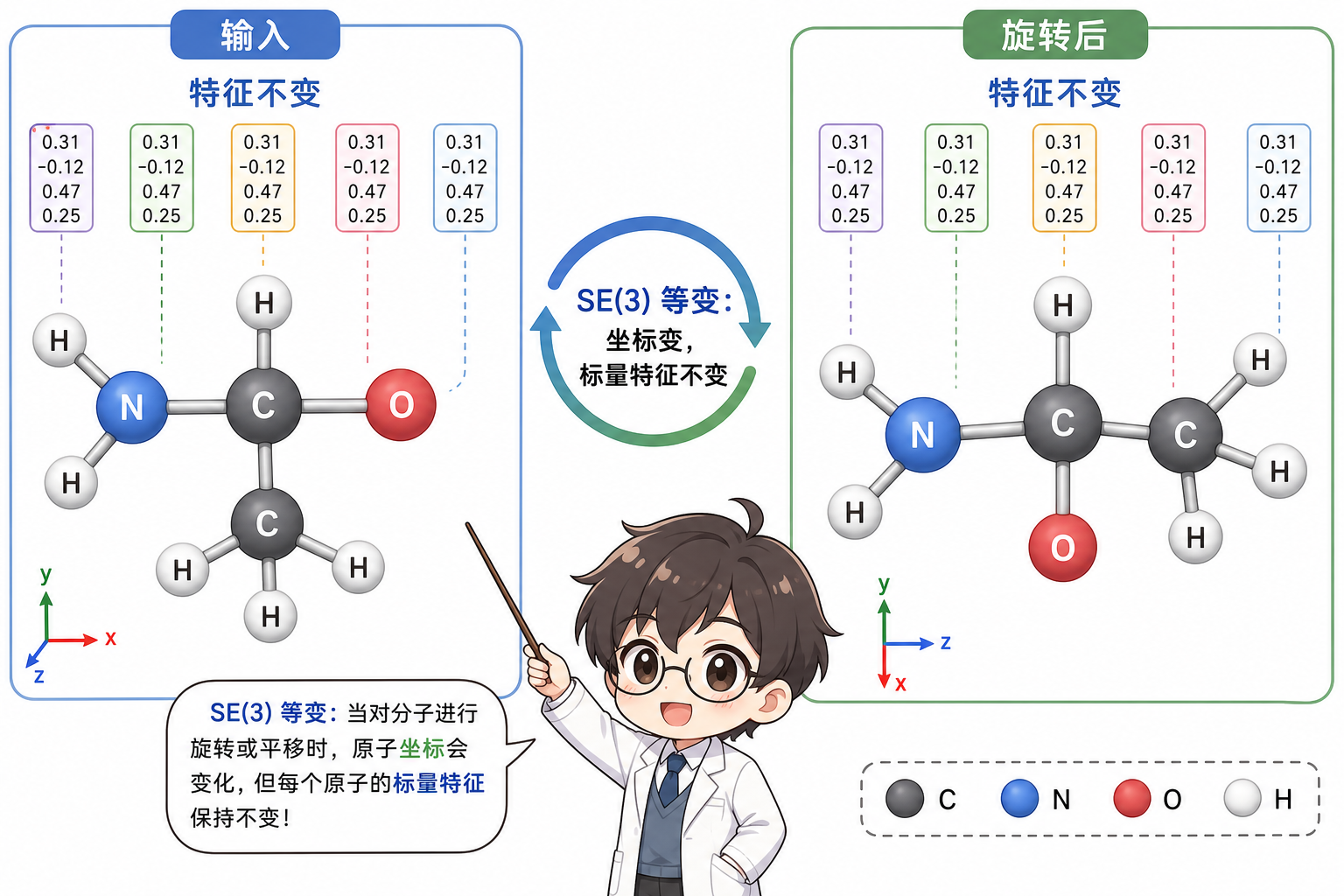
图 1(科普示意):左为原始朝向的分子图;右为整体旋转后,标量节点嵌入保持一致,向量嵌入同步旋转——这是等变性的直观检验。
2. SE(3) 与对称性词汇
2.1 群与刚体变换
$\mathrm{SE}(3)$ 的元素可写为 $(\mathbf{R}, \mathbf{t})$:先旋转 $\mathbf{R}\in \mathrm{SO}(3)$,再平移 $\mathbf{t}\in\mathbb{R}^3$。对点 $\mathbf{x}$ 的作用为 $\mathbf{x}’=\mathbf{R}\mathbf{x}+\mathbf{t}$。
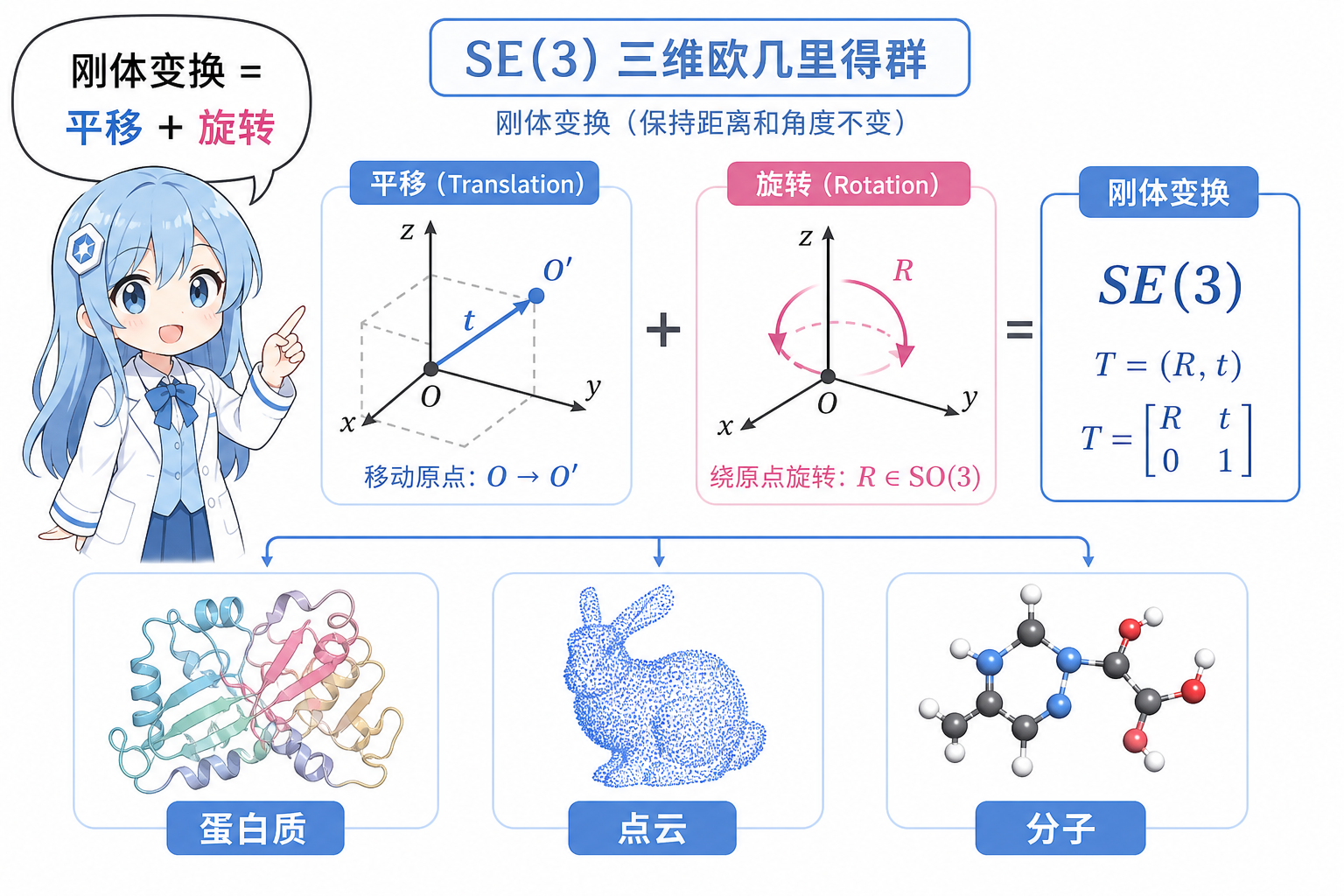
图 2(科普示意):SE(3) 由平移与旋转组合;同一套网络设计可服务分子、点云、机器人学中的三维几何数据。
2.2 等变 vs 不变
设群 $G$ 作用在输入空间 $\mathcal{X}$ 与输出空间 $\mathcal{Y}$ 上。映射 $f:\mathcal{X}\to\mathcal{Y}$ 满足:
- 等变(equivariant):$f(g\cdot x)=g\cdot f(x)$
- 不变(invariant):$f(g\cdot x)=f(x)$
标量能量 $E$ 应对全局平移/旋转不变;原子受力 $\mathbf{F}i=-\nabla{\mathbf{x}_i}E$ 对旋转等变(力是向量)。因此「全模型等变」并不意味每个输出头都等变——常混合不变标量头与等变向量头。
段末注释:$\mathrm{SO}(3)$ 为三维旋转群;李群在这里指带连续参数的变换群,便于用表示论构造层。
3. 三维图上的数据与基线
3.1 图构建
- 节点 $i$:原子类型、残基类型、电荷、杂化等标量;可选初始向量特征(如局部法向)。
- 边:半径图(radius graph,当 $r_{ij} < r_{\mathrm{cut}}$ 时连边)、$k$ 近邻($k$NN)或化学键拓扑;边特征含 $r_{ij}$、$\hat{\mathbf{r}}_{ij}=(\mathbf{x}_i-\mathbf{x}j)/r{ij}$ 等。
- 全局读出:对节点标量做置换不变池化得图级预测。
3.2 只用距离的 GNN(不变但信息受限)
SchNet、早期 DimeNet 等通过径向基展开 $r_{ij}$ 构造消息,天然 $\mathrm{E}(3)$-不变(对反射若只用距离也成立),适合分子性质回归。但若任务需要预测方向性(偶极方向、扭转轴、骨架局部朝向),纯标量通道需要堆叠很多层才能「间接」猜方向,样本效率差。

图 3(科普示意):仅距离的不变 GNN 丢弃朝向;等变 GNN 在消息中保留相对方向,使向量输出与坐标系同步。
4. SE(3)-等变消息传递:算法骨架
等变 GNN 仍遵循 消息–聚合–更新(message–aggregate–update)范式,但消息与更新必须在等变线性层(equivariant linear map)与张量积(tensor product)中完成,不能把 $(x,y,z)$ 当普通标量权重乱乘。
4.1 类型化特征:标量 + 向量 + 高阶
将节点 $i$ 在第 $t$ 层的特征拆成若干 $l$-阶通道($l=0$ 标量,$l=1$ 向量,$l=2$ 二阶张量…),在 $\mathrm{SO}(3)$ 的 Wigner D-矩阵(表示旋转的矩阵)下按阶变换。工程上常用 e3nn 等库管理「不可约表示(irrep)」块。
4.2 相对几何进入消息
对边 $(j\to i)$,定义相对位移 $\mathbf{r}_{ij}=\mathbf{x}_i-\mathbf{x}_j$。等变消息常写作:
$$
\mathbf{m}{ij}^{(t)} = \phi!\left(\mathbf{h}i^{(t)},,\mathbf{h}j^{(t)},,|\mathbf{r}{ij}|,,\frac{\mathbf{r}{ij}}{|\mathbf{r}{ij}|}\right),
$$
其中 $\phi$ 由张量积 + 线性投影 + 门控(gating)实现,保证输出块的阶数组合合法。聚合对邻居 $j\in\mathcal{N}(i)$ 使用等变求和(同阶表示可直接相加)。
4.3 一层的前向(概念流程)
- 边嵌入:用径向基编码 $r_{ij}$;用球谐(spherical harmonics)编码方向 $\hat{\mathbf{r}}_{ij}$,得到不同 $l$ 的基。
- 张量积:节点 irrep 与边球谐做 Clebsch–Gordan 耦合,产生新的 $l’$ 通道。
- 线性 + 归一化:每阶内做可学习的等变线性变换;标量通道可用 层归一化(Layer Normalization)。
- 门控:用标量 MLP 产生权重,调制高阶通道(稳定训练)。
- 聚合与残差:邻居消息等变求和,并与 $\mathbf{h}_i^{(t)}$ 残差连接。
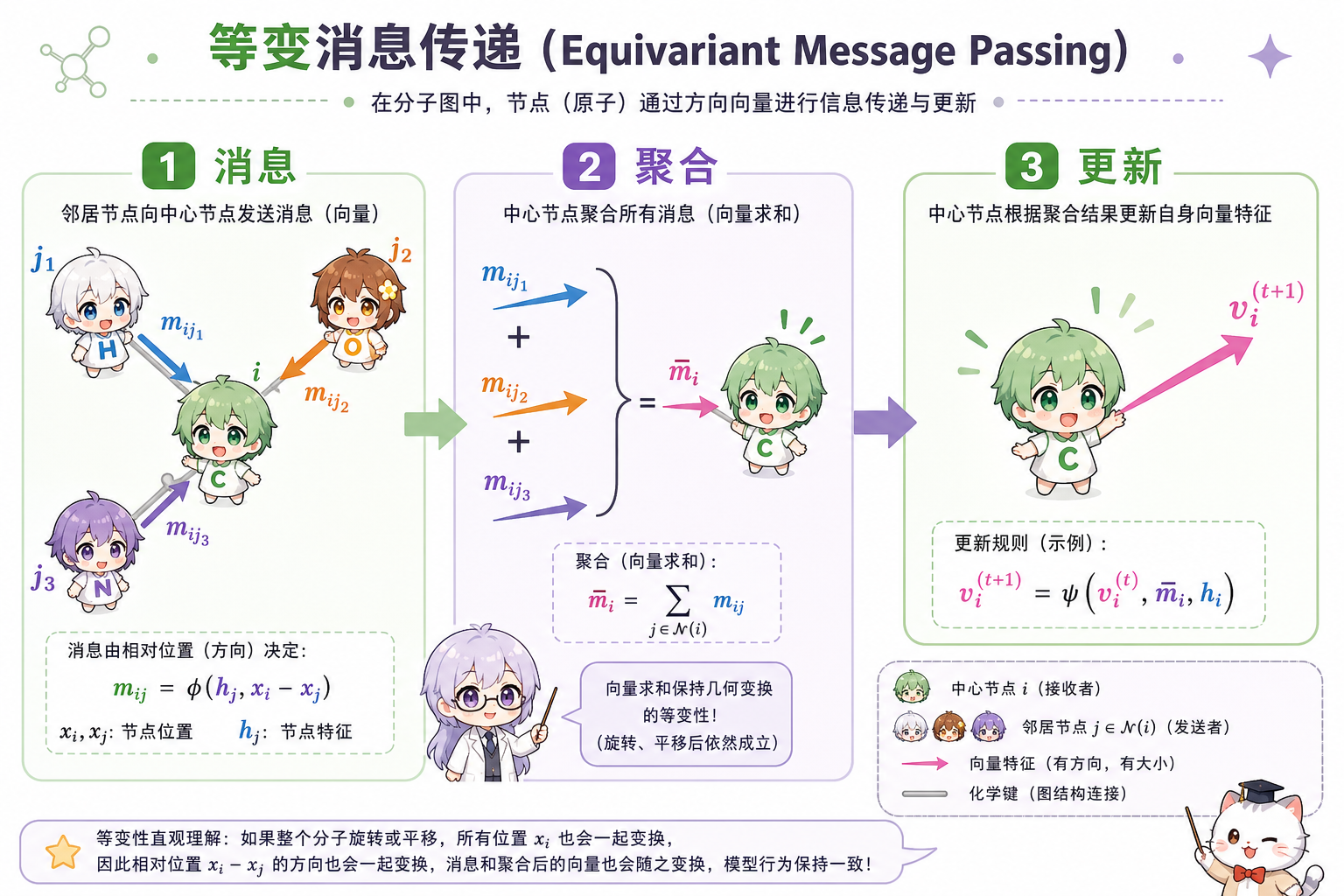
图 4(科普示意):消息依赖相对方向;聚合对等变向量做求和仍等变;更新层保持各阶表示的变换规律。
段末注释:球谐是把方向映射到 $\mathrm{SO}(3)$ 基函数的数学工具;Clebsch–Gordan 系数描述两种角动量表示张量积后如何分解到不同阶。
5. 代表模型族(由简到繁)
5.1 EGNN:轻量 E(n)-等变
E(n)-等变图神经网络(E(n)-Equivariant Graph Neural Networks,EGNN,Satorras et al., 2021)在不显式使用球谐/irrep 的情况下,用距离与单位相对向量构造等变向量更新:
- 标量通道 $s_i$ 用 MLP 更新,输入含 $| \mathbf{x}_i-\mathbf{x}_j|$ 等不变量;
- 坐标/向量通道通过 $\sum_j (\mathbf{x}_i-\mathbf{x}_j),\phi(\cdot)$ 形式更新,保证旋转协变。
优点:实现简单、速度快;缺点:高阶张量表达力弱于 full irrep 方法。
5.2 TFN / SE(3)-Transformer
张量场网络(Tensor Field Networks,TFN)与 SE(3)-Transformer 在边上用球谐展开方向,节点特征按 irrep 分块,通过可学习张量积混合。表达力强,适合高精度力场与各向异性局部环境,但算力与实现复杂度更高。
5.3 GVP-GNN
几何向量感知器(Geometric Vector Perceptrons,GVP)在蛋白质等任务中用「标量 + 向量」两套通道,定义等变线性与不变门控,是 AlphaFold2 结构模块中重要的几何归纳偏置之一(与 Evoformer 等模块配合)。
5.4 NequIP、Allegro 等(学势能与力)
面向分子动力学(molecular dynamics,MD)势函数学习:NequIP 等模型用等变消息传递拟合从头算(ab initio)能量面,并通过自动微分得到等变力;Allegro 等进一步做严格局域(strictly local)与高阶交互,服务大规模 MD。输出能量不变、力等变,与物理一致性对齐。
5.5 与 ProteinMPNN、扩散模型的关系
- ProteinMPNN 等序列设计模型常在固定骨架上用不变或弱几何编码;结构预测/生成(如扩散模型在 $\mathbb{R}^{3N}$ 上去噪)则大量采用 $\mathrm{SE}(3)$-等变或 $\mathrm{E}(3)$-等变去噪网络,使每一步更新不依赖绝对朝向。
- 等变 GNN 提供「局部几何推理」层;扩散/分数匹配(score matching)提供「全局采样」框架,二者常组合为 等变扩散模型(equivariant diffusion model)。
6. 表达能力与局限
- 优势:样本效率更高;外推至新朝向/新位置更稳;力、位移等向量监督直接对齐物理。
- 局限:
- 计算开销:张量积与球谐使常数因子显著大于 EGNN/普通 GNN;
- 反射对称:若只用 $\mathrm{SE}(3)$ 而非 $\mathrm{E}(3)$(含镜像),对手性分子需额外处理;
- 长程相互作用:仍受图截断 $r_{\mathrm{cut}}$ 限制,需多跳消息或静电等特殊项;
- 表达能力上界:与 WL 测试(Weisfeiler–Lehman test)类似,几何 GNN 也有对特定对称图的区分极限,需更高阶交互或子图编码补强。
7. 典型使用场景
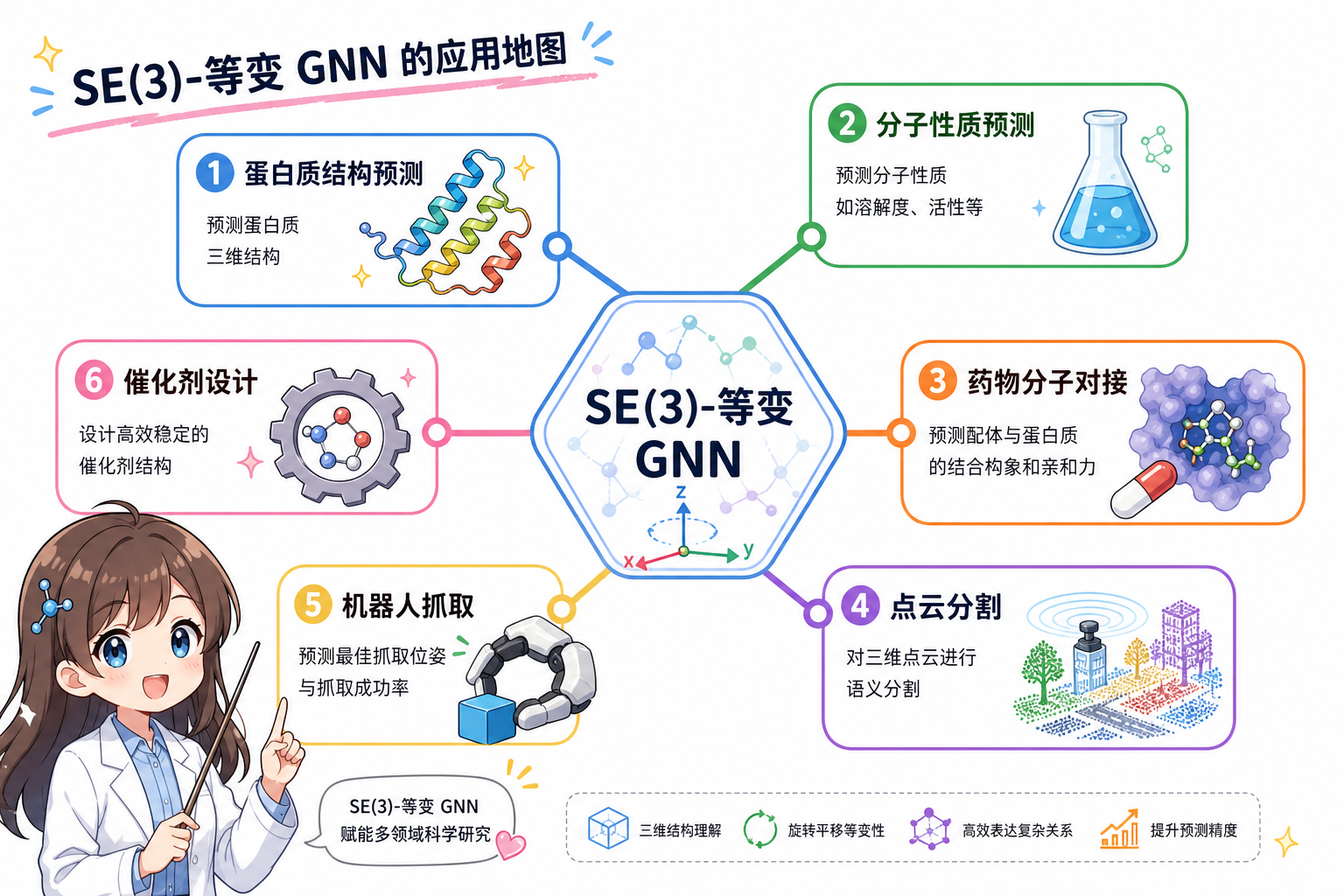
图 5(科普示意):等变 GNN 已渗透多个三维几何学习领域。
| 场景 | 常见输出 | 为何等变 |
|---|---|---|
| 分子性质/反应性 | 能量、能垒、偶极(标量或向量) | 标量不变;偶极为向量需等变头 |
| 力场与 MD | 能量 + per-atom 力 | 力必须是等变向量 |
| 蛋白质结构预测/设计 | 残基取向、局部框架、全原子坐标更新 | 骨架与侧链方向随刚体运动协变 |
| 配体对接/结合姿态 | 配体在口袋内的刚体/扭转 | 相对几何一致则打分一致 |
| 点云分割/检测 | 法向、运动流 | 向量标签随场景旋转 |
| 机器人抓取/操作 | 抓取方向、推力 | 控制量在物体坐标系下协变 |
| 催化位点/材料 | 吸附构型、反应中间体相对取向 | 活性依赖方向性配位 |
7.1 训练与数据注意事项
- 数据增强:随机旋转/平移仍可做,但等变网络下增强更「可选」而非「必须」;过度增强不会破坏不变标量标签。
- 损失设计:标量用 MSE/Huber;向量用 $|\mathbf{y}-\hat{\mathbf{y}}|$ 或在旋转对齐后比较;全原子坐标常用 RMSD(root-mean-square deviation)与 Kabsch 对齐(Kabsch alignment)结合。
- 单位与居中:训练时常去质心(center of mass)或只预测相对位移,减轻平移自由度;预测力时注意单位($\mathrm{kcal,mol^{-1},Å^{-1}}$ 等)。
8. 工程实践速览
| 组件 | 说明 |
|---|---|
| e3nn | PyTorch 的 irrep、张量积、球谐与等变线性层 |
| PyTorch Geometric | 半径图、Data 批处理;与 e3nn 组合常见 |
| NequIP / allegro | 势函数学习流水线与 LAMMPS 接口 |
| MDAnalysis / ASE | 轨迹与结构 I/O |
最小工作流通常是:结构 → 半径图 → 节点/边特征(类型 + $r_{ij}$ + $\hat{\mathbf{r}}_{ij}$)→ 等变消息传递堆叠 → 不变标量读出 / 等变向量读出。
示例(伪代码,说明数据流而非可运行脚本):
1 | # 节点: irrep 分块的 h_i;坐标 x_i |
9. 选型建议(简要)
| 需求 | 倾向选择 |
|---|---|
| 快速原型、坐标去噪、中等规模蛋白 | EGNN、GVP |
| 高精度力场、量子化学数据 | NequIP / Allegro、SE(3)-Transformer |
| 强各向异性、需 $l>1$ 张量 | TFN 类 irrep 网络 |
| 仅需标量性质、数据少 | SchNet 等不变 GNN 仍可能是强基线 |
10. 小结
SE(3)-等变 GNN 把「三维空间中的对称性」从数据增强提升为网络架构约束:标量通道学习不变性质,向量/张量通道以正确的阶数随刚体运动变换。算法上,它在普通 GNN 的消息传递外壳内,用球谐方向编码 + irrep 张量积 + 等变线性/门控实现几何一致的局部推理;应用上,它已成为分子力场、蛋白质几何学习、三维点云与机器人的重要工具链。
进一步阅读可从 EGNN(轻量)、SE(3)-Transformer(表示论完整)、NequIP(势函数)三条线切入;实现上优先熟悉 e3nn 的 irrep API,再对接 PyG 的图批处理。
参考文献与延伸阅读
- Satorras, V. G. et al. E(n) Equivariant Graph Neural Networks. ICML 2021.
- Thomas, N. et al. Tensor Field Networks. NeurIPS 2018.
- Fuchs, F. et al. SE(3)-Transformers: 3D Roto-Translation Equivariant Attention Networks. NeurIPS 2020.
- Jing, B. et al. Learning from Protein Structure with Geometric Vector Perceptrons. ICLR 2021.
- Batzner, S. et al. E(3)-equivariant graph neural networks for data-efficient and accurate interatomic potentials. Nat. Commun. 2022 (NequIP).
- Musaelian, A. et al. Learning local equivariant representations for molecular dynamics. NeurIPS 2023 (Allegro).
- e3nn 文档: https://docs.e3nn.org